

下面开始进行参数的设置。如图,从WebUI界面的左到右开始设置。
源模型和目录参数设置
先选择源模型,这里选择Stable Diffusion V1.5模型。
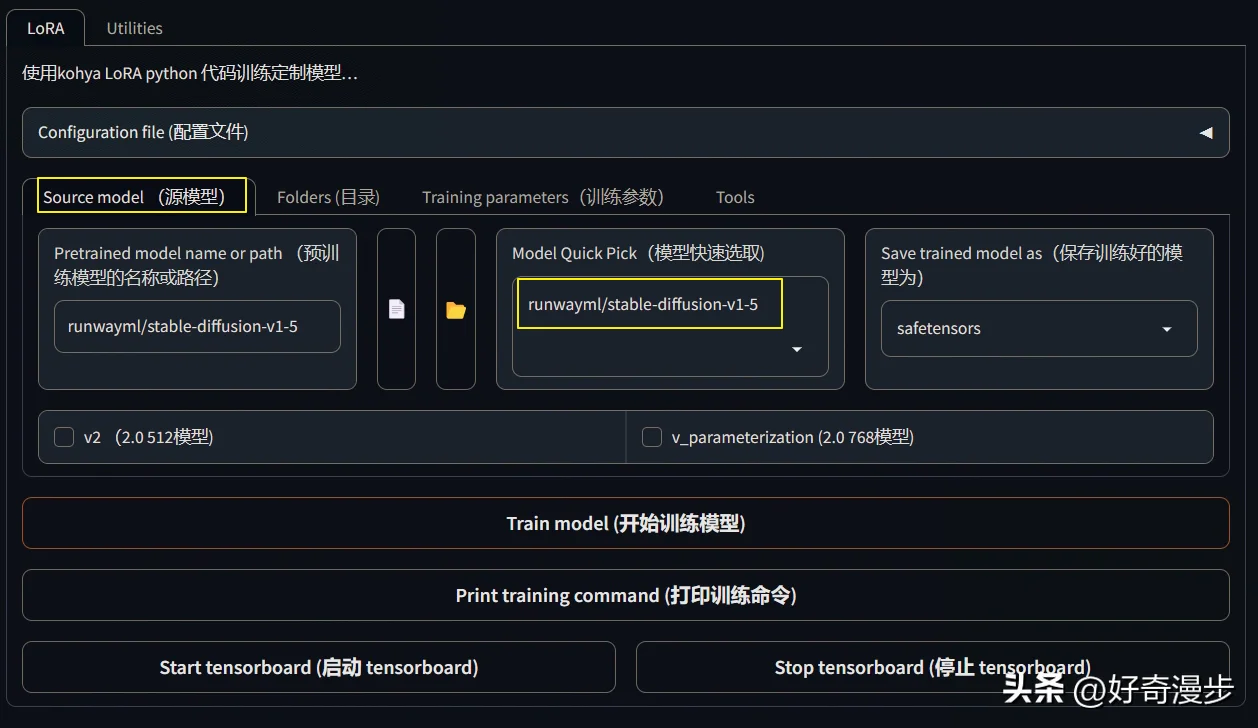
如下图,根据log(存放日志)、model(存放训练生成的LoRA模型)设置好目录地址。
注意:训练图片目录为图片集目录的上一层目录!举例说明:比如上面把50_xunxian文件夹存放到xunxian文件夹中,则目录为xunxian文件夹!而不是50_xunxian文件夹!切记切记!
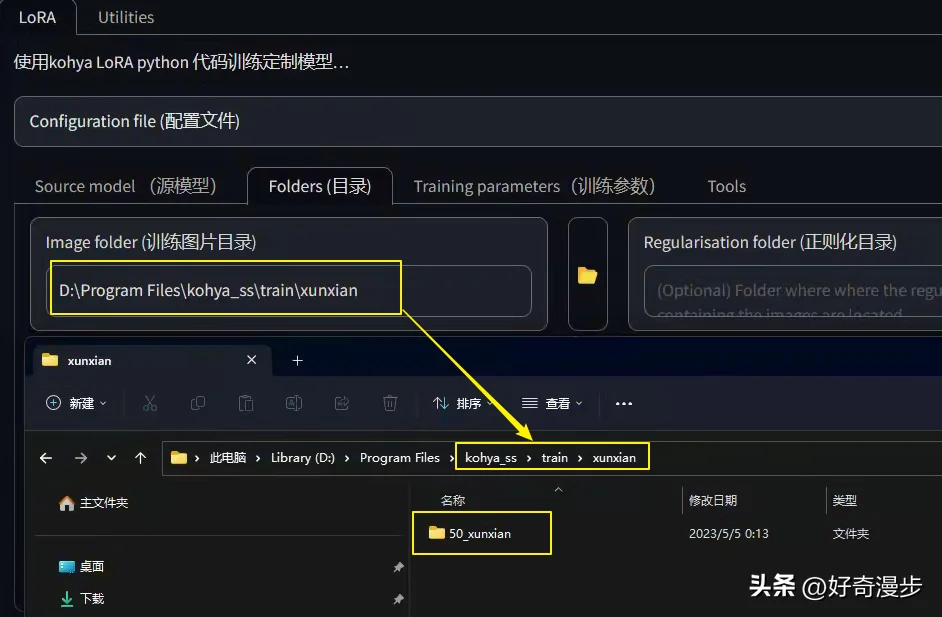
然后设置好模型保存的名字。
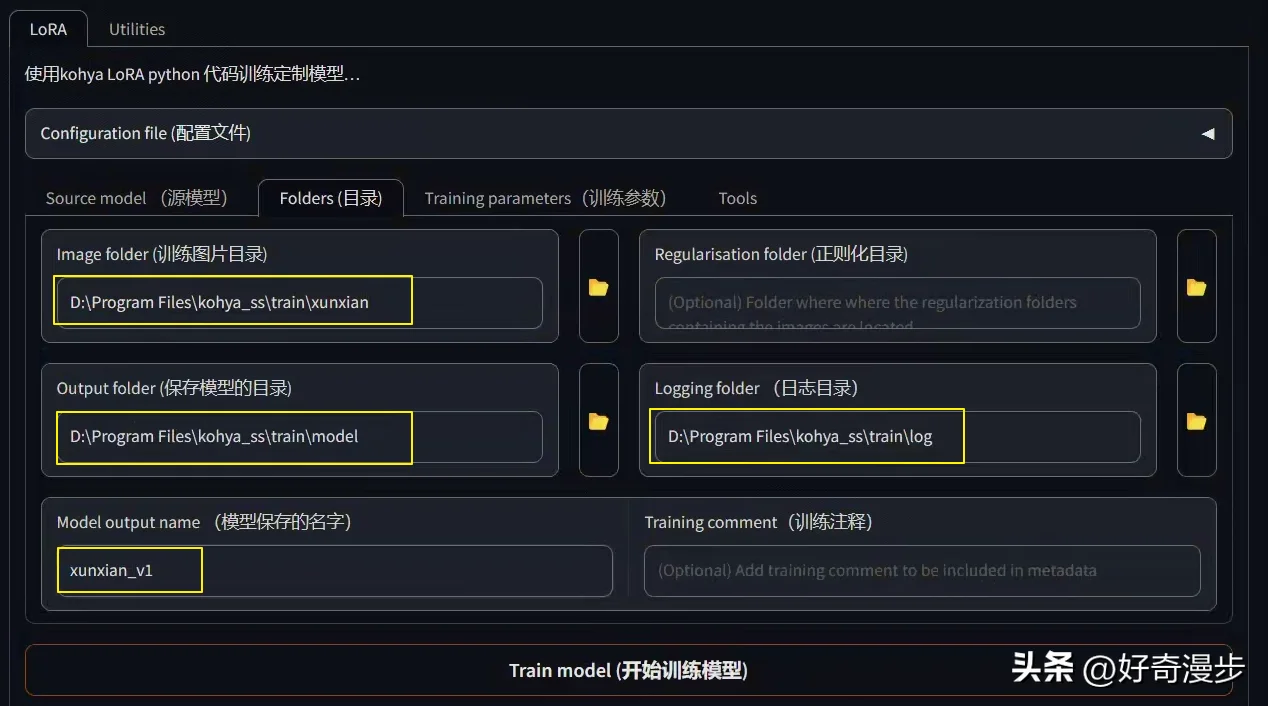
训练总步数公式
训练前我们需要知道一个训练总步数的公式:
Total Steps=Repeat*Image*Epoch/Batch_size
//训练总步数=每张图片的重复次数(训练步数)*图片数量*训练轮次÷批量大小(并行数量)总步数控制在1000到2000步,下面分别说说公式中的各个参数。
Repeat:每张图片的重复次数(训练步数),只可以在文件夹命名的时候指定,也就是图片集文件夹的命名为“数字_名字”,这个数字便代表Repeat值!所以在上期的教程中,文件夹的命名格式才那么重要,如图所示。
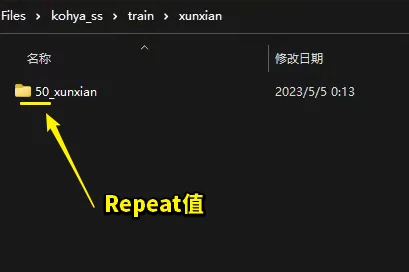
Image:很好理解,也就是准备的图片集文件夹中图片的数量,一般为20-50张。
Epoch:训练的轮次,也就是所有图片训练完为1轮,从头在训练2轮、3轮……,这里一般建议训练5-10轮。
