
尽管除了日期之外没有什么真正改变,但新的一年让每个人都充满了重新开始的希望。如果您添加一些计划、一些远见的目标和学习路线图,您将获得充满成长的一年的绝佳秘诀。
这篇文章旨在通过为您提供 学习框架、资源和项目想法 帮助您建立一个可靠的作品集,展示数据科学方面的专业知识。
请注意:我根据我在数据科学方面的个人经验准备了这个路线图。这不是最终的学习计划。您可以调整此路线图以更好地适合您感兴趣的任何特定领域或研究领域。另外,这是根据 Python 创建的,因为我个人更喜欢它。
什么是学习路线图?
学习路线图是课程的延伸。它绘制了一个多层次的技能图,其中包含以下详细信息 什么 你想要磨练的技能, 如何 您将衡量每个级别的结果,并且 技巧 进一步掌握每项技能。
我的路线图根据其在现实世界中应用的复杂性和通用性为每个级别分配权重。我还添加了初学者通过练习和项目完成每个级别的估计时间。
这是一个金字塔,按照复杂性和行业应用的顺序描述了高级技能。
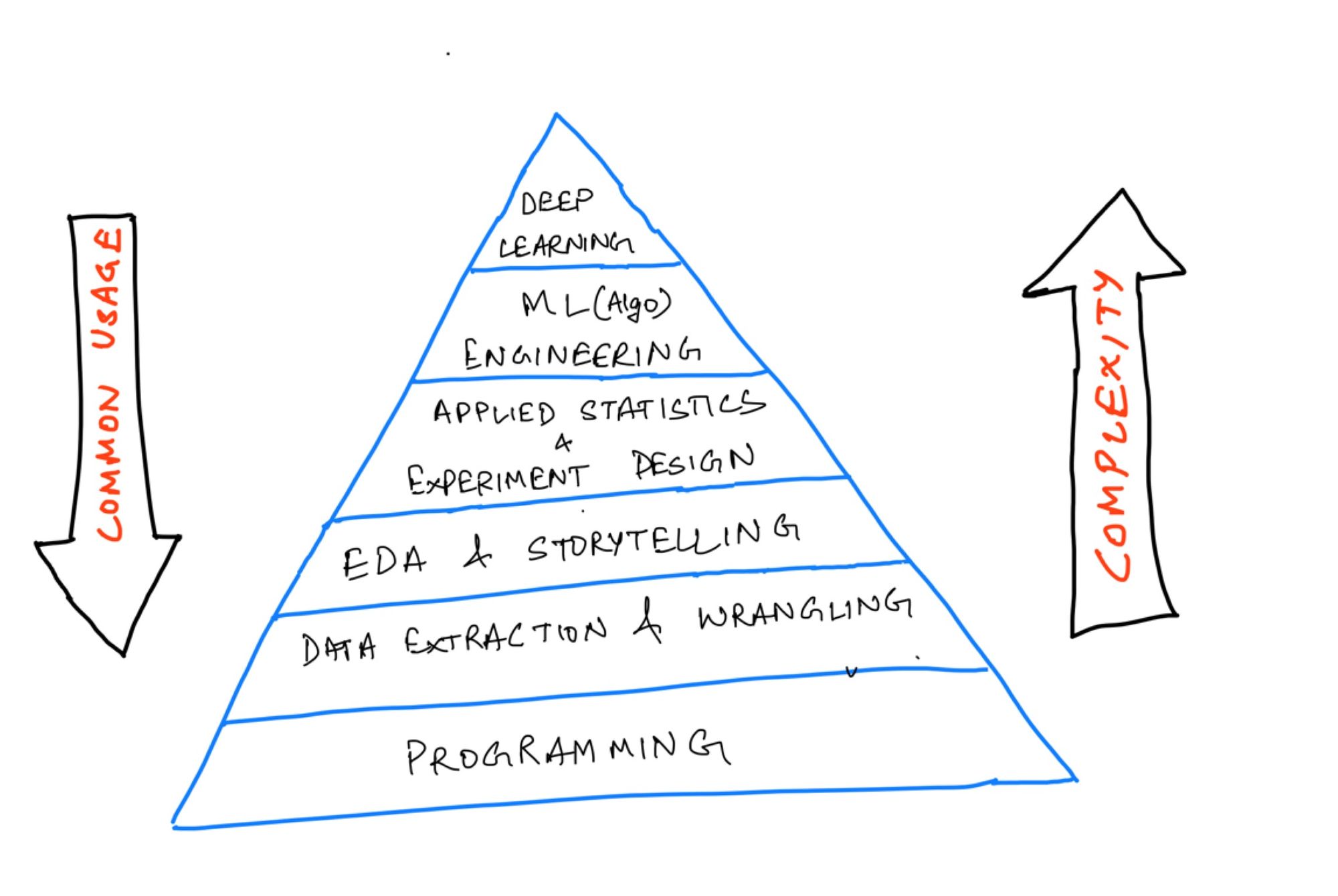
这将标志着我们框架的基础。我们现在必须深入研究每个层次,以通过更具体、可衡量的细节来完成我们的框架。
特异性来自于检查每一层中的关键主题以及掌握这些主题所需的资源。
我们能够衡量通过将学到的主题应用到许多实际项目中所获得的知识。我添加了一些项目想法、门户和平台,您可以使用它们来衡量您的熟练程度。
重要提示:一天一次地学习,每天一个视频/博客/章节。它涵盖的范围很广。不要压倒自己!
