
随着AIGC的发展,AI绘画逐渐进入我们的生活和工作。本文将探讨AI绘画技术的各个方面。从图像生成技术迈出的里程碑事件,到对AI绘画技术的深度科普,再到未来的发展趋势分析,相信本文将能够为大家揭示AI绘画背后的神秘面纱,一起来深入了解其技术原理吧。

我会通过两篇文章来对AI绘画产品进行分析,第一篇主要科普图像生成技术原理;第二篇是分析AI绘画产品商业化落地,算是我近期对AI绘画产品了解的一个总结输出,以下是第一篇内容。

2022年9月一幅名为《太空歌剧院》的画作在数字艺术类别比赛中一举夺冠,这个震惊四座的画作由游戏设计师Jason Allen使用Midjourney完成,AI绘画进入人们的视野。
人们第一次意识到AI做出来的画可以如此精美,意识到AI绘画可能如同当年相机、数字绘画的出现一样,会给绘画设计行业带来一场深刻的变革。
这篇文章从产品经理视角,了解AI绘画产品的背后有哪些算法模型、他们的技术原理是什么?不同技术的边界在哪里,使用场景在哪里?产品经理要懂得将算法合理的组合使用,以满足日常工作的需求,实现产品目标。
- AI绘画发展的主要节点
- AI绘画的底层原理
- 主流的图像生成模型解析
- AI绘画的可控性有哪些
- AI绘画的技术研究趋势
一、AI绘画发展的主要节点
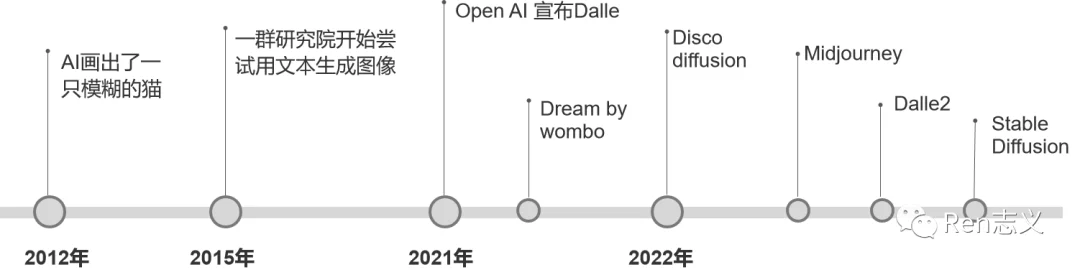
1. 2012年AI画出了一只模糊的猫
吴恩达和杰夫安迪使用了1.6万个CPU和You Tube上1000万张猫的图片,用时3天时间训练了当时最大的深度学习模型,最终生成了一张猫脸。
虽然这张猫的图片看起来非常模糊,而且耗时又非常久,但对当时的计算机视觉来讲具有重要突破意义的尝试,开启了AI绘画研究的全新方向。
为什么当时基于深度学习模型的AI绘画那么麻烦?主要是整个模型需要利用大量标注好的训练数据,根据输入和所对应的预期输出,不断地调整模型内部的参数进行匹配。例如生成一张512*512 *3(RGB)的画,要将这些像素有规律的组合,会涉及到庞大参数迭代调整的过程。

2. 2015年文生图重要的拐点
2015年出了一项人工智能的重大进展——智能图像识别。机器学习可以对图像中的物体贴上标签,然后将这些标签转化成自然语言描述。
一些研究人员产生了好奇,如果把这个过程反向,通过文字来生成画面,是否也能实现呢?
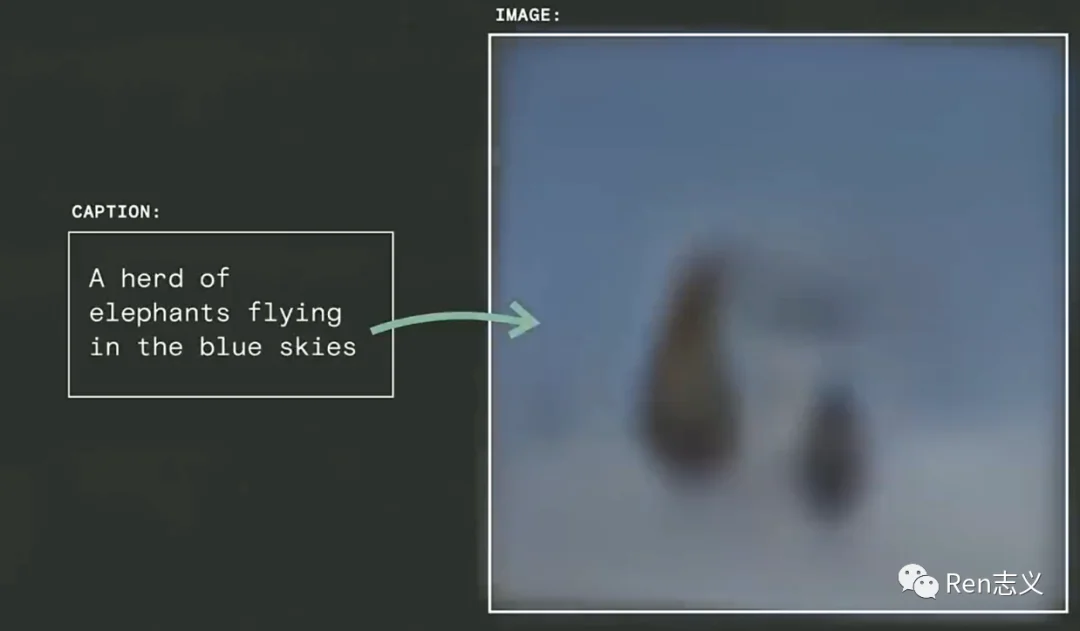
于是他们向计算机模型输入了一些文字,看看能产生什么原因,结果模型真的生成了一些结果图片。如下图中所示,这时产生了32*32像素的小图片,基本很难辨别出啥,但已经预示着无限的可能性。
3. 2021年OpenAI宣布Dalle
2021年年初,OpenAI发布了引发巨大关注的DALL-E系统,但DALL-E的绘画水平还是很一般,之所以引发关注,是因为他实现了输入文字就可以绘画创作的可能,比之前生成的图片质量高很多。