Batch_size:并行数量、批处理大小,也就是一次处理几步。数值的多少取决于你的电脑显卡显存的大小,显存小(6G及以下)推荐写1,乖乖的一次只处理一步;显存大的显卡(12G及以上)可以根据情况而定,可以写2-6。当然并行处理的步数越多,则LoRA训练的速度越快!讲到这里也就不难理解上面公式为啥要除以batch_size这个数。
“Training parameters训练参数”设置
下面开始进行第三页面“Training parameters训练参数”的设置,这也是本篇文章的重点。
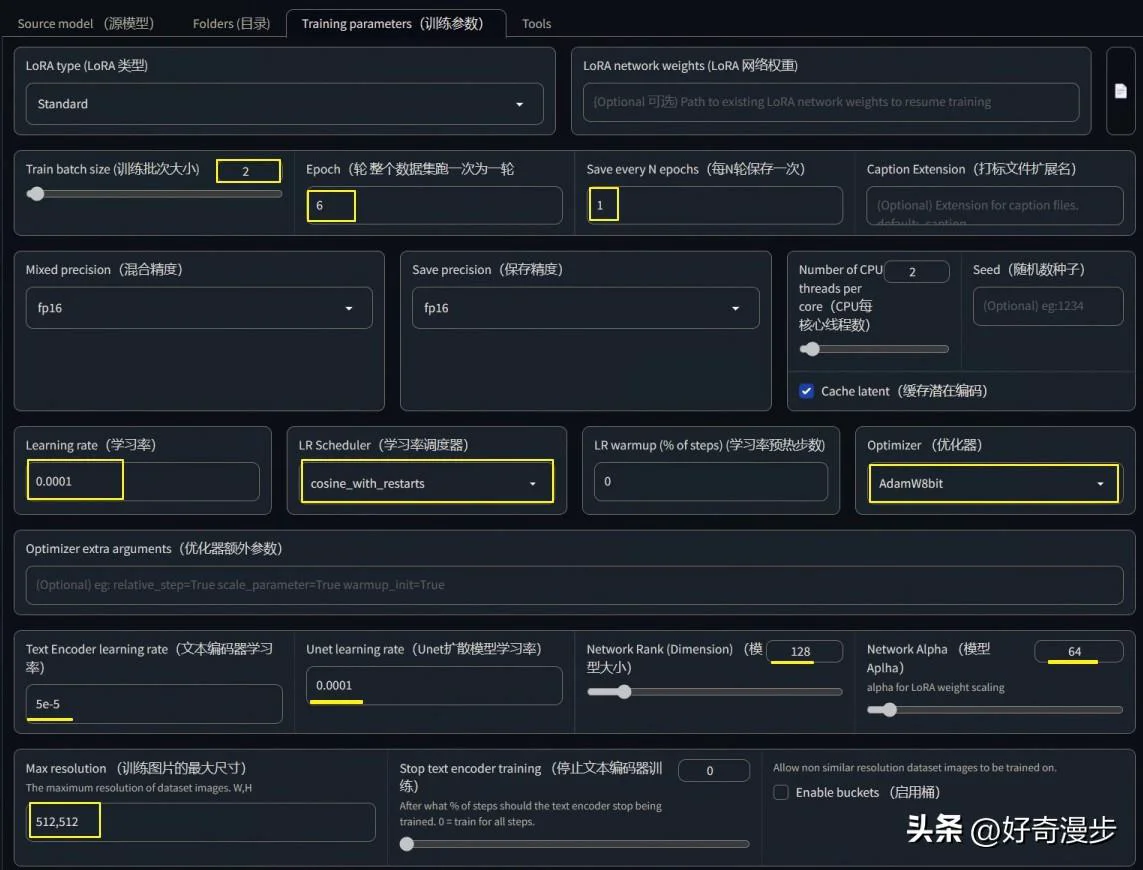
如上图,一般设置这些标记出来的参数。
Batch_size,并行批处理个数、一次处理的步数,根据自己显存大小来设置,显存小写1,显存大可以写2到6。
Epoch,训练的轮次,一般写5到10。
Save every N epochs,写1则每训练一轮便保存一次LoRA模型,比如:如果前面Epoch设置5轮,这里写1,则最后训练完成可以得到5个LoRA模型。
Network Rank(Dimension)维度,代表模型的大小。数值越大模型越精细,常用4~128,如果设置为128,则最终LoRA模型大小为144M。一般现在主流的LoRA模型都是144M,所以根据模型大小便可知道Dimension设置的数值。设置的小,则生成的模型小。
Network Alpha一般设置为比Network Rank(Dimension)小或者相同,常用的便是Network Rank设置为128,Network Alpha设置为64。
Max resolution,训练图片的最大尺寸,根据自己图片集的最大分辨率填写。如果图片集里的图片分辨率大小不一,可以勾选右边的“Enable buckets 启用桶”。