让我们从底部开始深入研究每一层。
1. 如何学习编程或软件工程
(预计时间:2-3个月)
首先,确保您拥有良好的编程技能。每个数据科学职位描述都要求具备至少一种语言的编程专业知识。
需要了解的具体编程主题包括:
- 常见数据结构(数据类型、列表、字典、集合、元组)、编写函数、逻辑、控制流、搜索和排序算法、面向对象编程以及使用外部库。
- SQL 脚本:使用联接、聚合和子查询查询数据库
- 舒适地使用终端、Git 中的版本控制以及 GitHub
学习Python的资源:
用于学习 Git 和 GitHub 的资源
学习 SQL 的资源
通过解决大量问题并构建至少 2 个项目来衡量您的专业知识:
- 在这里解决很多问题:HackerRank(适合初学者)和 LeetCode(解决简单或中等水平的问题)
- 从网站/API 端点提取数据 — 尝试编写 Python 脚本,从允许抓取的网页中提取数据 soundcloud.com。 将提取的数据存储到 CSV 文件或 SQL 数据库中。
- 剪刀石头布、旋转纱线、刽子手、掷骰子模拟器、井字棋等游戏。
- 简单的网络应用程序,例如 YouTube 视频下载器、网站拦截器、音乐播放器、抄袭检查器等。
将这些项目部署在 GitHub 页面上,或者只是将代码托管在 GitHub 上,以便您学习使用 Git。
2. 如何了解数据收集和整理(清理)
(预计时间:2个月)
数据科学工作的一个重要部分是围绕寻找可以帮助您解决问题的合适数据。您可以从不同的合法来源收集数据 — 抓取(如果网站允许)、API、数据库和公开可用的存储库。
一旦掌握了数据,分析师通常会发现自己正在清理数据帧、使用多维数组、使用描述性/科学计算以及操作数据帧来聚合数据。
数据很少是干净的和格式化的以供“现实世界”使用。 Pandas 和 NumPy 是您可以使用的两个库,可以将脏数据转换为准备分析的数据。
当您开始轻松地编写 Python 程序时,请随意开始学习有关使用库的课程,例如 熊猫 和 麻木。
了解数据收集和清理的资源:
数据采集项目思路:
3. 如何学习探索性数据分析、商业头脑和讲故事
(预计时间:2-3个月)
下一个要掌握的层次是数据分析和讲故事。从数据中获取见解,然后用简单的术语和可视化方式将其传达给管理层,这是数据分析师的核心职责。
讲故事部分要求您精通数据可视化以及出色的沟通技巧。
需要学习的具体探索性数据分析和讲故事主题包括:
- 探索性数据分析 — 定义问题、处理缺失值、异常值、格式化、过滤、单变量和多变量分析。
- 数据可视化 — 使用 matplotlib、seaborn 和plotly 等库绘制数据。了解如何选择正确的图表来传达数据结果。
- 开发仪表板 —很大一部分分析师仅使用 Excel 或 Power BI 和 Tableau 等专用工具来构建仪表板,以汇总/聚合数据以帮助管理层做出决策。
- 商业头脑:努力提出正确的问题来回答,这些问题实际上针对的是业务指标。练习撰写清晰简洁的报告、博客和演示文稿。
了解有关数据分析的更多信息的资源:
数据分析项目思路
4. 如何学习数据工程
(预计时间:4-5个月)
数据工程通过为大数据驱动公司的研究工程师和科学家提供干净的数据来支撑研发团队。它本身就是一个领域,如果您只想关注问题的统计算法方面,您可能会决定跳过这一部分。
数据工程师的职责包括构建高效的数据架构、简化数据处理和维护大规模数据系统。
工程师使用 Shell (CLI)、SQL 和 Python/Scala 创建 ETL 管道、自动化文件系统任务并优化数据库操作以使其高性能。
另一项关键技能是实施这些数据架构,这需要熟练掌握 AWS、Google Cloud Platform、Microsoft Azure 等云服务提供商。
学习数据工程的资源:
数据工程项目想法/认证,以准备:
5. 如何学习应用统计和数学
(预计时间:4-5个月)
统计方法是数据科学的核心部分。几乎所有数据科学访谈都主要关注描述性和推论性统计。
人们通常在没有清楚地了解解释这些算法工作原理的底层统计和数学方法的情况下开始编写机器学习算法。当然,这不是最好的方法。
应用统计和数学中您应该关注的主题:
- 描述性统计 — 能够总结数据很强大,但并不总是如此。了解位置估计(平均值、中位数、众数、加权统计量、修剪统计量)和描述数据的变异性。
- 推论统计 — 设计假设检验、A/B 检验、定义业务指标、使用置信区间、p 值和 alpha 值分析收集的数据和实验结果。
