
自从人工智能、机器学习和深度学习被引入以来,世界已经发生了变化,并且在未来几年还将继续如此。在这个 2023 年机器学习面试问题 博客中,我收集了面试官最常问的问题。这些问题是在咨询机器学习Python认证培训专家后收集的。
如果您最近参加过任何机器学习面试,请将这些面试问题粘贴到评论部分,我们会尽快回答。如果您在机器学习面试中可能遇到任何疑问,也可以在下面发表评论。
您可以浏览机器学习面试问题和答案的录音,我们的讲师通过示例详细解释了这些主题,这将帮助您更好地理解这个概念。
在这篇关于机器学习面试问题的博客中,我将讨论您在面试中提出的最重要的机器学习相关问题。因此,为了让您更好地理解,我将此博客分为以下 3 个部分:
机器学习核心面试问题
Q1.机器学习有哪些不同类型?
| 监督学习 | 无监督学习 | 强化学习 | |
定义 | 机器通过使用标记数据进行学习 | 机器在没有任何指导的情况下根据标记数据进行训练 | 代理通过产生动作并发现错误或奖励来与其环境交互 |
问题类型 | 回归或分类 | 关联或分类 | 基于奖励 |
数据类型 | 标记数据 | 未标记数据 | 没有预定义数据 |
训练 | 外部监督 | 无监督 | 无监督 |
方法 | 将标记的输入映射到已知的输出 | 理解模式并发现输出 | 遵循试错法 |
流行算法 | 线性回归、Logistic回归、SVM、KNN等 | K-means、C-means 等 | Q-Learning、SARSA 等 |
机器学习的类型 – 机器学习面试问题 – Edureka
机器学习有以下三种方式:
- 监督学习
- 无监督学习
- 强化学习
监督学习:
- 就像在老师的指导下学习一样
- 训练数据集就像一个老师,用来训练机器
- 模型在给定新数据时开始做出决策之前,会在预定义的数据集上进行训练
无监督学习:
- 这就像没有老师的学习一样。
- 模型通过观察进行学习并发现数据中的结构。
- 给模型一个数据集,并通过创建集群来自动查找该数据集中的模式和关系。
强化学习:
- 就像被困在一座孤岛上,你必须独自探索环境,学习如何生活和适应生活条件。
- 模型通过命中和尝试方法进行学习
- 它根据对其执行的每个动作给予的奖励或惩罚来学习
Q2。你会如何向一个上学的孩子解释机器学习?
- 假设你的朋友邀请你参加他的聚会,在那里你遇到了完全陌生的人。由于你对他们一无所知,你会在心里根据性别、年龄组、着装等对他们进行分类。
- 在这种情况下,陌生人代表未标记的数据,对未标记的数据点进行分类的过程只不过是无监督学习。
- 由于您没有使用任何关于人的先验知识并对他们进行动态分类,因此这成为一个无监督学习问题。
Q3。深度学习与机器学习有何不同?
| 深度学习 | 机器学习 |
 深度学习是机器学习的一种形式,受到人脑结构的启发,在特征检测方面特别有效。 深度学习是机器学习的一种形式,受到人脑结构的启发,在特征检测方面特别有效。 |  机器学习是关于解析数据、从数据中学习,然后应用所学知识做出明智决策的算法。 |
深度学习与机器学习 – 机器学习面试问题 – Edureka
Q4。解释分类和回归

分类与回归 – 机器学习面试问题 – Edureka
Q5.你如何理解选择偏差?
- 这是一种统计误差,会导致实验采样部分出现偏差。
- 该错误导致一个采样组比实验中包含的其他组更频繁地被选择。
- 如果选择偏差未被识别,选择偏差可能会产生不准确的结论。
Q6.你对精确率和召回率有何理解?
让我用一个类比来解释一下:
- 想象一下,过去 10 年里,你的女朋友每年都给你一个生日惊喜。有一天,你的女朋友问你:“亲爱的,你还记得我给你的所有生日惊喜吗?”