下面是学习率和优化器的设置,比较重要,我们要单独来说说。
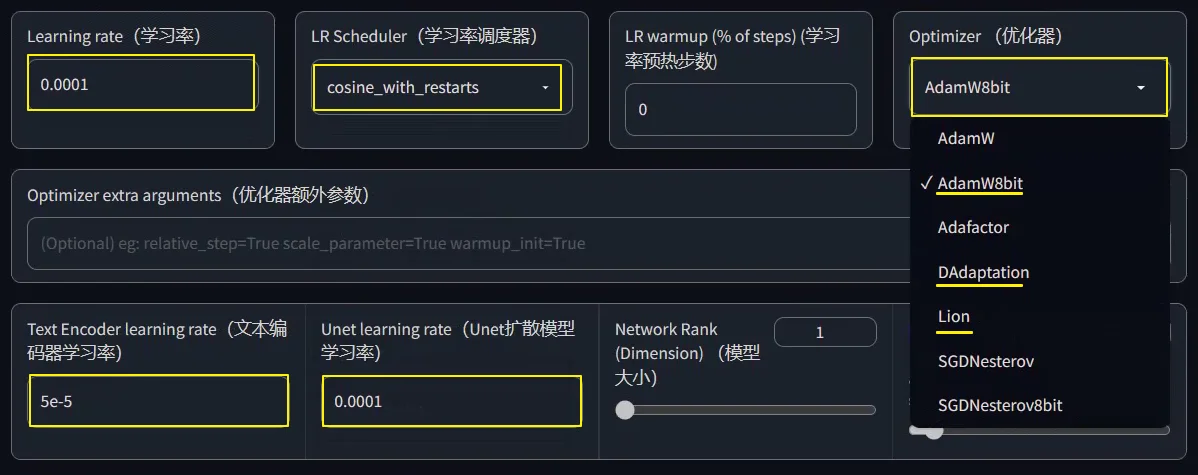
Optimizer(优化器),默认会使用AdamW8bit(下面会讲其他几个优化器),在AdamW8bit优化器时,学习率的设置参数如图所示。
Learning rate(学习率),可以理解为训练时Ai学习图片的速率。学习率大,则训练的快,但是容易“一目十行”,学的不够细致精确。反之,学习率小,则训练的慢,但是学的比较细致精确。默认值为0.0001,也可以写为1e-4。
Unet learning rate(Unet扩散模型学习率),设置此参数时则覆盖Learning rate(学习率)参数。默认值为0.0001,也可以写为1e-4。
Text Encoder learning rate(文本编码器学习率),一般为Unet learning rate的十分之一或者一半,比如设置为5e-5(1e-4的一半则为5e-5,十分之一则为1e-5)。
LR Scheduler(学习率调度器),理解为训练时候的调度计划安排,默认为constant(恒定值),常用cosine_wite_restarts(余弦退火)。
余弦退火算法(Cosine Annealing)是一种常用的优化算法,它是一种让学习率从一个较大的值开始,然后以余弦函数的形式逐渐减小的算法。它可以帮助模型更快地收敛到最优解,且具有良好的优化性能。此外,余弦退火算法还可以更好地改善模型的泛化能力,即模型在未见过的数据上的表现。
DAdaptation优化器求最优学习率方法
tips:看完全文再来看这里最佳!