4. 2022年开启AI绘画的元年
2月 Disco diffusion V5发布
在2022年的2月,由somnai等几个开源社区的工程师做了一款基于扩散模型的AI绘图生成器——Disco diffusion。从它开始,AI绘画进入了发展的快车道,潘多拉魔盒已经打开。
越来越多的人开始使用Disco diffusion创作作品,但是它有一个致命的缺点就是它生成的画面都十分的抽象,这些画面用来生成抽象画还不错,但是几乎无法生成具象的人。
由于生成速度较慢,操作复杂、生成的风格相对比较抽象, 目前使用的人没有Stable Diffusion 和Midjourney那么多。

3月 Midjouney
Midjouney选择搭载在discord平台,借助discord聊天式的人机交互方式,不需要之前繁琐的操作,也没有Disco diffusion十分复杂的参数调节,你只需要向聊天窗口输入文字就可以生成图像。更关键的是,Midjouney生成的图片效果非常惊艳,普通人几乎已经很难分辨出它产生的作品,竟然是AI绘画生成的。
4月 DALL·E 2
4月10日,之前提到过的OpenAI推出的第二代图像生成人工智能模型DALL·E 2。与第一代DALL-E相比,DALL-E 2在图像质量、生成速度和多样性等方面都有显著提升。影响力不及Chat GPT,个人消费者对他没有那么喜欢,因为他生成的图片的风格更倾向于更一本正经,比较传统一些。

7月 Stable diffusion
7月29日 一款叫Stable diffusion的AI生成器开始内测,人们发现用它生成的AI绘画作品,其质量可以媲美DALL·E 2,而且还没那么多限制。
Stable diffusion内测不到1个月,正式宣布开源,开源让AI绘画技术的普及,也是让领域能有更多人开发贡献,加快技术的应用发展。
二、AI绘画的底层原理
AI绘画的根源来源于人工神经网络,科学家受人类神经元启发,设计出的人工神经网络长下面这样。
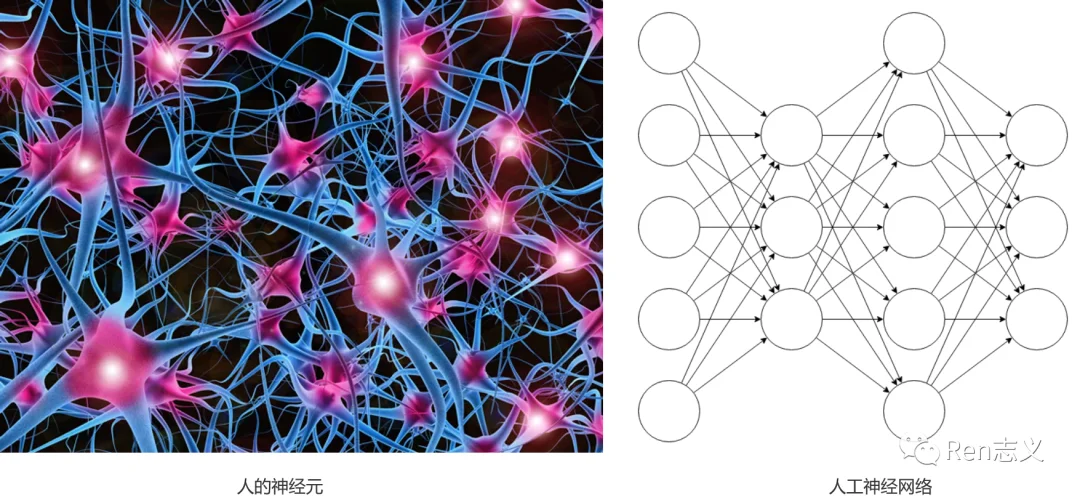
神经网络都是用数学公式表示的,没有实体结构,图里面的这些圈和连线是对神经网络的一种可视化呈现,方便我们理解。
这图中圆圈里都有一个计数器,当这个计数器接收到左边连线传来的数时,会进行一次简单的计算,然后把计算结果(也是一个数)输出,通过连线传给右边的圆圈,继续重复类似的过程,直到数字从最右侧的圆圈输出。
人类的不同神经元之间连接的强度是不一样的,有些粗一点,有些细一点。正是这些连接强度,让我们产生了记忆和知识。
对于神经网络来说,也有相似的规律:圆圈和圆圈之间的连线的“权重”不同。
神经网络左侧输入一些列数字,神经网络会按照圆圈里的计算规则及连线的权重,把数字从左到右计算和传递,最终,从最右侧的圆圈输出一系列数字。
那如何让神经网络画一幅画?

