

AI绘画的浪潮卷起后,我们几乎进入了“AI美术时代”。足够低的门槛,让每个人都有机会成为“画家”,人们也开始思考这场技术变革到底会走向何方。但与此同时,绝大部分人实际上只对AI绘画一知半解,更别提有一个系统的认知,却在这种前提下陷入了无休无止的争论之中。
越是如此,我们就越需要跳出思维定式,把注意力放到技术本身。因此,在前一阵的直播中,葡萄君邀请到了灵游坊CEO梁其伟、专业PPT设计师&知名设计美学博主Simon_阿文,以及网易雷火艺术中心的原画师HS聊了聊AI美术的现状和发展。(直播回放可在游戏葡萄视频号观看)
在直播中,不少观众都对他们的分享和见解表示了高度肯定,如果你也想更了解AI美术,这篇文章或许会对你有用。耐心看完,你会发现画涩图可能是对AI绘画最低级和缺乏想象力的应用,而那些日新月异却被大多数人忽视的新技术,或许就是下一次技术革命的基础。(本文发出时,技术亦已有不少更新换代,感兴趣的读者可于@Simon_阿文、@Simon的白日梦 的微博自行了解)
由于直播较长,我们将分两次整理图文内容。本文整理了阿文的分享,以及他和HS有关AI绘画的一些实操心得。你可以按以下索引选择自己感兴趣的部分阅读:
01 AI绘画的前世:梗图(AI绘画的源头及发展历程)
02 AI诸神之战的第一阶段(各种绘画工具及其对比)
03 AI诸神之战的过渡阶段(最值得关注的那些AI绘画逆天功能)
04 AI诸神之战的第二阶段(AI生成视频、3D模型等未来趋势)
附:AI绘画实战小心得
以下为直播中阿文分享的整理,为方便阅读,部分内容有调整(图片来自直播截图,以及@Simon_阿文、@Simon的白日梦 的微博):
今天我要分享的主题是《AI绘画的诸神之战》。首先简单介绍一下,我是一名PPT设计师,因为平时经常在网上分享一些设计神器,偶然间接触到AI绘画,就一直玩到现在了。

在开始前做一个免责声明:我只是一位普通设计师,本次分享仅代表个人观点和使用体验。如果我有专业技术概念错误,各位一定要及时纠正,谢谢大家。
01 AI绘画的前世:梗图
AI绘画技术的源头,最早可以追溯到2015年AI圈子里一项重要的研究——机器可以识别图像上的物体了。比如你给他一张这样的图片,机器就会识别出图像上的蝴蝶和猫,并返回一个描述句。
这项技术在当年挺轰动的,当时就有一群科学家跑出来说,我能不能把这个过程给调换一下?把这句话告诉AI,让它给我一张类似的图?这应该算是目前AI绘画的发展源头——这群科学家真的跑去研究了。 第二年他们就发表了一篇论文,里面举了很多例子。
比如告诉AI我需要“一辆绿色的校巴停在停车场上”,AI就真的生成了类似的图像。这组图还非常模糊,因为它只有32×32像素,这就是6年前的技术水平,但当时你已经能隐约看到AI绘画的现状了。
到2021年左右,一家叫Open AI的伟大公司发表了另一篇论文,说我们已经可以把清晰度提得很高了。这项技术就是初代DALL·E,当时也非常轰动。比如你需要“一把牛油果形状的椅子”,它就会返回这样的图像。
你需要“一只大蒜做的蜗牛”/“一只苹果做的大象”,它也能给出类似的结果。
大家看到这些图可能会笑——这不是一些低清的梗图吗?拿来使用几乎是不可能的。2021年,整个社交网络、学术圈几乎也是像看段子一样看待这项技术。但大家没想到的是,2022年,AI绘画元年来了。