此外,我们还可以通过DAdaptation优化器来找到最优的学习率,如下图所示设置即可。
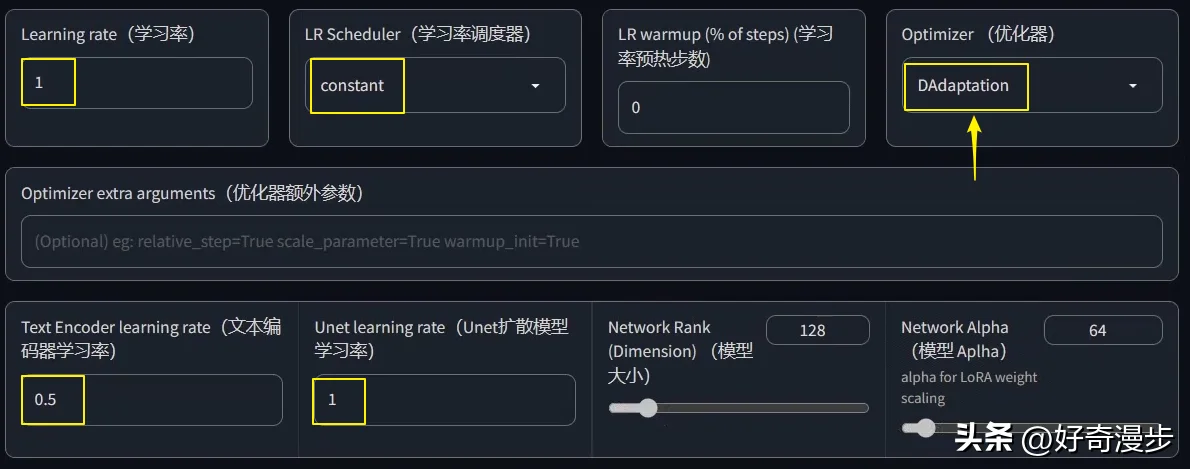
其他设置(指的是看完上下文的所有设置)都设置完毕后,点击Train model(开始训练模型)按钮,则开始进行LoRA模型训练。训练启动后,我们点击Start tensorboard,进入数据看板,这里记录了训练过程的一些可视化数据。
点击左上角SCALARS,然后找到左下角的lr数据图表,看到DAdaptation优化器会快速的到达一个恒定的学习率(一条直线),则这个学习率便是最优学习率(这里求得的值是3.3e-5)。
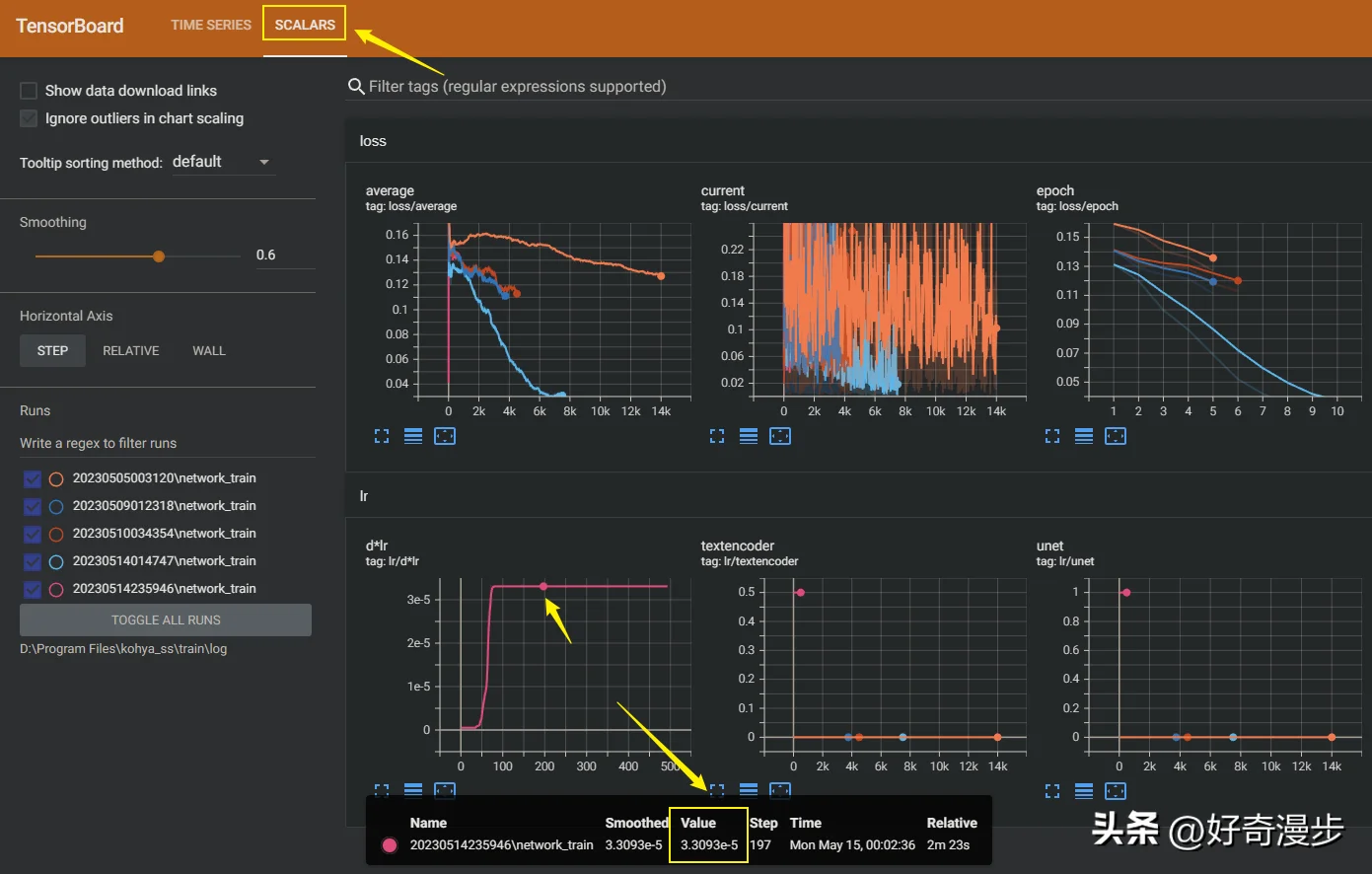