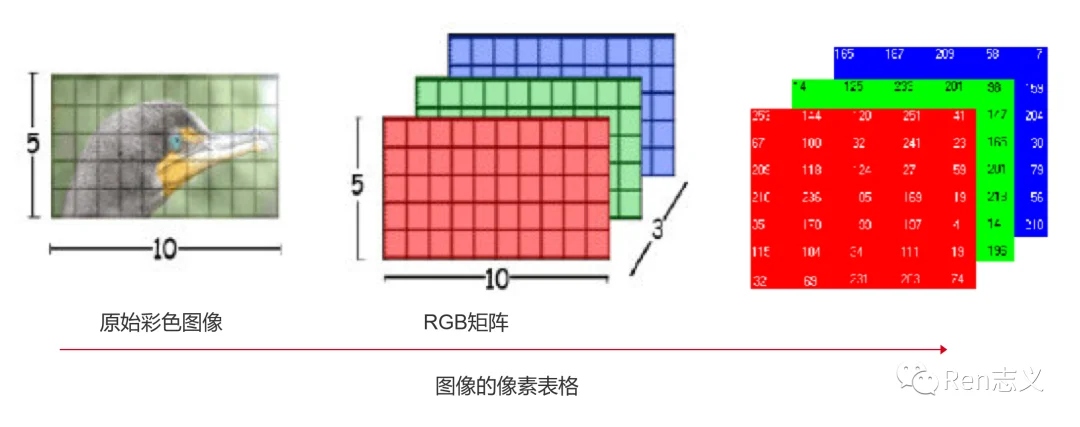
原理其实比较好理解,首先需要将图片转化成计算机能理解的数字语言,对于计算机而言图片就是一串数字,每个像素颜色由3个RGB数值表示。
然后将一串数字输入到没有训练过得神经网络模型,也会生成一串数字,只不过解码后可能就是一张乱码图片,所以需要大量数据和不断调整算法参数的权重,最终训练一个能画猫的模型。例如当输入图片猫或文字猫,都能转化成一串数字到模型中,输出一个正确的猫图片。
图像生成模型是在不断演化的,从最早的VAE到风靡一时的GAN,到当今的王者Diffusion模型,那我们接下来介绍下不同模型的技术原理是什么。
三、主流的图像生成模型解析
1. VAE — 打开生成模型的大门
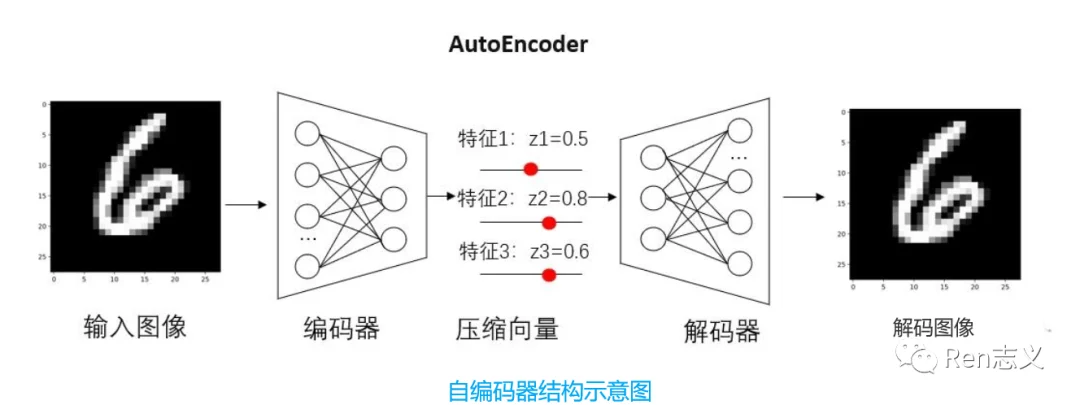
VAE是AE的升级版本,AE由一个编码器网络和一个解码器网络组成。编码器将输入数据映射到潜在空间中的隐变量表示,解码器则将隐变量映射回重构的数据空间。
如上图,假设有一张图像,通过编码器提取了多种特征,比如特征1字体颜色、特征2字体粗细、特征3字体形状。传统的自编码器对输入图像的潜在特征表示为具体的数值,比如颜色=0.5,粗细=0.8,形状=0.6。这些数值通过解码器恢复出于原图像相似的图像。
那这样的模型解决什么问题呢?