今年我们再画类似的东西会怎么样?你画一只苹果做的大象,DALL·E 2已经能做到这样——它画出的形态、结构都非常准确了。
这样的质量和清晰度,直接用来当PPT封面都是可以的。
当初我是在一位艺术家朋友@疯景CrazyJN的微博上看到AI绘画技术的,这是我第一次跟Disco Diffusion相遇,看到时我也非常非常震惊。他画出来的作品,放在4个月以前,对我的冲击已经非常之大。
于是我马上去了解了AI作画,5分钟之后,我在Disco Diffusion里打下了一句话:“星空下的向日葵花海”,看着画面渐渐从模糊变清晰,我至今依然记得当时的那种兴奋和震惊,真的非常的夸张——我只需要一句话就能画出这样的画面。
我非常兴奋地告诉周围的朋友,并且让AI给我画了一个通宵。
而且让我完全没想到的就是,这仅仅是个开始而已。我也没想到。这个技术在半年以后的今天已经发展到这么夸张——我们已经进入到AI诸神之战的第一阶段。
02 AI诸神之战的第一阶段
在这个阶段里,你会看到很多优秀AI绘画应用的诞生,以及各个大厂的进场。因为在座各位可能对AI绘画工具有一定的了解,我简单过一下这个阶段里的优秀代表:第一个当然是Disco Diffusion,它是免费开源的。(
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb?hl=zh_TW#scrollTo=Prompts)
我对它的评价是「最早出圈的AI绘画工具」。因为它是纯代码界面、部署在Google上,所以用户友好度并不那么高。
生成速度上,相信早期体验过的人也能感觉到绝望——如果不买Colab会员,至少是半小时到40分钟一张。当初我买了会员就挂机一个通宵,第二天早上再起来收图。这样持续了大半个月,我做了很多尝试和调教,生成了不少我当时还挺满意的作品,比如让AI模仿水墨画、油画风格,甚至是模仿一些大师,比如Joseph Gandy、异形之父 H. R. Giger、吉卜力等等。
我个人非常喜欢静物油画,但当时只能画出一些厚涂画面,要让AI画出一组非常清晰的静物几乎不可能。于是我就对AI进行了调教——找不同的关键词、艺术家去尝试。
上图是我的调教过程,结果我当时还挺满意的。当然,为了遮丑我做了一些排版,美滋滋地发了一条微博,说我调教了一整天,终于让机器人学会了画静物画。
结果没想到,这条微博发出去没几天,我就被打脸了。因为另一个更强大的AI诞生了——MidJourney。(discord.gg/midjourney)
你甚至不用调教,它就能生成非常美观的图片。
它最直观的特点就是「快」。同样一句话,它在1~2分钟内就能很好地生成结果。
当时我用的第一个关键词,是“一组记录早期麦当劳的油画”。当时我5分钟内就得到了大量结果。
回过头来看前几天花了一整天调教的Disco Diffusion,我就傻了——这种新技术讨厌的地方,就是它直接否认了你以前的一些努力,而且后续MidJourney甚至发展得更好。这是它在5月份时的表现,后面我们可以再看看它现在的表现。
之后我还没从MidJourney的震惊里醒过来,另一个工具又出现了——Open AI开发的DALL·E,我对他的评价几乎是满星的,无论是友好度、生成速度、精准度还是艺术性。