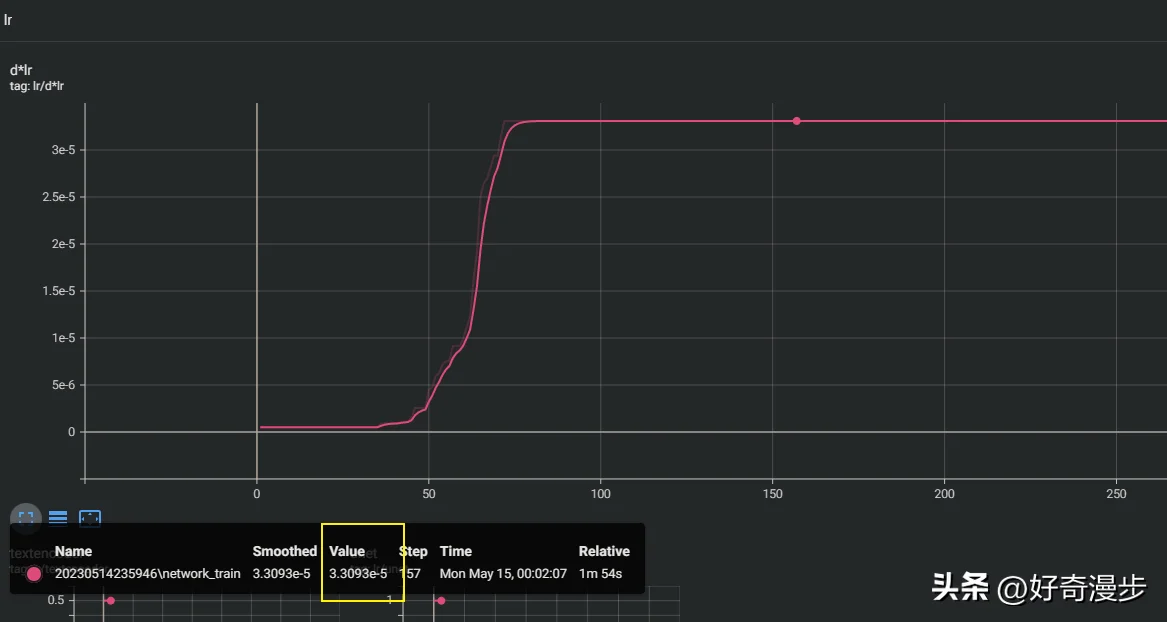
lr放大图
我们再回到学习率设置页面,把优化器改为AdamW8bit,把求得的最优学习率(这里以求得的3.3e-5为例)填入Unet learning rate处,其他值和设置根据上面的规则依次填入,如图所示。这样,一个合理的数值便设置好了。
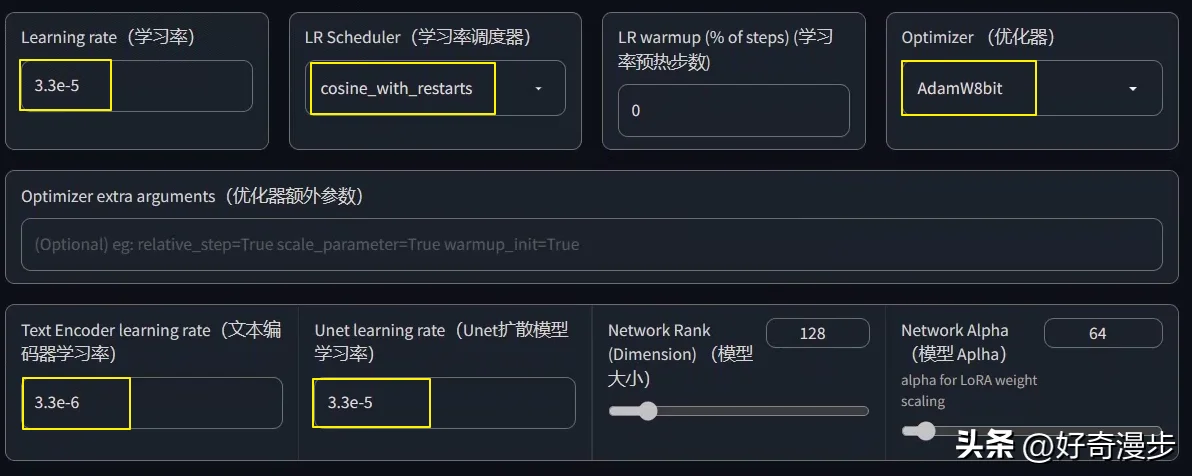
注意:如果使用Lion优化器,则学习率要改为DAdaptation优化器找到的最优学习率的三分之一。
“Training parameters训练参数”高级设置
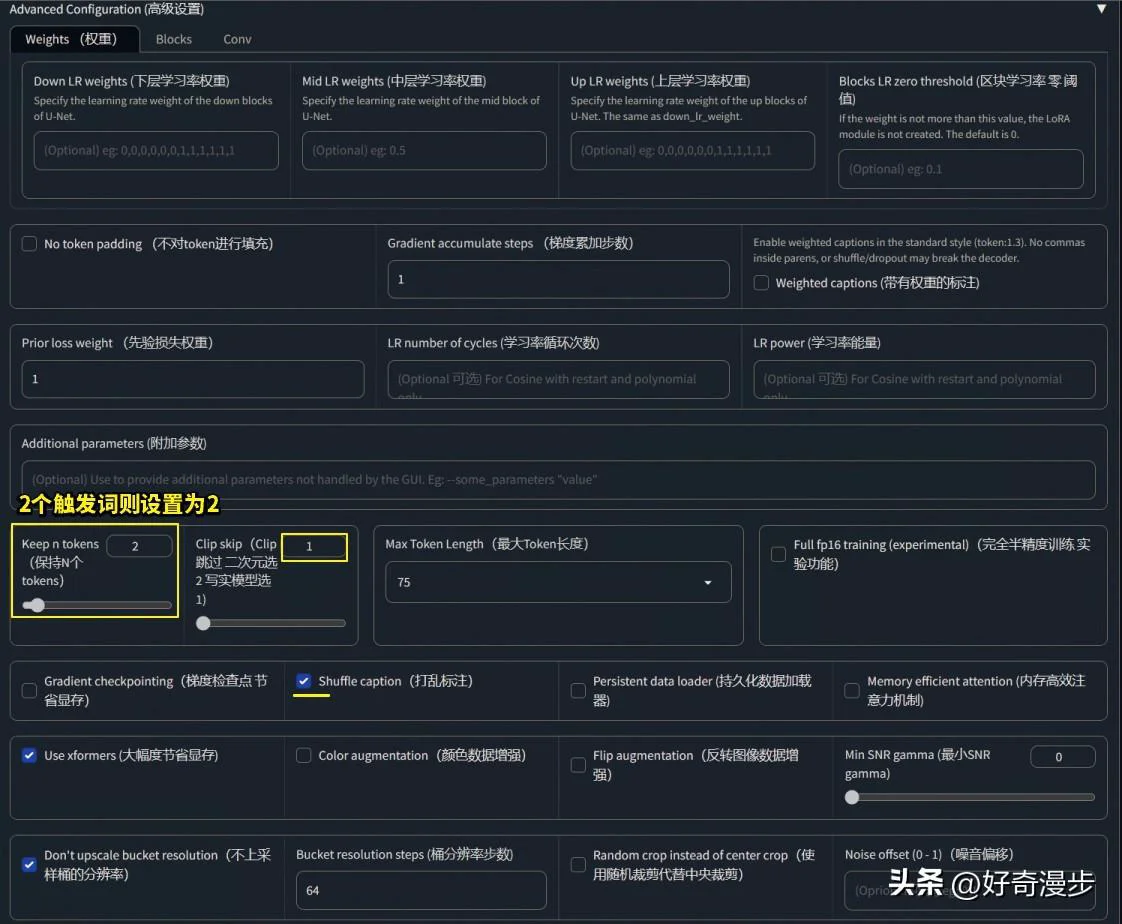
如上图,这里面需要设置的部分不多。