主要应用在降维/可视化和去噪的场景中。
我们生活存在大量的文本、图像、语音数据,这些数据存在大量的冗余信息,理论上是可以用极少的向量来表示,所以可以用来图像压缩处理,这跟传统的图像压缩技术完全不一样。后面讲到的stable diffusion 模型就用到AE的潜空间来进行低维度的降噪和生成真实图像。
在应用场景中也能发现,他仅适合用于重建图像,不适用于生成新的图像,所以有了VAE的诞生。
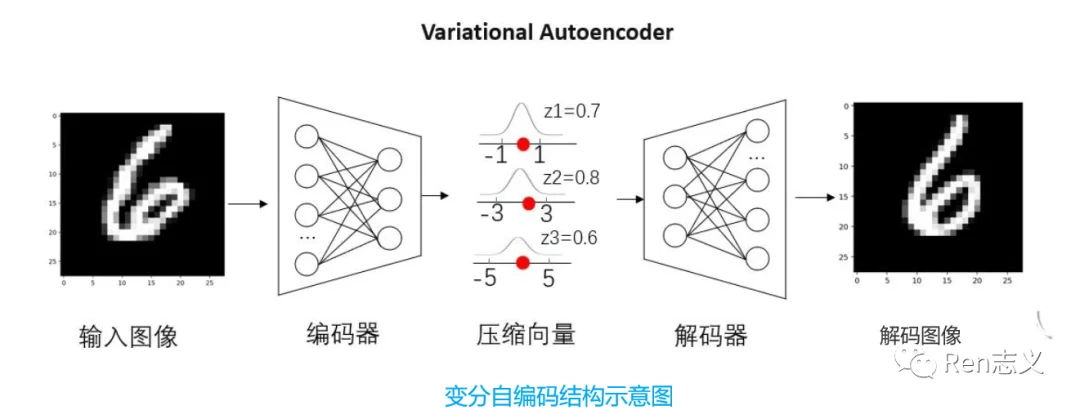
VAE与AE的区别在,VAE在编码器输出的分布曲线值,而非离散值,这样的话输入的图像就跟压缩向量就不是直接对应关系,这样就可以生成新的图像。
如上图,我们将每个特征通过概率分布进行表示。比如颜色的取值范围为[-1,1],粗细的取值范围为[-3,3],形状的取值范围为[-5,5]。我们可以在范围内对每个特征进行取值,然后通过解码器生成新图像。例如给一张人脸可以生成不同表情的人脸。
VAE不仅除了应用在压缩、去噪和生成新的图像也可以应用在图像分割上,例如自动驾驶的道路检测。
但VAE生成图像存在局限性,生成图像的质量不高,存在模糊和不真实。

2. GAN — 创建“以假乱真”的新数据
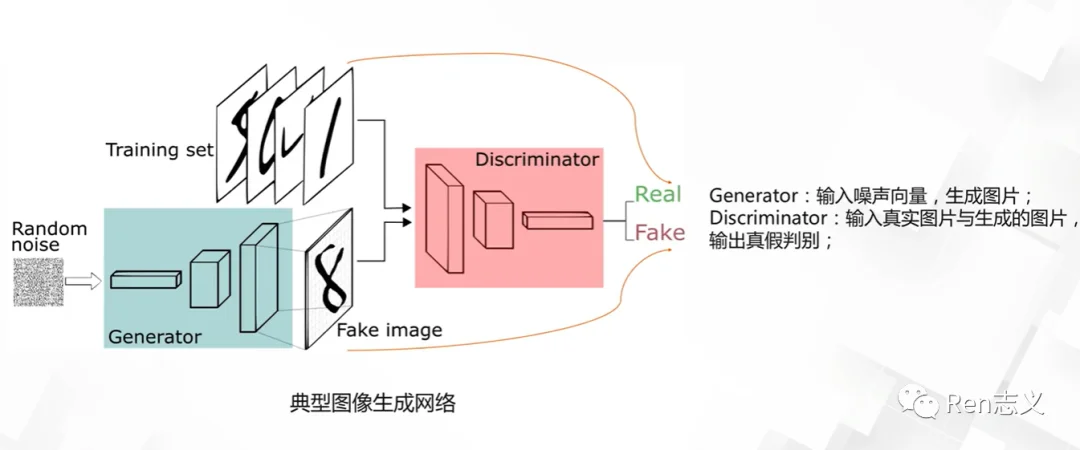
GAN包含了两个模型,生成模型(Generator)和判别模型(Discirminator),给生成模型随机输入噪声,生成图片;给判别模型输入真实数据和生成的图片,判别生成的图片是真的还是假的。
刚开始生成器生成的图片给判别器,判别器一看就是假的,打回去让生成器重新生成,同样判别模型也要提升自己的判别水平,经过无数次的对抗,直到生成模型生成的图片骗过判别模型。
GAN的应用场景有哪些?
GAN的应用场景非常广泛,在图像生成,生成不存在的人物、物体、动物;图像修复、图像增强、风格化和艺术的图像创造等。不一一列举,想要详细了解的可以看链接:
https://zhuanlan.zhihu.com/p/75789936
曾经大红大紫的GAN为什么会被Diffusion取代?
1.GAN的训练过程过程相对不稳定,生成器和判别器之间的平衡很容易打破,容易导致模型崩溃或崩塌问题;
2.判别器不需要考虑生成样品的种类,而只关注于确定每个样品是否真实,这使得生成器只需要生成少数高质量的图像就足以愚弄判别者;
3.生成的图像分辨率较低;
因此,以GAN模型难以创作出有创意的新图像,也不能通过文字提示生成新图像。
3. Diffusion — 图像生成模型的皇冠
目前主流国内外靠谱的图片生成技术主要基本都是基于Diffusion Model (扩散模型) 来进行的实现,包括不限于 Stable Diffusion MidJourney 、 OpenAl DALL.E 、DiscoDiffusion、Google lmagen 等主流产品,但是实际技术在处理方面又各有区别,也导致会有不司的表现形态,核心一方面是底层模型训练的图语料不同,另外一个方面是一些算法方面的微调区别。
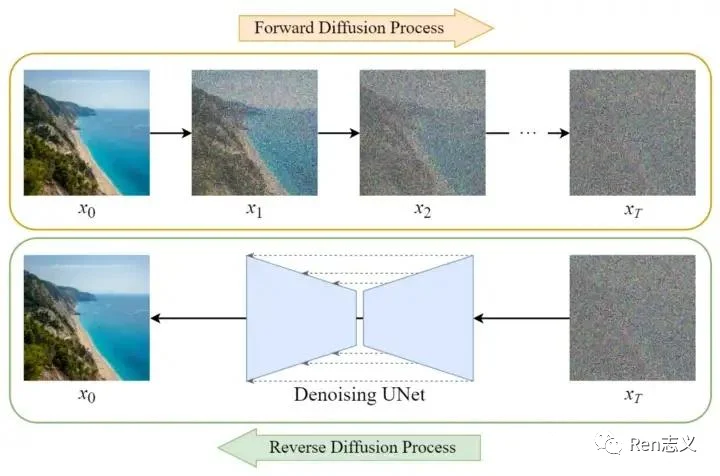
Diffusion模型生成图片的过程可以理解像是石雕的过程,从一块石头经过不断的雕刻变成一件艺术作品,从一个噪点图像不断去噪生成一张真实图像。
那扩散模型是怎么训练的?