- 为了和你的女朋友保持良好的关系,你需要回忆起你记忆中的所有 10 件事。所以, 记起 是您能够正确回忆起的事件数与事件总数的比率。
- 如果你能正确回忆起所有 10 个事件,那么你的回忆率为 1.0 (100%);如果你能正确回忆起 7 个事件,那么你的回忆率为 0.7 (70%)
但是,您的某些答案可能是错误的。
- 例如,假设您进行了 15 个猜测,其中 10 个正确,5 个错误。这意味着你可以回忆起所有事件,但不那么准确
- 所以, 精确 是您可以正确回忆的事件数量与您可以回忆的事件总数(正确回忆和错误回忆的混合)的比率。
- 从上面的例子(10个真实事件,15个答案:10个正确,5个错误),你得到了100%的召回率,但你的精确率只有66.67% (10 / 15)
Q7.用一个简单的例子解释假阴性、假阳性、真阴性和真阳性。
让我们考虑一下火灾紧急情况的情况:
- 真阳性: 如果发生火灾时警报响起。
火灾是肯定的,系统做出的预测是正确的。 - 假阳性: 如果警报响起,并且没有火灾。
系统预测火灾是肯定的,这是一个错误的预测,因此预测是错误的。 - 假阴性: 如果警报没有响起但发生了火灾。
系统预测火灾结果为负值,但由于发生火灾,该结果是错误的。 - 真阴性: 如果警报没有响起,则没有发生火灾。
火灾是负面的,这个预测是正确的。
Q8.什么是混淆矩阵?
混淆矩阵或误差矩阵是用于总结分类算法性能的表。
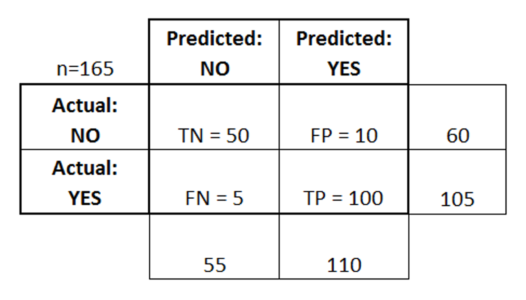
混淆矩阵 – 机器学习面试问题 – Edureka
考虑上表,其中:
- TN = 真阴性
- TP = 真阳性
- FN = 假阴性
- FP = 误报
Q9.归纳学习和演绎学习有什么区别?
- 归纳学习是利用观察得出结论的过程
- 演绎学习是使用结论形成观察的过程
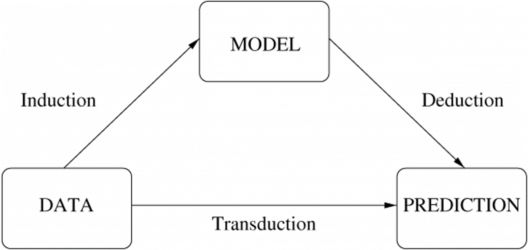
归纳与演绎学习 – 机器学习面试问题 – Edureka
Q10. KNN 与 K 均值聚类有何不同?

K-means 与 KNN – 机器学习面试问题 – Edureka
Q11.什么是ROC曲线?它代表什么?
受试者工作特征曲线(或 ROC 曲线)是诊断测试评估的基本工具,是诊断测试不同可能截止点的真阳性率(灵敏度)与假阳性率(特异性)的关系图。
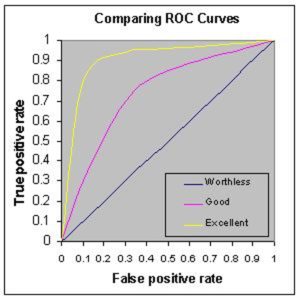
ROC – 机器学习面试问题 – Edureka
- 它显示了敏感性和特异性之间的权衡(敏感性的任何增加都将伴随着特异性的降低)。
- 曲线越接近 ROC 空间的左侧边界和顶部边界,测试就越准确。
- 曲线越接近 ROC 空间的 45 度对角线,测试的准确性就越低。
- 切线在分界点处的斜率给出了该检验值的似然比 (LR)。
- 曲线下面积是测试精度的衡量标准。
Q12. I 类错误和 II 类错误有什么区别?

1 类错误与 2 类错误 – 机器学习面试问题 – Edureka
Q13.误报太多好还是漏报太多好?解释。

假阴性与假阳性 – 机器学习面试问题 – Edureka
这取决于问题以及我们试图解决问题的领域。如果您在医学检测领域使用机器学习,那么假阴性的风险非常大,因为当一个人实际上不舒服时,报告不会显示任何健康问题。同样,如果机器学习用于垃圾邮件检测,则误报的风险非常大,因为该算法可能会将重要电子邮件分类为垃圾邮件。
Q14.对您来说哪个更重要——模型准确性还是模型性能?