Keep n tokens(保持N个tokens),这个参数是用来设置触发词数量的。在前面提示词打标的时候,你为你的LoRA模型设置了几个触发词,这里就填写几,常见的有1~3。
Clip skip,二次元模型选2,写实模型写1即可。
“Training parameters训练参数”采样图片配置
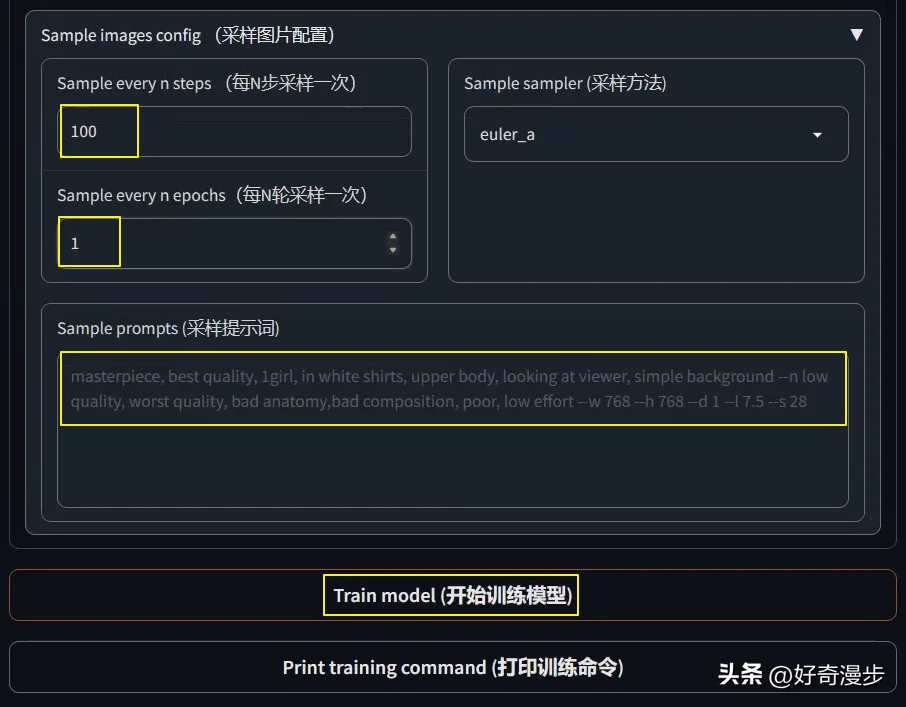
Sample every n steps,比如设置为100,则代表每训练100步采样一次。
Sample every n epochs,每N轮采样一次,一般设置为1。
Sample prompt(采样提示词),输入提示词,比如:masterpiece, best quality, 1girl --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28。