(labs.openai.com/waitlist)
它的缺点就是太贵了,现在普通用户基本用不起,点一次生成就是一块钱人民币,除非你对自己的关键词非常自信,要么你就是人民币玩家不在乎。
除了速度和精准度,DALL·E的优点凸显在它的真实性和对关键词的还原度。大家可以比一下刚才和现在的案例——笔触、细节是完全不一样的。这是我生成的“一组记录早期人们没有WiFi怎么办的图片”,看到结果时我非常兴奋。
而且它对人类语言描述的理解度非常高,高到什么程度?可以看这两个例子:分别是“暴雨后城市人行道水坑上的浮油”——大家可以看到它的反光、倒影;右边这道抖机灵的题目更夸张:“4个角的三角形你要怎么画”?这是AI给出的答案。
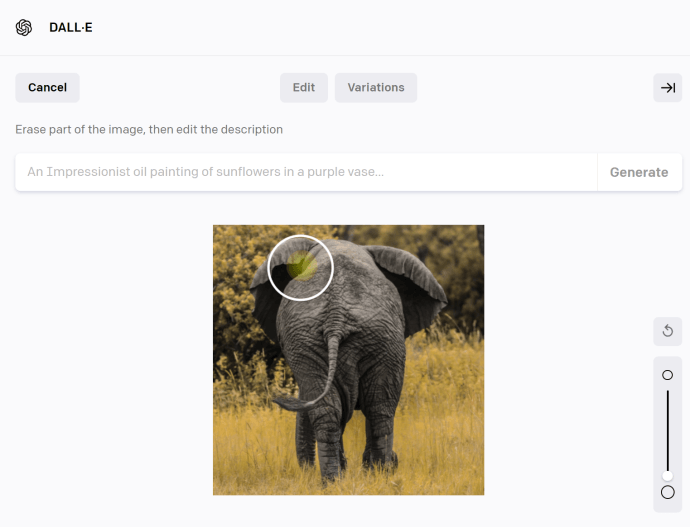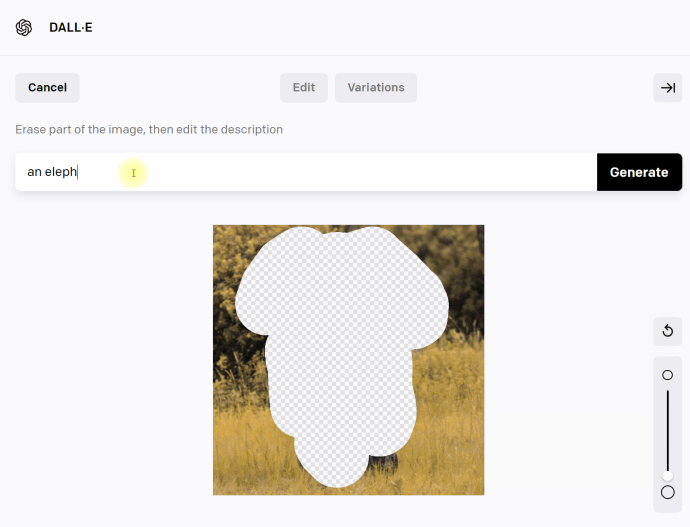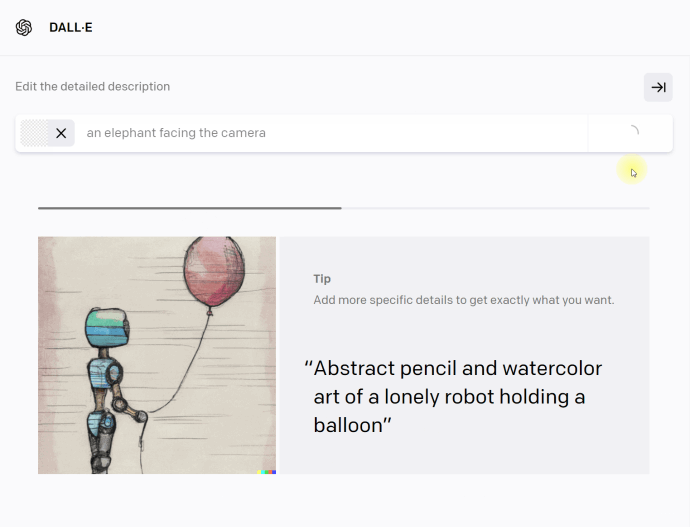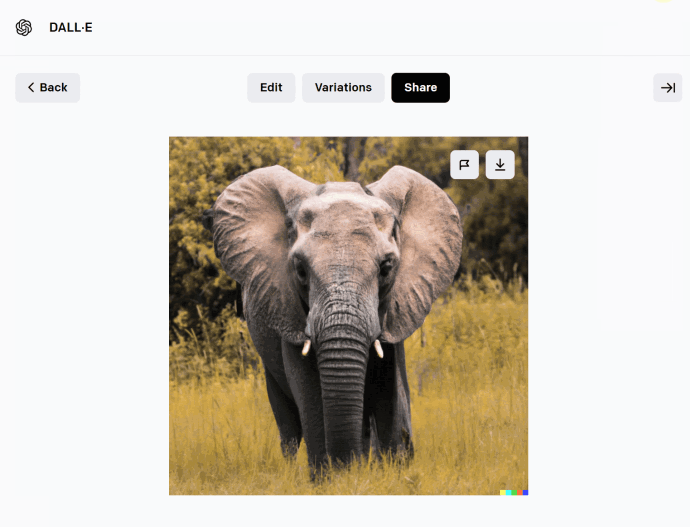
出于这种精准的理解力,我对它的概括是:它有可能是「乙方设计师的终极形态」。无论你下什么需求,它都能接得住。所以有了它之后,我就觉得世上再没有傻逼需求了,为什么这么说?因为我反手给了他一个非常经典的需求——以前甲方不是总说想让一头大象转身嘛,我就尝试让大象转身了。
它背后的原理,就是我把这张图片上大象的背面擦掉,再给AI输入一个大象面对镜头的描述。由于它对风格和语言的理解非常精确,所以结果看起来就真的是转过来了。评论区的网友非常逗,他们觉得这个需求不够变态,说能不能把大象塞进冰箱?我真的塞进去了。
还有同学说,能不能把大象放到海洋馆?我也真的让大象去游泳了。
还有大象和鲨鱼跳舞,大象骑着哈雷狂飙……评论区的甲方真的太可怕了,但是一点都难不住DALL·E。
甚至还有更扯的——能不能让大象称一下曹冲?AI表示我尽力了……
以上就是在五六月份时DALL·E的表现。这三个工具几乎统治了上半年AI绘画的话语权,但我完全没想到的是,这只是一个开始。
在接下来的六七八月,各个大厂陆续进场。比如Google发表了一个叫Imagen的AI绘画工具,他敢直接叫板DALL·E,他说我们有前所未有的写实感和深度的语言理解。Imagen生成的图像,也确实证明了它有这个能力。
(gweb-research-imagen.appspot.com)
看看这些图的清晰度,对比刚才DALL·E的生成结果。其实你细看时还是会感觉到边缘有一些笔触感,但真的越来越像照片了。
除此之外,Google是很喜欢一题多解的、非常卷的一家公司,所以没多久他又推出了另外一个工具叫Parti,效果同样也非常好。这些大厂的模型你可以简单地理解为DALL·E的高清版或加强版——大家都在卷图像的清晰度,以及对语言的理解能力。
(parti.research.google)
除了Google,Meta也发布了叫Make a scene的工具,在创造场景方面非常厉害。(
https://twitter.com/MetaAI/status/1547598454922153985)
后来微软也下场发布了一个叫女娲的产品,也非常酷,但生成效果在我看来其实还是DALL·E的加强版。(