模型准确性与性能 – 机器学习面试问题 – Edureka
嗯,您必须知道模型准确性只是模型性能的一个子集。模型的准确性和模型的性能成正比,因此模型的性能越好,预测就越准确。
Q15.决策树中的基尼杂质和熵有什么区别?
- 基尼杂质和熵是用于决定如何分割决策树的指标。
- 基尼测量是如果根据分支中的分布随机选择标签,则随机样本被正确分类的概率。
- 熵是计算信息缺乏程度的度量。您可以通过拆分来计算信息增益(熵差)。该措施有助于减少输出标签的不确定性。
Q16.熵和信息增益有什么区别?
- 熵是数据混乱程度的指标。当您接近叶节点时,它会减小。
- 信息增益基于数据集在属性上分割后熵的减少。当您接近叶节点时,它会不断增加。
Q17.什么是过拟合?如何确保模型不会过度拟合?
当模型对训练数据的研究达到对模型在新数据上的性能产生负面影响的程度时,就会发生过度拟合。
这意味着训练数据中的干扰被模型记录并作为概念学习。但这里的问题是,这些概念不适用于测试数据,并对模型对新数据进行分类的能力产生负面影响,从而降低了测试数据的准确性。
避免过拟合的三种主要方法:
- 收集更多数据,以便可以使用不同的样本来训练模型。
- 使用集成方法,例如随机森林。它基于 bagging 的思想,通过组合数据集不同样本上的多个决策树的结果来减少预测的变化。
- 选择正确的算法。
Q18.解释机器学习中的集成学习技术。
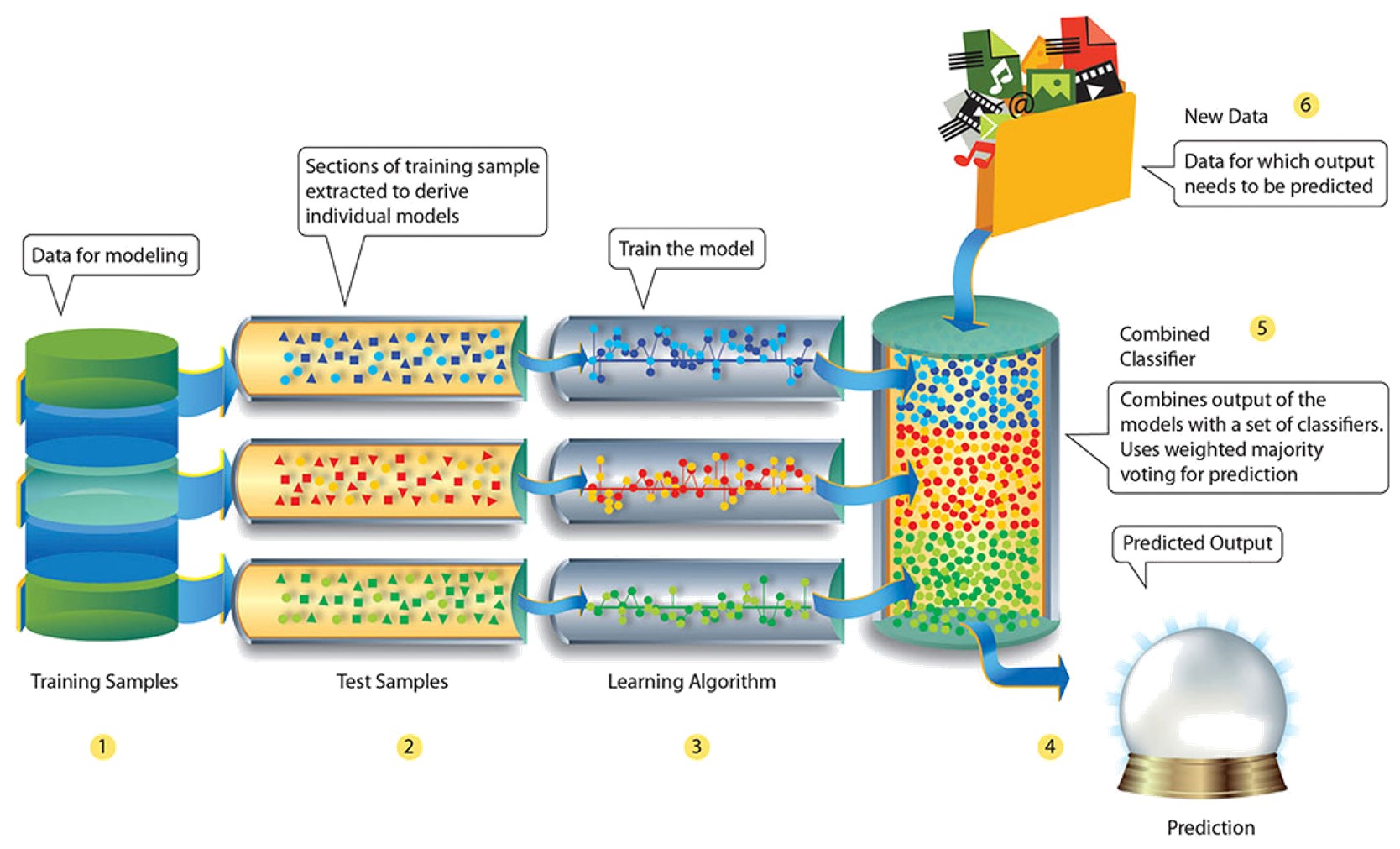
集成学习 – 机器学习面试问题 – Edureka
集成学习是一种用于创建多个机器学习模型的技术,然后将这些模型组合起来产生更准确的结果。通用机器学习模型是使用整个训练数据集构建的。然而,在集成学习中,训练数据集被分成多个子集,其中每个子集用于构建单独的模型。训练模型后,将它们组合起来以减少输出方差的方式预测结果。
Q19.机器学习中的 bagging 和 boosting 是什么?

Bagging & Boosting – 机器学习面试问题 – Edureka
Q20。您将如何筛选异常值?如果发现异常值该怎么办?
可以采用以下方法筛选异常值:
- 箱形图: 箱线图表示数据的分布及其变异性。箱线图包含上四分位数和下四分位数,因此箱线基本上跨越了四分位数范围 (IQR)。使用箱线图的主要原因之一是检测数据中的异常值。由于箱线图跨越 IQR,因此它会检测位于该范围之外的数据点。这些数据点只不过是异常值。
- 概率和统计模型: 正态分布和指数分布等统计模型可用于检测数据点分布的任何变化。如果发现任何数据点超出分布范围,则将其呈现为异常值。
- 线性模型: 可以训练逻辑回归等线性模型来标记异常值。通过这种方式,模型会拾取它看到的下一个异常值。
- 基于邻近度的模型: 这种模型的一个例子是 K-means 聚类模型,其中数据点根据相似度或距离等特征形成多个或“k”个聚类。由于相似的数据点形成簇,因此异常值也形成自己的簇。通过这种方式,基于邻近度的模型可以轻松帮助检测异常值。
您如何处理这些异常值?
- 如果您的数据集庞大且丰富,那么您可能会冒丢弃异常值的风险。
- 但是,如果您的数据集很小,那么您可以通过设置阈值百分位来限制异常值。例如,高于 95% 的数据点可用于限制异常值。
- 最后,基于数据探索阶段,您可以缩小一些规则范围,并根据这些业务规则估算异常值。
Q21.什么是共线性和多重共线性?
- 当多元回归中的两个预测变量(例如 x1 和 x2)具有一定相关性时,就会出现共线性。
- 当两个以上的预测变量(例如 x1、x2 和 x3)相互关联时,就会出现多重共线性。
Q22.你对特征向量和特征值的理解是什么?
- 特征向量: 特征向量是那些即使对其进行线性变换其方向也保持不变的向量。
- 特征值: 特征值是用于特征向量变换的标量。
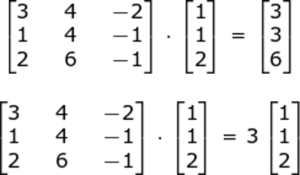
特征值和特征向量 – 机器学习面试问题 – Edureka
在上面的示例中,3 是特征值,乘法问题中的原始向量是特征向量。
方阵 A 的特征向量是一个非零向量 x,因此对于某个数字 λ,我们有以下结果:
轴 = λx,
其中 λ 是特征值
因此,在我们的示例中,λ = 3 且 X = [1 1 2]
Q23.什么是 A/B 测试?