- 线性代数、单变量和多元微积分 了解机器学习中的损失函数、梯度和优化器。
了解统计和数学的资源:
统计项目思路:
- 解决上述课程中提供的练习,然后尝试浏览一些可以应用这些统计概念的公共数据集。提出诸如“是否有足够的证据可以得出结论,在 0.05 显着性水平下,波士顿产妇的平均年龄超过 25 岁”之类的问题?
- 尝试与你的同伴/小组/班级一起设计和运行小型实验,要求他们与应用程序交互或回答问题。一段时间后获得大量数据后,对收集的数据运行统计方法。这可能很难实现,但应该非常有趣。
- 分析股票价格、加密货币,并围绕平均回报或任何其他指标设计假设。使用临界值确定是否可以拒绝原假设或无法拒绝原假设。
6. 如何学习机器学习和人工智能
(预计时间:4-5个月)
在审视自己并了解上述所有主要概念之后,您现在应该准备好开始使用奇特的 ML 算法了。
学习主要分为三种类型:
- 监督学习 — 包括回归和分类问题。研究简单线性回归、多元回归、多项式回归、朴素贝叶斯、逻辑回归、KNN、树模型、集成模型。了解评估指标。
- 无监督学习 — 聚类和降维是无监督学习的两个广泛使用的应用。深入研究 PCA、K 均值聚类、层次聚类和高斯混合。
- 强化学习 (can skip*) — helps you build self-rewarding systems. Learn to optimize rewards, using the TF-Agents library, creating Deep Q-networks, and so on.
The majority of the ML projects need you to master a number of tasks that I’ve explained in this blog.
Resources to learn about Machine Learning:
For those of you who are interested in further diving into deep learning, you can start off by completing this specialization offered by deeplearning.ai and the Hands-ON book. This is not as important from a data science perspective unless you are planning to solve a computer vision or NLP problem.
Deep learning deserves a dedicated roadmap of its own. I’ll create that with all the fundamental concepts soon.
Track your learning progress
I’ve also created a learning tracker for you on Notion. You can customize it to your needs and use it to track your progress, have easy access to all the resources and your projects.
Also, here's the video version of this blog:
This is just a high-level overview of the wide spectrum of data science. You might want to deep dive into each of these topics and create a low-level concept-based plan for each of the categories.
If this tutorial was helpful, you should check out my data science and machine learning courses on Wiplane Academy. They are comprehensive yet compact and helps you build a solid foundation of work to showcase.