Diffusion模型的训练可以分为两个部分:
- 前向扩散过程(Forward Diffusion Process) —— 向图片中不断添加噪声,直到图片变成完全的噪点图片的过程。
- 反向扩散过程(Reverse Diffusion Process) —— 是将噪点图片不断的还原为原始图片的过程。
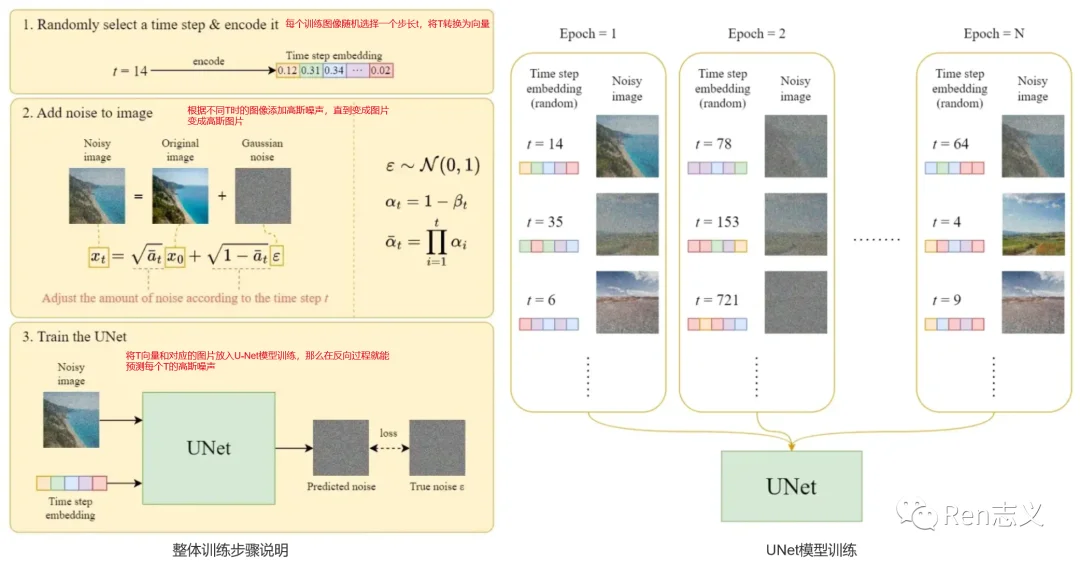
官方给出的有3个训练步骤,如下图:
- 对于每张图像先随机生成一个长T,T表示从一张原始图到高斯噪声图要多少次。
- 给原始图片添加T次高斯噪声,不同T时图像添加的噪声深度会有所不同。
- 将T和对应的图片放入到UNet模型中训练,这样还原图片就能预测T步骤中的噪声。
反向扩散训练过程步骤如下图:
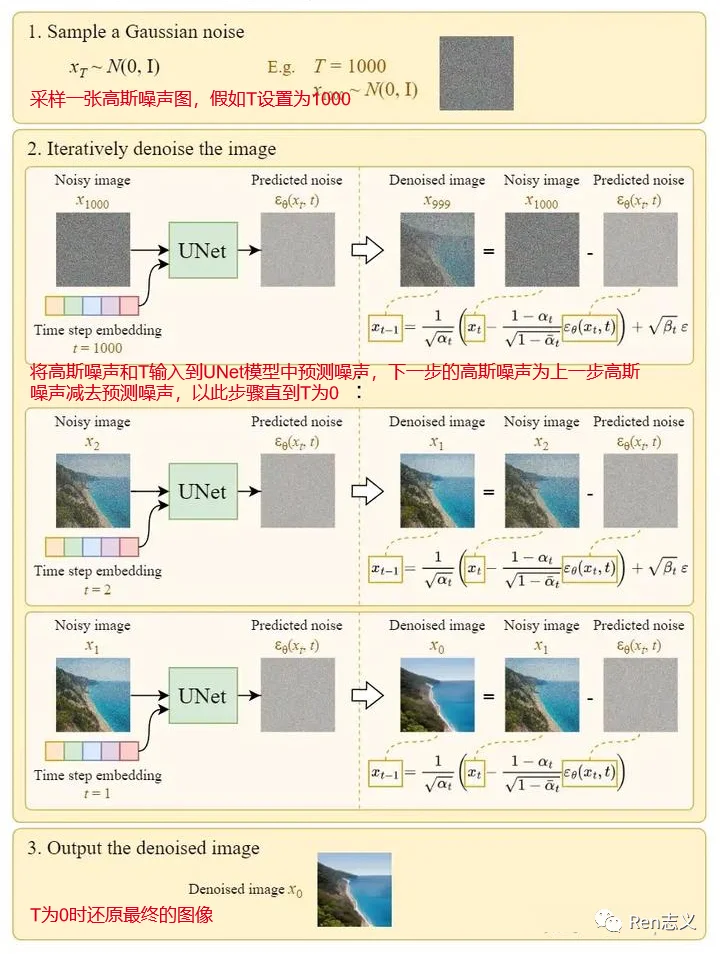
- 采样一张高斯噪声图,假如T设置为1000
- 将高斯噪声和T输入到UNet模型中预测噪声,下一步的高斯噪声为上一步高斯噪声减去预测噪声,以此步骤直到T为0
- T为0时还原最终的图像
Diffusion模型的大数据训练,数据训练来自于LAION-5B包含58.3文本-图像对,并且是筛选了评分高的图片进行训练。通过大数据模型训练,让模型具有生成图像的能力。有了生成图像能力还不够,需要能听得懂需求的能力,根据文字输入就能生成图像。
4. CLIP—打造图文匹配
CLIP是OpenAI在2021年开源的模型,一种基于对比文本-图像对的预训练方法或者模型,确保计算机在文字描述和图像之间形成互通。
在CLIP推出一年后,几个开源社区的工程基于CLIP+Diffusion就开发了Disco Diffusion,后面的midjourney和stable diffusion模型都有使用CLIP模型。