- A/B 是使用两个变量 A 和 B 进行随机实验的统计假设检验。它用于比较使用不同预测变量的两个模型,以检查哪个变量最适合给定的数据样本。
- 考虑这样一个场景,您创建了两个模型(使用不同的预测变量),可用于为电子商务平台推荐产品。
- A/B 测试可用于比较这两个模型,以检查哪一个模型最能向客户推荐产品。

A/B 测试 – 机器学习面试问题 – Edureka
Q24.什么是聚类抽样?
- 这是一个在定义的群体中随机选择具有相似特征的完整群体的过程。
- 聚类样本是概率样本,其中每个采样单元是元素的集合或簇。
- 例如,如果您对一组公司中的经理总数进行聚类,在这种情况下,经理(样本)将代表元素,公司将代表集群。
Q25. 运行二元分类树算法非常容易。但是您知道树如何决定在根节点及其后续子节点处分割哪个变量吗?
- 诸如基尼指数和熵之类的度量可用于决定哪个变量最适合在根节点处分割决策树。
- 我们可以计算基尼系数如下:
使用公式 - 成功和失败概率平方和 (p^2+q^2) 计算子节点的基尼系数。 - 使用该分割的每个节点的加权基尼分数计算分割的基尼系数
- 熵是数据中杂质或随机性的度量(对于二进制类):
![]() 这里 p 和 q 分别是该节点成功和失败的概率。
这里 p 和 q 分别是该节点成功和失败的概率。
要了解有关人工智能和机器学习的更多信息,请阅读人工智能教程。此外,还可以报名参加 NIT Warangal 的 PGP AI 和 ML 课程以变得精通。
Python 机器学习问题
这套机器学习面试问题涉及 Python 相关的机器学习问题。
Q1.列举一些用于数据分析和科学计算的 Python 库。
以下是主要用于数据分析的Python库列表:
- 数值模拟
- 科学Py
- 熊猫
- 科学工具包
- Matplotlib
- 西博恩
- 散景
Q2。您更喜欢使用哪个库来使用 Python 语言进行绘图:Seaborn、Matplotlib 还是 Bokeh?

Python 库 – 机器学习面试问题 – Edureka
这取决于您想要实现的可视化效果。每个库都有特定的用途:
- Matplotlib: 用于基本绘图,如条形图、饼图、折线图、散点图等
- 西伯恩: 构建在 Matplotlib 和 Pandas 之上,以简化数据绘制。它用于统计可视化,例如创建热图或显示数据分布
- 散景: 用于交互式可视化。如果您的数据太复杂并且您没有在数据中找到任何“消息”,那么可以使用 Bokeh 创建交互式可视化效果,让您的查看者能够自行探索数据
Q3。 NumPy 和 SciPy 有什么关系?
- NumPy 是 SciPy 的一部分。
- NumPy 定义了数组以及一些基本的数值函数,如索引、排序、整形等。
- SciPy 使用 NumPy 的功能实现数值积分、优化和机器学习等计算。
Q4。 Pandas 系列和 Python 中的单列 DataFrame 之间的主要区别是什么?

Pandas 系列与 DataFrame – 机器学习面试问题 – Edureka
Q5.如何在 Python 中处理数据集中变量的重复值?
考虑以下 Python 代码:
bill_data=pd.read_csv("datasets电信数据分析Bill.csv") bill_data.shape #识别数据中的重复记录 Dupes = bill_data.duplicated() sum(dupes) #去除重复 bill_data_uniq = bill_data.drop_duplicates()
Q6.通过使用任何分类器导入任何数据集来编写基本的机器学习程序来检查模型的准确性?
#导入数据集 import sklearn from sklearn import datasets iris = datasets.load_iris() X = iris.data Y = iris.target #分割数据集 from sklearn.cross_validation import train_test_split X_train, Y_train, X_test, Y_test = train_test_split(X,Y, test_size = 0.5) #选择分类器 my_classifier = tree.DecisionTreeClassifier() My_classifier.fit(X_train, Y_train) Predictions = my_classifier(X_test) #检查准确率 From sklear.metrics import precision_score print precision_score(y_test, Predictions)
基于机器学习场景的问题
这套机器学习面试问题涉及基于场景的机器学习问题。
Q1.给您一个由缺失值超过 30% 的变量组成的数据集?假设,在 50 个变量中,有 8 个变量的缺失值高于 30%。你将如何对待他们?