https://nuwa-infinity.microsoft.com/#/)
他们纷纷下场,都是为了证明自己也有“制造核武器”的能力——AI绘画嘛,谁不会呀?但是说了这么多,没有一家开放内测。他们只是跑出来发一篇论文或是发表一些demo,就没有下文了。
为什么会这样?其实里面有很多顾虑,首先最重要的就是现在吵得最凶的版权问题。另外就是考虑到不开源可以造一些壁垒,给自己公司偷跑的机会。 但是这些在另一家公司看来都没用——非常有名的Stability,他们在8月份发布了Stable Diffusion。我当初对它的形容是「目前AI绘画的王者」。(
https://stability.ai/blog/stable-diffusion-public-release)
为什么这么说?同样是模仿大师,我们可以看看它的效果。左边是好几个月前MidJourney画的梵高,虽然颜色和构图很像梵高本人,但你会发现笔触不太干净——不过现在已经解决了;右边是让Stable Diffusion画的“梵高的长城一日游”,这个语言和风格的理解能力就很夸张了。
而且我让它画了一些从来没有出现过的静物——比如“一个种满了珊瑚的花瓶”。结果它真的画出来了,而且清晰度也很高。
我让它模仿一位科幻概念作家Simon的风格、日本画家的浮世绘风格,也都有不错的结果。按理说日本的浮世绘画家基本不会去过欧洲,但我让它尝试用浮世绘画欧洲风景,这个味道却还是很对。
而在能力如此强大的前提下,Stability最后做出了一个非常重要的选择——它不像前面的那些大厂选择保存实力,而是将Stable Diffusion开源。
这意味着什么?我们可以先了解一下Stable Diffusion为什么这么厉害:其中一个原因是巨大的训练数据量。它一共有20亿张图片、数据量高达10万GB的训练集。最终训练完后,它的模型又被压缩到两个GB,也就是说现在要生成任何图像,它都只需要通过这2GB的模型来搞定。
目前很多画风抄袭之类的争议,其实都偏向于艺术领域。但我跟开发者聊过,他们表示我们所谓的艺术作品,在这20亿图片里只是很小的一个子集——它采集的更多是真实照片和图像,但大家往往只是热衷于让AI模仿概念设计和艺术家的画风。所以Stable Diffusion目前展示出来的能力,还是被我们小看了的,它还有更强大的能力有待挖掘,这个我们之后再讲。
这么大的训练量,它的训练成本有多高?据说整体的训练费用在60万美元左右。这对于一家小公司来说已经是天文数字了,但他们最后选择了开源,几乎就改变了整个游戏规则。
开源就意味着,任何一家公司都可以直接引用它的技术,魔改它的模型。所以我说Stable Diffusion的开源,其实宣告了诸神之战第一阶段的结束。 关于第一阶段的工具,我个人首先建议不用全都了解,而是熟练掌握其中至少一个就可以了。我比较推荐Stable Diffusion、MidJourney和DALL·E,其中MidJourney是设计师必修的工具。
第二个建议是我们永远只相信大厂的模型,不要去用那些民间开发的换皮野鸡模型。比较具有代表性的一个案例,就是引起了无限争议的二次元模型NovelAI。我之前在微博上说过不建议大家使用,就是出于这样的原因。因为大厂建立模型经过了很多风险的规避,用它们是相对安全的。