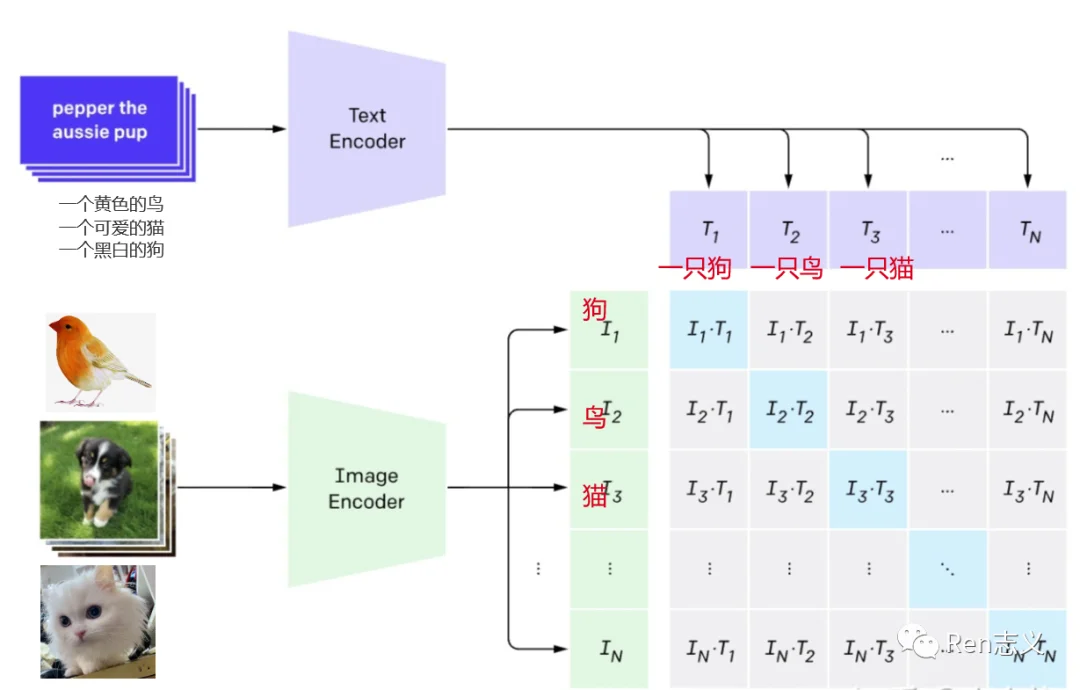
据统计,CLIP模型搜集了网络上超过4亿的“文本-图像”作为训练数据,为文本生成图像/视频应用的落地奠定了基础,实现了跨模态的创新。
以上图像生成相关的模型都以解析完,那我们拿Stable Diffusion 来进行梳理下整个图像生成的流程是怎么样和整体架构,其他图像生成模型大致也差不多。
5. Stable Diffusion 模型结构
Stable Diffusion主要有三部分组成,像素空间、潜在空间 、条件机制。
像素空间:使用的AE模型将图像压缩到潜在空间训练和将生成的低维向量转化成真实图像,这样提升生成速度和降低算力要求。
潜在空间:Diffusion模型在潜在空间进行加噪和去噪的训练,去噪的过程需要导入条件,生成符合预期图片。
条件机制:条件可以是文字、图像、音频、视频,将条件转化成向量值,作为Diffusion模型生成过程中的引导因子。
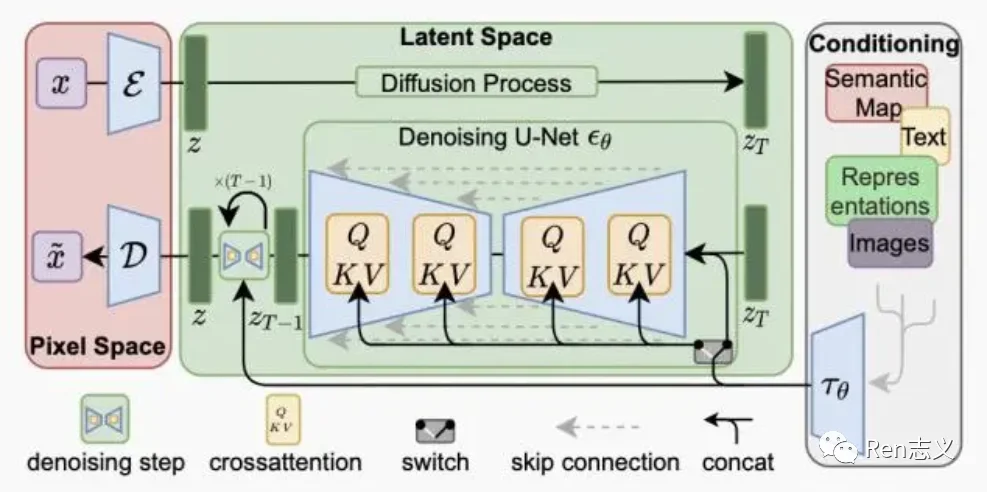
Stable Diffusion图像生成流如下:
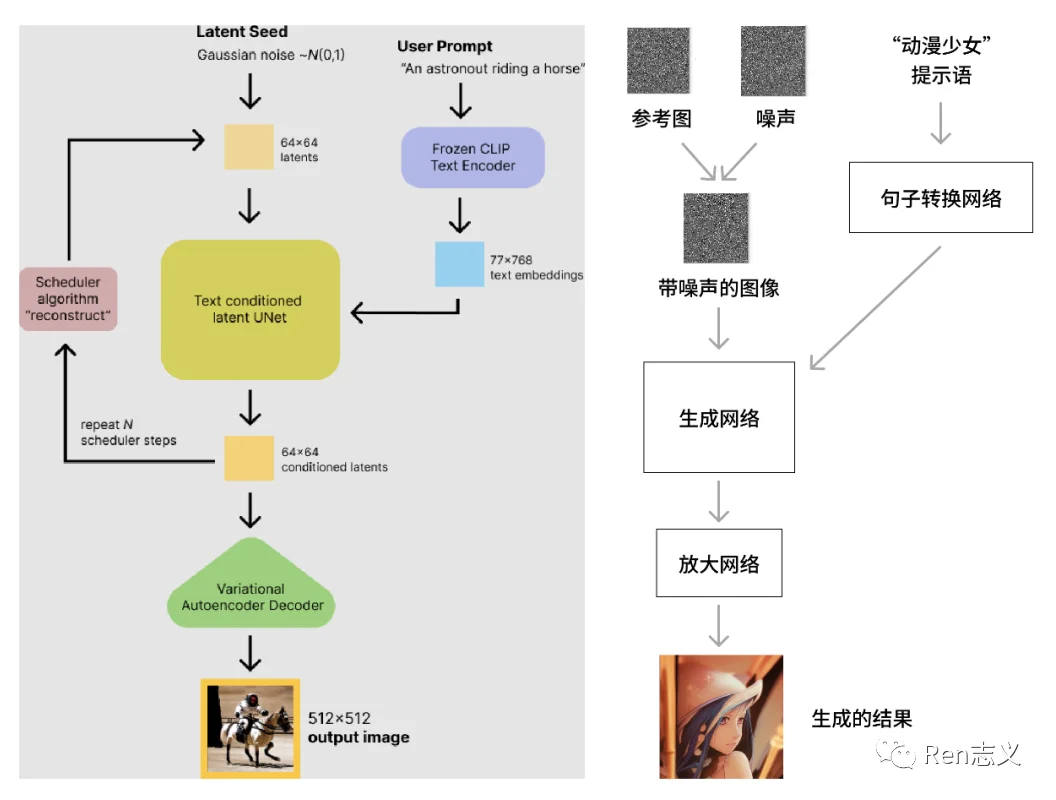
通过以上扩散模型原理大致也明白AI生成的图像带有较大的随机性,生成的每张图像都不一样,这种随机性带来的好处是无穷无尽的想象力,但同时也面临着不可控,有点靠运气,生成理想的图像只能多尝试。AI绘画想要扩大商业化落地,必须要解决精准可控性问题。
四、AI绘画的可控性有哪些
除了输入文字、垫图的方式还最流行的微调模型叫Lora和最近几个月更新的Controlnet来控制图片的生成,这几个小模型可以理解为Stable Diffusion的一种插件。
1. Lora模型