- 为缺失值分配一个唯一的类别,谁知道缺失值可能会发现一些趋势。
- 我们可以明目张胆地删除它们。
- 或者,我们可以明智地检查它们与目标变量的分布,如果发现任何模式,我们将保留这些缺失值并为它们分配一个新类别,同时删除其他值。
Q2。编写一个 SQL 查询,使用您朋友喜欢的页面进行推荐。假设您有两个表:一个包含用户及其好友的两列表,以及一个包含用户及其喜欢的页面的两列表。它不应该推荐您已经喜欢的页面。
SELECT f.user_id, l.page_id FROMfriend f JOIN like l ON f.friend_id = l.user_id WHERE l.page_id NOT IN (SELECT page_id FROM like WHERE user_id = f.user_id)
Q3。有一个游戏要求你掷两个公平的六面骰子。如果骰子上的点数之和等于 7,那么您将赢得 21 美元。不过,每次掷两个骰子时,您都必须支付 5 美元才能玩。你玩这个游戏吗?后续:如果他玩6次,这个游戏赚钱的概率是多少?
- 第一个条件规定,如果 2 个骰子的点数之和等于 7,那么您将赢得 21 美元。但对于所有其他情况,您必须支付 5 美元。
- 首先,我们来计算一下可能出现的情况的数量。由于我们有两个 6 面骰子,因此案例总数 => 6*6 = 36。
- 在 36 种情况中,我们必须计算出总和为 7 的情况的数量(这样 2 个骰子上的值的总和等于 7)
- 产生总和为 7 的可能组合是 (1,6)、(2,5)、(3,4)、(4,3)、(5,2) 和 (6,1)。所有这 6 种组合的总和为 7。
- 这意味着在 36 次机会中,只有 6 次的总和为 7。根据比率,我们得到: 6/36 = 1/6
- 因此,这表明我们有机会赢得 21 美元,每 6 场比赛一次。
- 因此,要回答这个问题,如果一个人玩 6 次,他将赢得一场 21 美元的游戏,而对于其他 5 场游戏,他将每场支付 5 美元,即所有五场游戏都是 25 美元。因此,他将面临亏损,因为他赢得了 21 美元,但最终支付了 25 美元。
Q4。我们有两种在新闻源中投放广告的选项:
1 – 每 25 个故事中,就有一个是广告
2 – 每个故事有 4% 的机会成为广告
对于每个选项,100 条新闻报道中预期展示的广告数量是多少?
如果我们选择选项 2,用户在 100 个故事中只看到一个广告的机会有多大?完全没有广告怎么办?
- 对于选项 1,100 个新故事中显示的广告的预期数量等于 4 (100/25 = 4)。
- 同样,对于选项 2,100 个新故事中展示的广告的预期数量也等于 4(4/100 = 1/25,这表明每 25 个故事中就有一个是广告,因此在 100 个新故事中将有是 4 个广告)
- 因此,对于每个选项,100 个新故事中展示的广告总数为 4。
- 问题的第二部分可以使用二项式分布来解决。二项式分布采用三个参数:
- 成功和失败的概率,在我们的例子中是 4%。
- 案例总数,在我们的案例中为 100。
- 结果的概率,即用户在 100 个故事中仅看到一个广告的机会
- p(单个广告) = (0.96)^99*(0.04)^1
(注意:此处 0.96 表示在 100 个故事中看不到广告的概率,99 表示仅看到 1 个广告的可能性,0.04 表示在 100 个故事中看到一次广告的概率)
- 该广告总共有 100 个位置。因此,100 * p(单个广告)= 7.03%
Q5.您如何预测下个月谁会续订?您需要什么数据来解决这个问题?你会做什么分析?你会建立预测模型吗?如果是的话,哪些算法?