回到刚才的话题,为什么我建议设计师必修MidJourney?因为MidJourney在每一波的技术潮流里都没有特别耀眼,没有跟风地追一些新功能,一点都不激进。但是它能踏踏实实地把每一个功能做好,在跟Stable Diffusion合作之后,它推出的模型质量也非常高。
所以我之前有这样的评价:如果说Stable Diffusion是班里的富二代+天才,特别耀眼;MidJourney就是那种踏踏实实做功课,最后考全班第一的学生。我们可以看看MidJourney的变化:从5月份开始到前一阵的9月份,它的进步是有目共睹的。
这是我用AI画的一组“窗边少女”,很有意思的是当我调整了窗边的风景,窗外的风景也会随之改变。
另外一个非常值得设计师们关注的功能是无缝图片生成,我们用在一些3D贴图或背景上都非常好用。
03 AI诸神之战的过渡阶段
以上就是AI绘画最长的第一阶段。
所谓的过渡阶段,就是在Stable Diffusion开源之后,大家没有必要再卷新模型了,所以这一阶段井喷式地涌现了很多基于Stable Diffusion的插件和应用。
在第一周诞生的插件数量,我粗略地数了一下,大概有十几个。还有一些是撞型的,比如与Blender、PS相关的就分别都有两三个。 有些同学会问有哪些值得关注的插件,这个问题是完全错误的。为什么?因为我们首先要搞懂 AI绘画的传统艺能,再来谈插件——90%的插件应用,其实都是直接调用官方的API而已,并没有多少功能上的创新。
如果连工具本身都搞不懂就去用插件,肯定会被插件带偏。 至于AI绘画的传统艺能,我总结起来一共只有三个,非常重要:
第一个叫Inpainting/Outpainting,即局部的重绘或画面扩展,也可以粗暴地理解为PS的内容识别——把一部分内容擦掉、识别为其他内容。 但是它无敌的地方在于,你擦掉的地方可以无中生有。下面这两个例子,第一个是Inpainting,即我刚才演示的大象转身;
Outpainting很好理解——扩展画布,你可以把一幅名画扩展为一幅非常巨大的宽幕画。当你理解了AI的这些功能之后,我们再来看这些插件,你就会淡定很多。(
https://twitter.com/_dschnurr/status/1565011278371794944)
这是当初刚发出来就非常轰动的一个PS插件,它不就是Outpainting吗?把两张图片之间的空白区域,用文字描述生成的内容连接起来。
(https://twitter.com/CitizenPlain/status/1563278101182054401)
这是新版PS自带的AI功能,不就是Inpainting吗?擦掉一个区域再重新生成一只猫头鹰。
(https://blog.adobe.com/en/publish/2022/10/18/bringing-next-wave-ai-creative-cloud?utm_content=225122458&utm_medium=social&utm_source=twitter&hss_channel=tw-708994126205865985)
这同样也是PS自带的AI功能,据说在新版的PS里都会实装。这不也是Outpainting吗?