在不修改SD模型的前提下,教会利用少量数据训练出只可意会不可言传的风格,实现定制化需求,对算力的要求不高,模型适中在几十MB大小。
Lora 必须搭配在SD模型上一起使用。
Lora可以自己训练也可以在著名的模型分享网站https://civitai.com/上下载,有大量Lora模型,其中SD模型仅有2000个,剩下4万个基本都是LoRA等小模型。
例如想要生成下面风格的汽车,我们找到这款不同角度的一些图片作为Lora训练。生成汽车的风格跟想要风格汽车很相似。
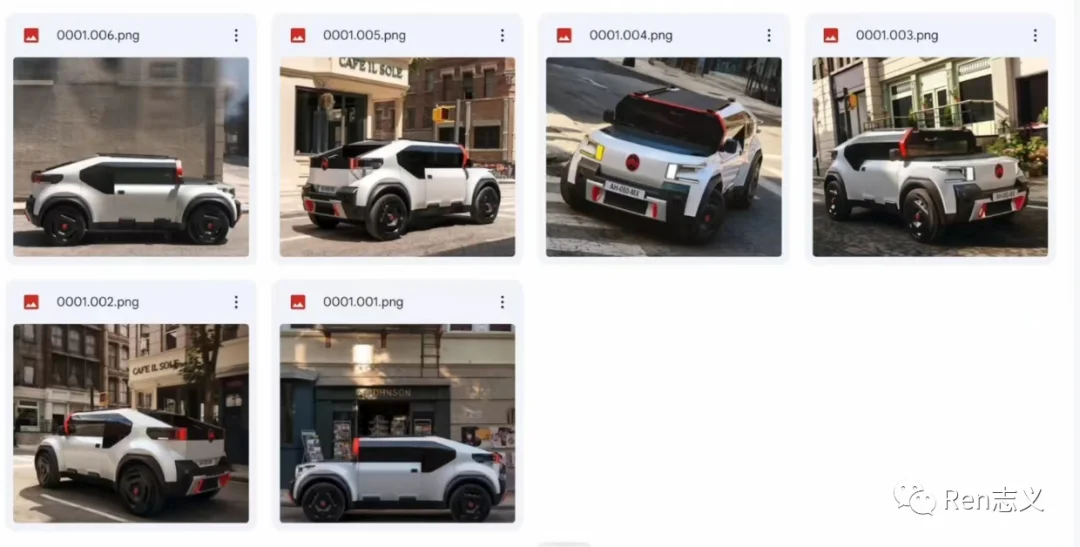

微调模型不止有Lora 模型,还有Textual Inversion、Hypernetwork、Dreambooth。只是Lora 模型比较稳定,使用门槛相对低,所以目前比较流行。
2. Controlnet模型
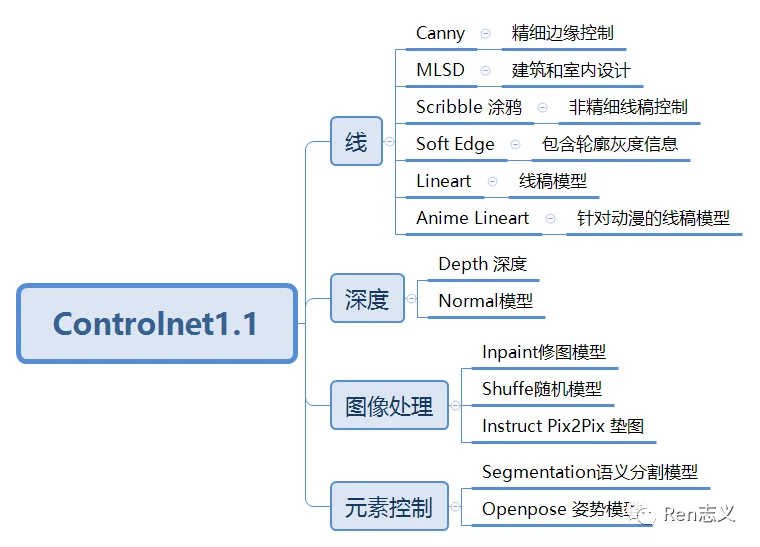
Controlnet就是控制网的意思,其实就是在大模型外部通过叠加一个神经网络来达到精准控制输出的内容。很好的解决了单纯的关键词的控制方式无法满足对细节控制的需要,比微调模型更进一步对图像生成的控制。
想要对Controlnet有更详细的了解可查看如下链接:
https://zhuanlan.zhihu.com/p/625707834
https://mp.weixin.qq.com/s/-r7qAkZbG4K2Clo-EvvRjA
https://mp.weixin.qq.com/s/ylVbqeeZc7XUHmrIrNmw9Q
五、AI绘画的技术研究趋势
1. 更强的语义理解
使用AI绘画生成高质量、精美的生成图像需要在在prompt做很多努力,可见prompt对最终效果的影响。因此,如何降低用户使用prompt的门槛,让AI更能理解语义,值得研究的方向。