- 假设我们正在尝试预测 Netflix 订阅的续订率。因此,我们的问题陈述是预测哪些用户将续订下个月的订阅计划。
- 接下来,我们必须了解解决这个问题所需的数据。在这种情况下,我们需要检查每个家庭的频道活跃小时数、家庭中的成人人数、儿童人数、哪些频道播放最多、每个频道花费了多少时间、花费了多少时间观看率是否与上个月有所不同,等等。需要这些数据来预测一个人是否会在下个月继续订阅。
- 收集这些数据后,找到模式和相关性非常重要。例如,我们知道如果一个家庭有孩子,那么他们更有可能订阅。同样,通过研究上个月的观看率,您可以预测一个人是否仍然对订阅感兴趣。必须研究这种趋势。
- 下一步是分析。对于此类问题陈述,您必须使用将客户分为 2 组的分类算法:
- 下个月可能订阅的客户
- 下个月不太可能订阅的客户
- 你会建立预测模型吗?是的,为了实现这一目标,您必须构建一个预测模型,将客户分为如上所述的两类。
- 选择哪些算法?您可以选择逻辑回归、随机森林、支持向量机等分类算法。
- 选择正确的算法后,您必须执行模型评估以计算算法的效率。接下来是部署。
Q6.如何将昵称(Pete、Andy、Nick、Rob 等)映射到真实姓名?
- 这个问题可以通过多种方式解决。假设您收到一个包含 1000 个 Twitter 交互的数据集。您将首先通过仔细分析推文中使用的词语来研究两个人之间的关系。
- 此类问题陈述可以通过使用自然语言处理技术实施文本挖掘来解决,其中对句子中的每个单词进行分解并找到各个单词之间的相互关系。
- NLP 积极用于理解客户反馈,在 Twitter 和 Facebook 上进行情感分析。因此,解决这个问题的方法之一是通过文本挖掘和自然语言处理技术。
Q7.一个罐子里有1000枚硬币,其中999枚是公平的,1枚是双头的。随机挑选一枚硬币,然后抛掷 10 次。假定您看到 10 个正面,那么下一次抛掷该硬币也是正面的概率是多少?
- 选择硬币有两种方法。一种是挑选一枚公平的硬币,另一种是挑选有两个头像的硬币。
- 选择公平硬币的概率 = 999/1000 = 0.999
选择不公平硬币的概率 = 1/1000 = 0.001 - 连续选择 10 个正面 = 选择公平的硬币 * 获得 10 个正面 + 选择不公平的硬币
- P(A) = 0.999 * (1/2)^10 = 0.999 * (1/1024) = 0.000976
P(B) = 0.001 * 1 = 0.001
P(A / A + B ) = 0.000976 / (0.000976 + 0.001) = 0.4939
P( B / A + B ) = 0.001 / 0.001976 = 0.5061 - 选择另一个头的概率 = P(A/A+B) * 0.5 + P(B/A+B) * 1 = 0.4939 * 0.5 + 0.5061 = 0.7531
Q8.假设给您一个数据集,其中缺失值与中位数相差 1 个标准差。有多少百分比的数据不受影响?为什么?
由于数据分布在中位数上,我们假设它是正态分布。
如您所知,在正态分布中,约 68% 的数据与平均值(或众数、中位数)相差 1 个标准差,这使得约 32% 的数据不受影响。因此,约 32% 的数据将不受缺失值的影响。
Q9.您将获得一个癌症检测数据集。假设当您构建分类模型时,您的准确率达到了 96%。为什么你不应该对你的模型表现感到满意?你能为这个做什么?
您可以执行以下操作:
- 添加更多数据
- 处理缺失的异常值
- 特征工程
- 特征选择
- 多种算法
- 算法调优
- 集成法
- 交叉验证
Q10.您正在处理时间序列数据集。您的经理要求您建立一个高精度模型。您从决策树算法开始,因为您知道它对所有类型的数据都运行良好。后来,你尝试了时间序列回归模型,得到了比决策树模型更高的准确率。这会发生吗?为什么?
- 时间序列数据基于线性,而已知决策树算法最适合检测非线性交互
- 决策树无法提供稳健的预测。为什么?
- 原因是它无法像回归模型那样很好地映射线性关系。
- 我们还知道,只有当数据集满足其线性假设时,线性回归模型才能提供稳健的预测。
Q11.假设您发现您的模型存在低偏差和高方差。您认为哪种算法可以解决这种情况?为什么?
第一类:如何解决高方差问题?