还有一个特别唬人的演示,它看起来似乎能直接擦掉视频里的主体,然后重新生成一个其他主体。非常酷炫对吧?其实它的原理也是Inpainting。演示中被修改的内容其实是一个静帧,只是配合镜头的推拉之后,它会显得像是修改了视频里的动态片段,大家千万不要被吓到。(https://runwayml.com/)
AI的第二个传统艺能是image to image——以图生图。这个功能也非常常用,早在4月份时Disco Diffusion就已经有了,大家可以粗暴地理解为垫图生成。比如我随便画了张构图给AI,就能生成右边的图像。当然,这要配合一句描述文本。
了解了这个技术概念之后,再来看这个插件演示,就会发现它其实也是垫图生成的一种。只是因为换了Stable Diffusion的模型之后,它生成的结果变得更好了。(
github.com/CompVis/stable-diffusion)
这也是同样的一张草图+一句描述,生成一个非常精美的画面。(
https://twitter.com/HanneMaez/status/1556960748592631809)
还有一个非常唬人的Blender插件AI Render,看起来好像直接用AI就能渲染了。
(https://airender.gumroad.com/l/ai-render?continueFlag=9b370bd6ba97021f1b1a646918a103d5)
当时我发微博时,其实很多没玩过AI绘画的同学都误以为,我直接在blender里拉一个场景,AI就能直接渲染出这么酷炫的画面。其实说到底它的原理还是垫图生成——在你当前的渲染画面生成一个静帧,加一句描述,再用Stable Diffusion渲染成另一个场景,不得不说看起来特别唬人。
AI的第三个传统艺能是无缝纹理生成。这其实是针对3D用户的一项细分功能,现在MidJourney已经做得非常好了,而且清晰度非常高。它最高能生成2048×2048——也就是2K的清晰度,用来铺背景已经相当够用了。(
https://weibo.com/1757693565/M6WpRqNP8?pagetype=profilefeed)
这样的功能也被很多厂商或个人开发者做成插件,比如做到blender里。这是其中一个,乍一看也是非常酷炫,但其实这些技术在各个模型的官方网站里都能做到,且非常成熟。(
github.com/carson-katri/dream-textures)
这些分享是为了告诉大家:第一,在AI绘画的过渡阶段里,我们不要过分迷信那些插件或应用,永远只相信大厂的模型就好了。
因为模型里该有的功能都有,所以我们至少掌握其中一种,你就没那么焦虑了。 第二,我们可以密切关注一些大厂的产品。这里的大厂指的是设计公司中的大厂,比如Adobe、微软等。他们发布的一些内置功能,可能比任何插件都靠谱。
如果你懒得关注,也可以密切关注我的微博,我会经常转发一些较新的技术新闻。
前几天在Adobe max大会上,Adobe发布了他们未来有关AI工具的演示。我刚才提到所有的传统艺能,它几乎都内置到了PS等一系列全家桶产品里了,而且非常丝滑。
用这样的官方插件,效果肯定比那些民间插件要好。 包括微软的office系列,他们非常聪明,直接选择跟Open AI——也就是DALL·E合作,发布了一款叫Microsoft Designer的产品。当然,它的实际效果可能没有宣传片那么夸张——微软是出了名的宣传片大厂。但是其中演示的文字生成图片、自动排版等功能,都是可以实现的。
(https://designer.microsoft.com/)
吐槽完插件和应用之后,有同学会问Text to image真的已经玩到头了吗?其实还有几个值得我们关注的模型。如果说AI诸神之战第一阶段,我们要关注的是模型生成能力,那么过渡阶段我们就应该关注编辑能力——也就是AI对画面的微调能力。