如上设置之后,LoRA训练的同时会每隔设定的步数或轮次,生成一副图片,以此来直观观察LoRA训练的进展。
开始训练模型Train model
以上参数设置完毕,点击Train model(开始训练模型)按钮,则开始进行LoRA模型训练。
点击开始后,一般WebUI界面上没有任何提示,我们可以切换到Powershell窗口观察训练是否开始。如下图,一般出现如下字样时,便代表训练开始了。
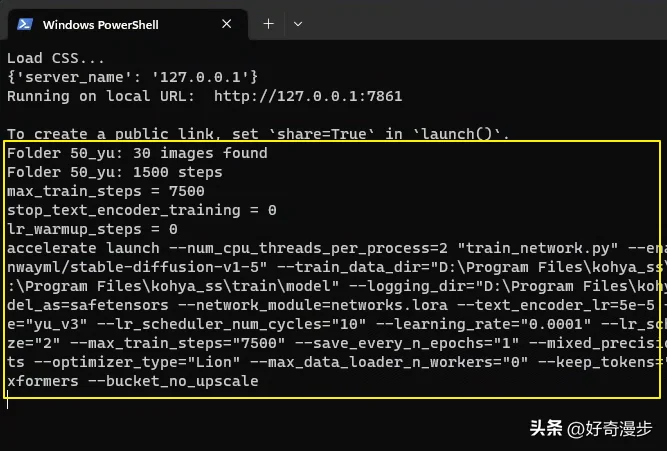
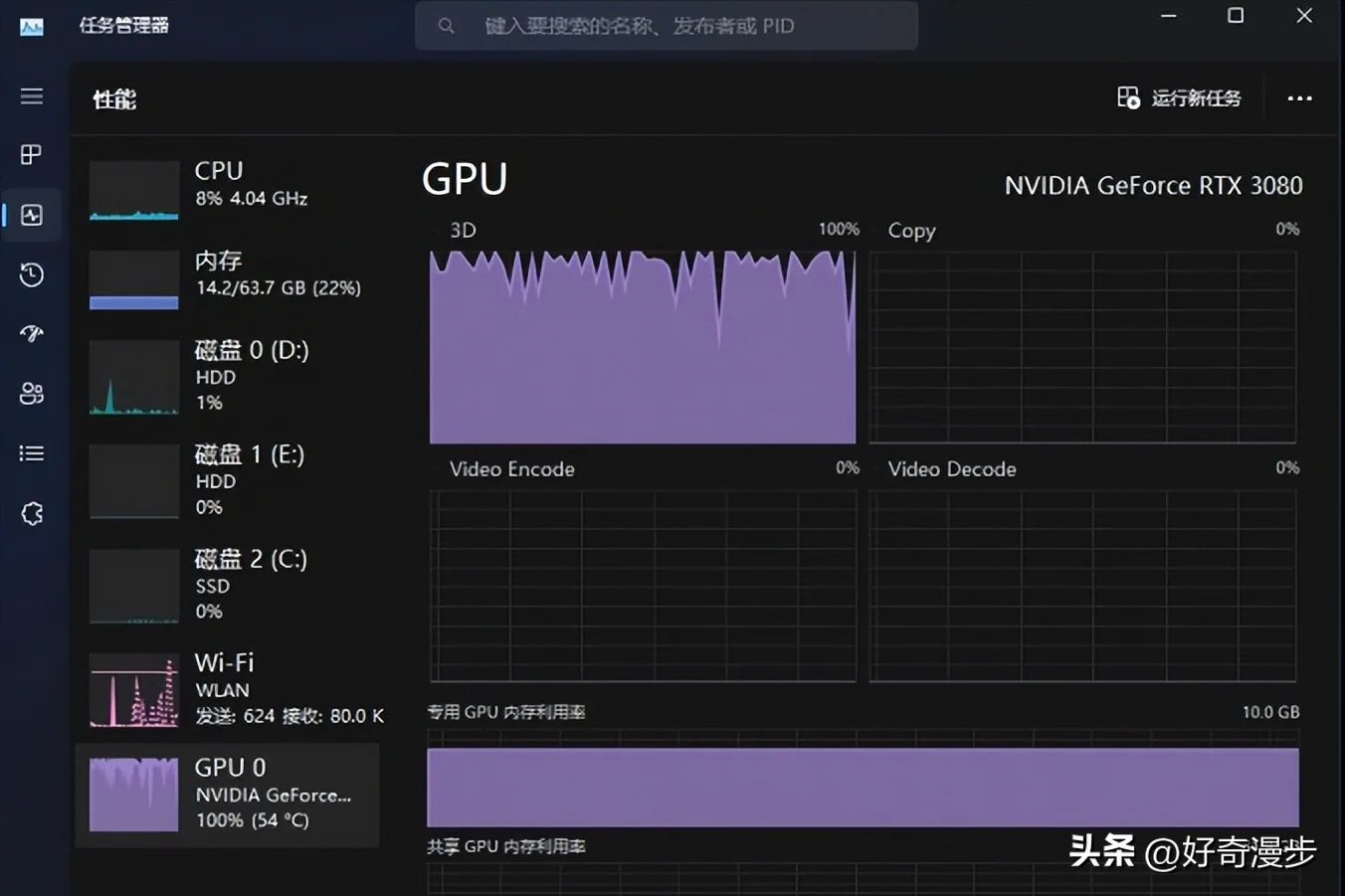
也可以查看任务管理器,观察GPU的状态图,如果显示100%,则代表训练进行中。
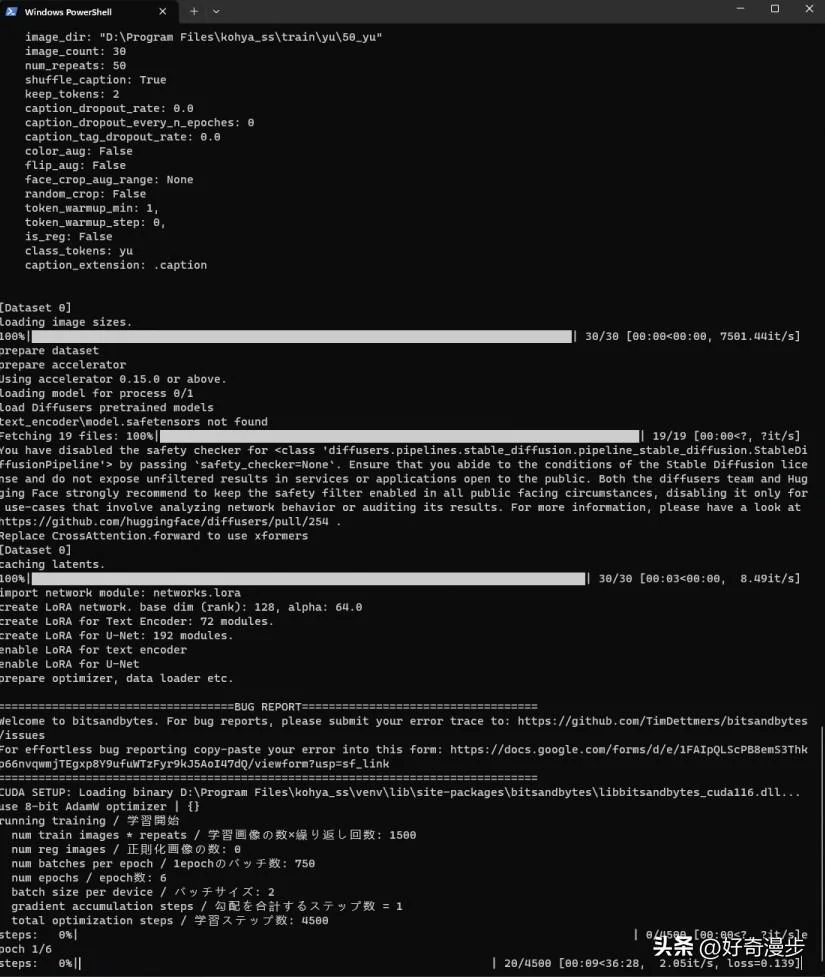
