
上期图文教程,我们分享了stable diffusion webui项目的安装操作,由于stable diffusion webui项目是英文项目,且里面涉及到很多设置与参数,这样针对stable diffusion webui项目的汉化操作就显得尤其重要了,本期,我们介绍一下stable diffusion webui的汉化操作与基础参数的含义。

stable diffusion webui UI界面介绍与参数解析
当我们安装完成stable diffusion webui项目后,我们可以使用如下代码进行项目的启动
!python launch.py --share --xformers --enable-insecure-extension-access
当然若喜欢暗黑模式,可以添加如下参数
!python launch.py --share --xformers --enable-insecure-extension-access --theme dark 项目启动后,我们点击public URL进行项目的启动,由于此项目运行在Google colab上面,因此需要点击public URL进行项目的启动,当然,若运行在自己本地电脑上面,直接点击第一个local URL即可。
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://61087ab0-8f51e.gradio.live项目打开后,会默认使用stable diffusion model里面的模型,若需要使用自己的模型,需要把模型文件放置到models 文件夹下面的Stable-diffusion文件夹下。
stable-diffusion-webui-master\models\Stable-diffusion第一部分:界面最上端stable diffusion checkpoint 是我们选择的模型文件,我们下载的chilloutmixni模型,放置到models 文件夹下面的Stable-diffusion文件夹下,这里就可以选择使用。
第二部分,便是Stable-diffusion webui项目的主要功能与设置操作
- txt2img:顾名思义是通过文本的描述来生成图片
- img2img:有一张图片生成相似的图片
- Extras:额外的设置
- PNG info:图片信息,若图片是由AI生成的图片,当上传一张图片后,这里会提示图片的相关prompt关键字与模型参数设置
- checkpoint merger,模型合并,可以合并多个模型,有多个模型的权重来生成图片
- Train:模型训练,可以提供自己的图片进行模型的训练,这样别人就可以使用自己训练的模型进行图片的生成
- Settings: UI界面设置
- Extensions:插件扩展,这里可以安装一些开源的插件,其中我们的汉化插件就在这里面
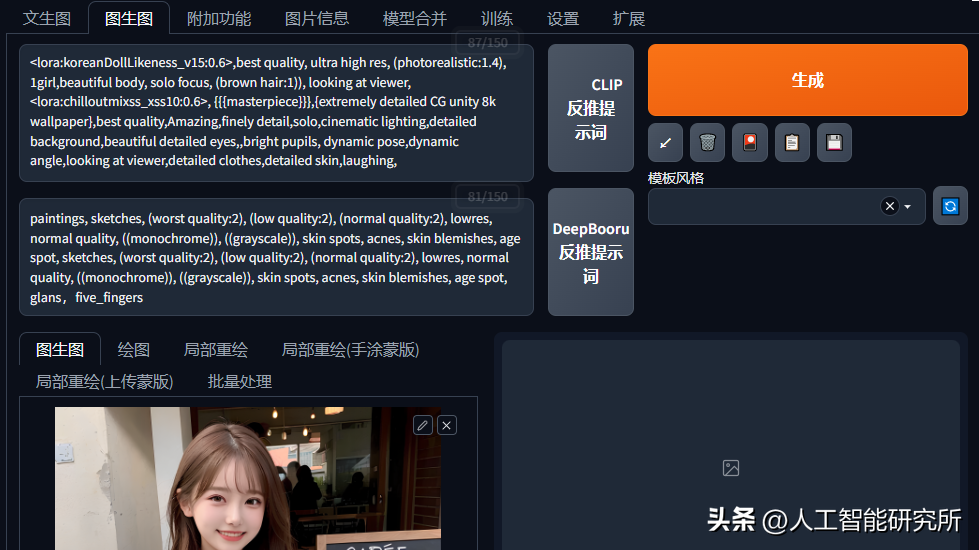
第三部分,便是正反词输入框,我们需要在此框中输入图片的描述信息,正向文本是我们希望生成的图片需要的文本,反向文本是我们不希望生成的图片文本。
然后界面左下方,第四部分,便是模型输入的相关参数:
- 采样方法(sample method):里面设置了很多采样算法,具体每个算法的效果,可以自行尝试
- 采样迭代步数(sampling steps):模型跌倒一次的步数
- restore faces,面部修复功能,可以提供面部细节
- Tiling,平铺,分块
- Hirres,fix:高清修复,可以把低分辨率的照片调整到高分辨率
- 宽度,高度,图片的尺寸
- CFG scale:提示词相关性
- seed随机种子,seed一样的情况下,可以生成比较相似的图片
- batch count生成批次,一次生成多少批的图片,batch size没批数量,一次一批的生成图片数量
- 重绘幅度(denoising strength),参数越大,重绘幅度越大,图片与原始图片越不相似,越小与原始图片越相似
当然stable diffusion还有很多设置参数,这里先介绍以上主要的参数,后期我们再分享相关的参数设置。在第五部分,便是一键生成图片的按键,我们设置完成以上参数的设置后,点击生成按键,便可以自动生成图片了,相关的图片会展示在第六部分区域,且图片保存在output文件夹中。
stable diffusion webui UI界面汉化
stable diffusion项目的汉化插件就在Extensions扩展里。我们选择Extensions>>availabel>>load from>> Extensions index URL, 这里的URL 系统会默认stable diffusion webui的地址,我们选择默认即可,hide Extensions with tags下面的几个功能按键,我们取消勾选。
然后我们点击load from按键,软件就可以索引出官方文件下的所有插件,这里可以安装自己需要的插件即可。我们需要安装的汉化插件就在此列表中,这里可以直接搜索CN,找到zh_CN localization插件,直接点击右边的install安装即可。
我们可以到
stable-diffusion-webui-master\extensions文件下查看,其实这里只是把官方的插件复制到extensions文件夹下的
stable-diffusion-webui-localization-zh_CN。
然后我们再次点击extensions>>installed,选择我们刚刚下载的的
stable-diffusion-webui-localization-zh_CN汉化插件,点击apply and restart UI,这里我们就成功安装了汉化插件。
然后,我们需要选择setting>>user interface>>localization,选择zh_CN
然后,点击apply settings即可,这里由于汉化设置需要重启UI界面,我们可以直接点击reload UI界面,当然若在Google colab上面运行,可以直接重新点击public URL即可。
我们重启界面后,就可以看到整个界面已经汉化了。
以上便是webui界面的汉化操作了,这里我们可以拿到一张图片,利用imginfo功能,提取一张精美图片的正向提示词与反向提示词。然后设置参数,就可以生成相关的精美图片了。
当然模型中还需要有lora模型以及其他真人图片生成模型,这些模型如何使用,我们后期再进行分享。