这里我推荐大家关注两个产品或方向:第一个叫DreamBooth,它由Google开发,现在已经有大神把它做成开源版本了。它能做到完美解决画面的连贯性问题。
(https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb)
传统的AI工具生成的图片都是独立分开的,你没法让同一个主体出现在连续的画面里,也就是说我们没办法让AI自己画连续的漫画或分镜。但在这个产品中,你上传几张图片之后,AI就会记住你图片中的主体。当你再在AI里输出时,它就能记住主体的样子,并且套用到你的描述句中。 比如我给AI识别一条小狗,只需要给它3到4张图片,就能生成右边这一大堆不同风格的小狗。
这招如果被用在一些分镜设计或漫画的演示里,会非常酷炫。国外有一个整活天团,就尝试用人来做这样的生成——他们给同事拍了几张照片,丢到AI里训练,最后用Stable Diffusion生成出来。可以看到,当AI记住了一个人的面部特征后,它就能直接将其作为关键词生成各种不同风格的图片。
有些同学可能会吐槽:这不是早就有的换脸技术吗?大家可以仔细看看,这跟换脸是完全不一样的——它可以生成不同扮相的图像,甚至是乐高风格,这是换脸换不出来的效果。
另一个值得关注的产品,是Google最近发表的Imagic,它可以让整项技术“快进到甲方说唱出需求”。(
github.com/justinpinkney/stable-diffusion/blob/main/notebooks/imagic.ipynb)我们知道,Inpainting就是擦掉画面的一部分再重新生成内容,但是现在的技术已经能做到不擦除画面上的任何东西,而是改变描述文本,AI就会直接相应地改变图像。
04 AI诸神之战的第二阶段
说了这么多,其实所有事情几乎都发生在9月份之前。而在9月份的最后一天,AI绘画诸神之战的第二阶段开始了——他们开始卷卷视频和3D模型了。
这里我快速给大家过一下,我们要关注哪些大厂的模型或产品。 首先,最快发表Text to video技术的是Meta。它在那天深夜发了一条推特,看得我完全睡不着了。第一,它能做到一句话生成这样的视频。(
https://makeavideo.studio/)
第二,它能让一段素材视频衍生出不一样的风格。
第三,你上传两张相近的图片,它能自动用视频生成过渡内容。这里的过渡可不是指直接的淡入淡出或追踪,而是重新生成。
第四,它能让图片动起来。我们以前在AE里想做到下面这件事,起码要先把海龟抠出来再做一些绑定,但是用AI一句话就搞定了,甚至还能转身,非常夸张。
这是让一张油画动起来的效果。这些水的效果,我相信现在有很多插件也能做,但是做到这种程度应该要花很多时间。
以上几个小功能,是大厂未来绝对会卷的另一个方向。
Meta发布这个论文之后没多久, Google也下场了,而且连发两条。第一个就是根据之前Imagen模型发布的视频版本,它能做到素材级别的清晰度。
(https://imagen.research.google/video)
在同一天,Google又发布了另一个模型Phenaki。Google真的很卷,他们的科学家团队最近疯了一样地对外发表论文,而且每一篇都非常夸张。
有同学提出,AI能不能让生成的视频具有逻辑上的连续性?比如我输入一段剧本,AI为我输出一部电影——这个模型似乎证明了,这种设想是可以实现的。(https://phenaki.video/)
大家可以细看这图片下方的描述,感受一下AI在描述与描述之间的画面切换,非常流畅。而且它除了模拟实物,还能套用风格。
除此之外他们测试了一下,用了一个老模型生成了两分钟的视频。当然,生成内容看起来还是有瑕疵,清晰度也不够,但是大家想想,当初AI绘画最早期不也是这样吗?所以我们可以大胆畅想未来。