2. 更精准可控生成
目前可控生成是一个大火的领域,也有像ControlNet这样的精品,可以通过输入简单的线稿图、人体姿态图、分割图、深度图等生成满足条件的内容,但距离真正的精准控制仍有差距。可喜的是,可控生成发展得越来越快,精准控制并不是遥不可及,图像生成AI也会随之拓展其应用边界,如一致性的视频生成、精确的构图设计都会改变许多领域的工作方式。
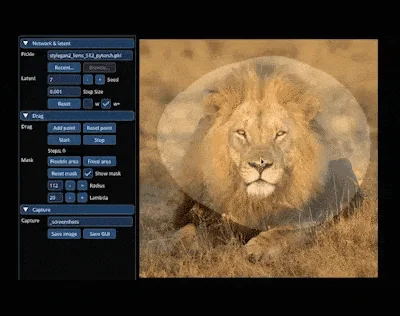
最近,来自马克斯・普朗克计算机科学研究所、MIT CSAIL 和谷歌的研究者们研究了一种控制 GAN 的新方法 DragGAN,能够让用户以交互的方式「拖动」图像的任何点精确到达目标点。
这种全新的控制方法非常灵活、强大且简单,有手就行,只需在图像上「拖动」想改变的位置点(操纵点),就能合成你想要的图像。

3. 运算速度更快
影响Diffusion在生成图片的速度除了显卡的性能,很重要一个原因是,每生成一张图片需要去噪1000次,速度相对还不是很快,为了能在解决这个问题,OpenAI曾在3月发布了一篇重磅、且含金量十足的论文「一致性模型 Consistency Models」,在训练速度上颠覆了扩散模型,能够 『一步生成』 ,比扩散模型更快一个数量级完成简单任务,而且用到的计算量还要少10-2000倍。
以上就是从图像生成技术里程事件到对图像生成技术的科普以及未来的发展趋势分析,我相信通过以上内容很容易就理解了AI绘画背后的技术。下一篇对AI绘画产品商业化落地进行分析。
本文由@Rzhiyi 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。提供信息存储空间服务。