- 当模型的预测值接近实际值时,就会出现低偏差。
- 在这种情况下,我们可以使用装袋算法(例如:随机森林)来解决高方差问题。
- Bagging 算法将通过重复随机采样将数据集划分为子集。
- 一旦划分,这些样本可用于使用单一学习算法生成一组模型。随后,使用投票(分类)或平均(回归)来组合模型预测。
类型2:如何解决高方差问题?
- 通过使用正则化技术来降低模型复杂性,其中较高的模型系数会受到惩罚。
- 您还可以使用变量重要性图表中的前 n 个特征。对于数据集中的所有变量,算法可能在寻找有意义的信号方面面临困难。
Q12.给你一个数据集。数据集包含许多变量,其中一些变量是高度相关的并且您知道它。您的经理要求您运行 PCA。您会先删除相关变量吗?为什么?
也许,您可能会想说“不”,但这是错误的。
丢弃相关变量将对 PCA 产生重大影响,因为在存在相关变量的情况下,由特定分量解释的方差会被夸大。
Q13.系统要求您构建多元回归模型,但您的模型 R² 没有您想要的那么好。为了改进,您删除了截距项,现在您的模型 R² 从 0.3 变为 0.8。是否可以?如何?
对的,这是可能的。
- 截距项是指没有任何自变量的模型预测,即均值预测
R² = 1 – Σ(Y – Y´)²/Σ(Y – Ymean)² 其中 Y´ 是预测值。 - 在存在截距项的情况下,R² 值将根据平均模型评估您的模型。
- 在没有截距项(Ymean)的情况下,模型无法做出这样的评估,
- 分母很大,
Σ(Y – Y´)²/Σ(Y)² 方程的值变得小于实际值,从而导致 R² 值更高。
Q14.您需要构建一个包含 10000 棵树的随机森林模型。在训练过程中,训练误差为 0.00。但是,测试时验证错误为 34.23。到底是怎么回事?你的模型训练得还不够完美吗?
- 该模型过度拟合数据。
- 训练误差为 0.00 意味着分类器在一定程度上模仿了训练数据模式。
- 但是当这个分类器在看不见的样本上运行时,它无法找到这些模式并返回带有更多错误的预测。
- 在随机森林中,当我们使用超出必要数量的树时,通常会发生这种情况。因此,为了避免这种情况,我们应该使用交叉验证来调整树的数量。
Q15.亚马逊上看到的“购买此商品的人还购买了……”的推荐基于哪种算法?
亚马逊等电子商务网站利用机器学习向客户推荐产品。这种推荐的基本思想来自于协同过滤。协同过滤是比较具有相似购物行为的用户,以便向具有相似购物行为的新用户推荐产品的过程。
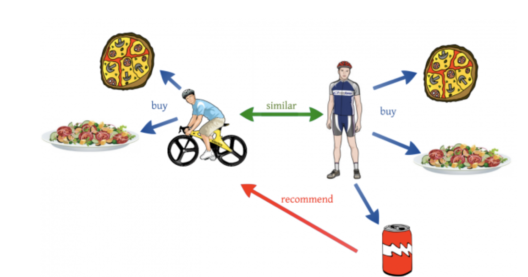
协同过滤 – 机器学习面试问题 – Edureka
为了更好地理解这一点,让我们看一个例子。假设一位运动爱好者用户 A 购买了披萨、意大利面和可乐。现在几周后,另一个骑自行车的用户 B 购买了披萨和意大利面。他没有买可乐,但亚马逊向用户B推荐了一瓶可乐,因为他的购物行为和生活方式与用户A非常相似。这就是协同过滤的工作原理。
这些是机器学习面试中最常见的问题。但是,如果您想温习更多知识,可以浏览以下博客:
至此,我们的博客就结束了。我希望这些机器学习面试问题能帮助您在机器学习面试中取得好成绩。
学习机器学习的基础知识、机器学习步骤和方法,包括无监督和监督学习、数学和启发式方面,以及创建算法的动手建模。您将为机器学习工程师的职位做好准备。机器学习课程硕士课程将为您提供有关现实世界中机器学习应用的最深入、最实用的信息。此外,您还将学习在机器学习领域取得成功所需的基础知识,例如统计分析、Python 和数据科学。
此外,如果您想成为一名成功的深度学习工程师,您可以使用 Edureka 的 Tensoflow 参加深度学习课程培训。