这就是在Text to video方面我们需要关注的一些产品。值得一提的是,这三个模型居然是在同一天发表的,可见他们卷成什么样了。
Text to model——也就是AI生成3D模型方面,又有哪些需要我们关注呢?这里我简单列举一下:首先是dreamfusion3d——文字直出模型。还有通过单张图片生成3D模型,它的做法非常巧妙,并不是直接到3D模型这一步,而是用AI绘画把桌子或椅子的三视图脑补出来再生成模型。(dreamfusion3d.github.io)
如果大家对Text to 3D有兴趣,可以关注我的好朋友@Simon的白日梦,他是这方面的专家,在微博上发表了很多关于AI生成3D模型的知识。
以上就是我今天所有的分享,这么长的一个阶段,在我们人类设计师看来,这种进步放在自己身上是不可想象的,但整个过程确实只过了6个月而已。未来会发展成什么样?我也不知道。
有人会说,知道这些有什么用?我想说的是,想要弯道超车,我们就要学会足够多的歪门邪道。况且我以上说的这些技术并非歪门邪道——它们很可能就是下一次技术革命的基础。
05 附:AI绘画实战小心得
HS:在实际的AI绘画中,有些同学对关键词的描述不是特别清晰。我们先用“丝绸之路”来试试——如果单纯输入这个词的机翻,它会生成一个非常单一的沙漠场景。因为现在它对关键词的理解,其实更多会偏向美国公路之类的描述。
我们可能需要到网站或维基百科上找寻一些官方翻译,另外也可以再拓展一些元素,比如它是中国唐代丝绸之路、有一些商队骆驼、参考了一些游戏,比如《刺客信条》、有夜晚星空,再加上虚幻引擎的渲染,呈现出的效果就会和之前完全不同,会有一些故事性。
另一位同学提供的词是“大闹天宫”,它的机翻是“the Monkey King”,直接输入会生成一个妖猴,跟大闹天宫还是有点差异的。
如果调整为“孙悟空在天宫制造了一场灾难”,画出来就会有不一样的效果。作为方案参考的话,这些已经足够了。如果你想参考动画片的风格,还可以输入电影制片厂或动画片名之类的关键词。
所以我们在输入关键词时,一定要经过大脑的思考和演变,才能让AI更好理解你要的是什么。 Simon_阿文:我个人的绘画思路其实非常简单——抄作业。相信很多同学刚接触AI绘画时都是小白,不知道怎么写关键词。但现在我们有很多可供参考的关键词库,比如你买了MidJourney的付费服务,就会得到一个官方的主页面,它的社区里会每天推送不同的优秀作品。
这些首页AI作品的质量都非常恐怖,所用的关键词也绝对是顶流。我平时的习惯就是把这个页面设为浏览器的默认打开页,每天进来时收收菜——收藏一些关键词以备之后参考。
但是大家在抄作业时要注意一点:直接复制这些关键词,效果往往不是最好的,因为很多高手会加修改器指令。正确的方法是复制它的命令,命令包含了这张图的关键词和所有修改器指令。
指令是AI工具独有的一些快捷设置。比如设置比例是--ar 加上比例(如16:9),调用测试模型要加--test,要让画面更有创意,更接近原画质感,那最好加一个--creative。 这些指令你要翻工具对应的文档才会知道,很多同学就是因为漏了这些,所以生成效果没那么好。如果你有某个需求想不出关键词,还可以在社区直接搜索,这是一个快速学习的方法。
但是这也有一点不好:很多时候我们复制了一大段描述,却不知道文本在说什么。我们平时输入关键词可能只是写一句话而已,但很多高手是像写小说一样。这时我们要怎么去学习?我的方法是翻译一下,找到这段关键词里最终产生需求画面的部分。像是high detAIl、UE5等,都是非常通用的关键词,看多了就会找到规律。 还有一个大招,就是去第三方的关键词推荐库查找。推荐大家两个网站,一个是KREA(krea.AI),能直接搜到很多现成的关键词。
同类的还有另一个网站lexica(lexica.art),它们只针对于Stable Diffusion,但除了修改器指令不同之外,关键词都可以通用。