下图代表训练开始,steps:0%。
经过半个多小时,LoRA模型训练完成,训练时长根据参数设定和电脑性能而定。
训练完成后,我们查看Loss值,一般Loss值为0.08~0.1则模型训练的比较好,Loss值为0.08则最佳。
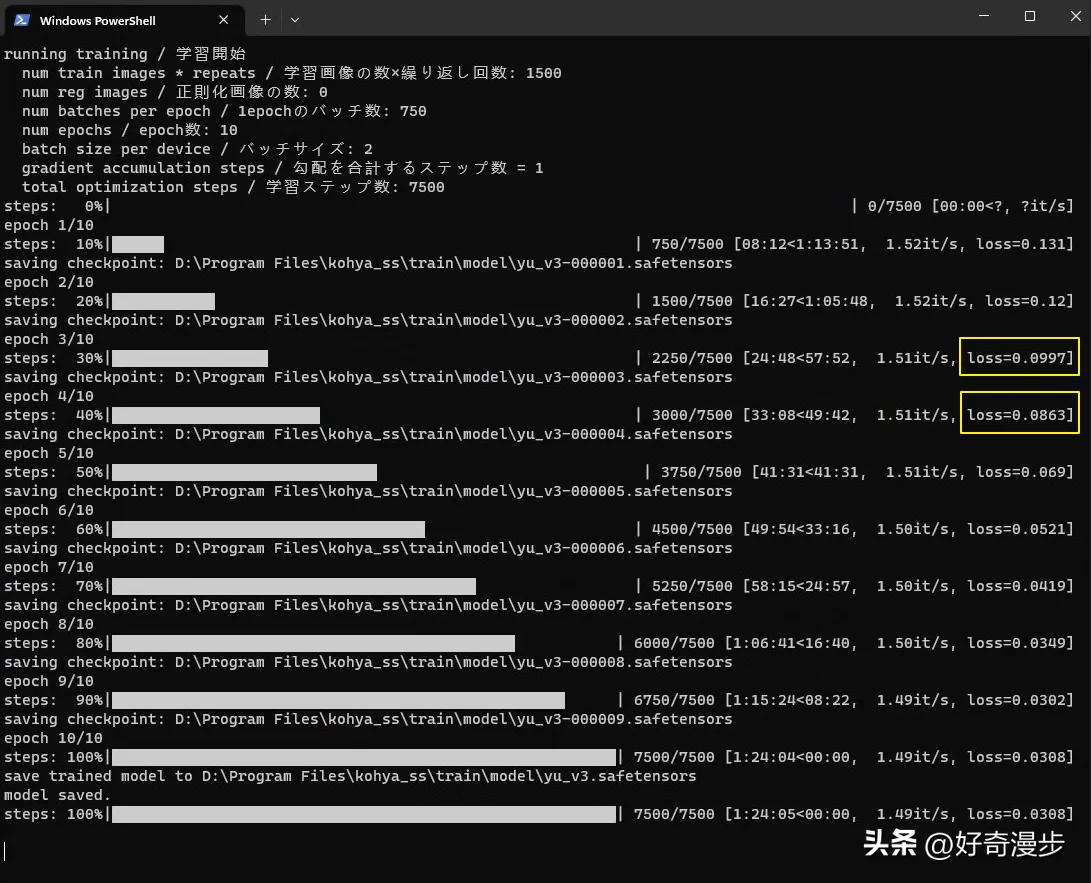
一般LoRA训练出来的最后一个模型没有编号,需要手动重命名一下。
然后把这些模型放入Stable Diffusion的LoRA模型所在位置就可以进行模型的测试和使用了。具体教程可以移步《Stable Diffusion:使用XYZ脚本生成对比图进行LoRA模型测试教程》。
更多Stable Diffusion Ai绘画教程请看本人主页 头条@好奇漫步,持续更新更多Ai相关学习教程,保持关注哦~





