

本文介绍一种创建聊天机器人的方法,所采用的技术包括具有预先训练单词嵌入和带有编码器-解码器体系结构的循环神经网络。单词嵌入是预先训练的,意味着他们不需要学习,只需将它们从文件加载到神经网络中即可。为了了解聊天机器人对某个特定请求的响应,这里实现了编码器-解码器网络。聊天机器人是使用TensorFlow和Keras API创建的。在本文中,您可以了解这些概念以及如何使用它们来创建像您一样说话的聊天机器人。
由于本文介绍的实现方法使用了词嵌入,因此以下对该AI技术进行简短的介绍:词嵌入是用实数向量描述或代表一个特定的词。通常,向量的大小为50到300个元素。本文使用每个单词都由一个300维向量表示的词向量。该向量可用作神经网络的输入。因此这里不将字母书写的单词直接输入到神经网络,而是将其表示为词嵌入输入到神经网络。
通过处理大量数据可以训练词嵌入(例如,某种语言的所有维基百科文章均可用于训练词向量)。词向量是根据单词的上下文(即它周围的单词)来进行训练的。因此,具有相似上下文的词具有相似的词嵌入。由于训练此类词嵌入需要大量的精力和大量数据,因此使用了预先训练的嵌入词。当需要一种特定语言的词嵌入时,应确定所需语言的预先训练词嵌入是否可用。
对于本文中描述的示例,使用德语和德语单词嵌入的训练数据。这些这些数据可以在deepset(
https://deepset.ai/german-word-embeddings)上找到。这要要感谢deepset创建了单词嵌入并让我能使用它们。它们是由德语维基百科的GloVe-Algorithm生成的。GloVe-算法的详细说明以及有关它的更多信息可以在参考文献[1]中找到。您可以在本文中学习如何使用这种预训练的单词嵌入。该过程称为迁移学习,因为我们使用已经训练的向量,并且在训练过程中不进行更改。有关单词嵌入的更多信息,请参见参考文献[2]。
本文中的另一项重要的AI技术是循环神经网络。循环神经网络通常用于处理数据序列。例如一系列天气数据(30天之内每天的温度)或股票数据(一年内的股票每日价格)。循环神经网络可以输出单个值或另一个序列。对于天气数据,这可能是未来30天的预测温度,对于股票数据,则可能是第二天的预期价格。主要有两种用于构建循环神经网络的单元类型:LSTM(长期短期记忆)和GRU(门控循环单元)。两者的共同点是它们计算内部状态,该状态从一个LSTM或GRU单元传递到下一个。在本文显示的示例中,将使用LSTM。但是,所描述的方法也可与GRU一起使用。LSTM首先由Sepp Hochreiter和Jürgen Schmidthuber创建。您可以在参考文献[3]找到有关它们的更多信息。GRU可以看作是LSTM的简单版本。您可以在参考文献[4]中获得它们的更多信息。
在以下所示的情况下,序列是对聊天机器人的请求。该请求被分成单个单词。因此,序列由几个单词组成。循环神经网络的输出序列是聊天机器人的响应。由于请求和响应的字数不相同,因此使用了一种特殊的循环网络结构。这种架构称为编码器-解码器网络。尽管这种方法最初是为语言翻译而设计的,但它也适用于本文描述的情况。
参考文献[5]中首次介绍了编解码器网络,将英语句子翻译成法语。类似的方法也可以在参考文献[4]中找到。总而言之在此体系结构中有两个循环网络。第一个循环网络称为编码器。它将输入序列编码为内部状态,将其表示为具有固定长度的向量。该状态用作第二循环网络(解码器)的初始状态。解码器的输出被馈送到具有softmax激活功能的简单神经网络。该神经网络的输出是由softmax激活函数在输出序列中每个单词在整个词典上创建的概率分布。本文稍后将对此进行详细说明。
由于我们希望聊天机器人像您一样说话,所以需要一些包含与你对话的训练数据。messenger应用程序的聊天协议是实现这个目的的一个很好的办法。通常,您可以将聊天协议导出为CSV文件。这些CSV文件需要进行处理,以便包括您收到请求和您的响应。这些请求是编码器-解码器网络的输入,响应是预期的输出。因此,需要两个数组-一个带有请求(xtestraw),另一个带有相应的响应(ytestraw)。这些数组需要进行预处理,以便删除或替换所有标点,大写字母和特殊字符。
在以下代码片段中,您可以看到我们如何预处理CSV文件以获取训练数据:
x_train_raw = []
y_train_raw = []
with open("drive/MyDrive/messages.csv") as chat_file:
first_line = True
is_request = True
last_request = ""
csv_chat_file = csv.reader(chat_file)
for row in csv_chat_file:
if first_line:
first_line = False
continue
else:
if row[CSV_IS_OUTGOING_ROW_INDEX] == "0":
last_request = row[10]
is_request = True
if row[CSV_IS_OUTGOING_ROW_INDEX] == "1" and is_request:
x_train_raw.append(re.sub(r"[^a-zäöüß ]+", "", last_request.lower()))
y_train_raw.append(re.sub(r"[^a-zäöüß ]+", "", row[10].lower()))
is_request = False
为了实现词嵌入,Keras API提供了一个嵌入层。预训练的词嵌入被加载到该嵌入层中。这种方法称为转移学习,因为我们使用已经训练过的词嵌入。词嵌入将保存在文本文件中。因此,词嵌入需要从该文件中加载然后进行处理,以使其适合Keras的数据结构并加载到嵌入层中。随着词嵌入的加载,还需要定义词汇表。为了定义词汇表,将创建一个Python词典,其中包含每个单词的索引作为值,而单词本身作为键。该词典稍后将用于将我们的训练数据转换为包含每个单词的索引而不是书面单词的索引的数组。嵌入层使用此索引来查找相应的词嵌入。以下的特殊词也必须放在词汇表中:
• <PAD>
• <START>
• <UNKNOWN>
这么做的目的将在本文中进一步说明。
以下代码段显示了如何从文件中加载词嵌入以及如何创建词汇表词典:
word_embeddings = {}
word_index = {}
#Add special words to vocabulary
word_index[PAD_TOKEN] = PAD_INDEX
word_index[START_TOKEN] = START_INDEX
word_index[UNKNOWN_TOKEN] = UNKNOWN_INDEX
word_embeddings[PAD_TOKEN] = [0.0] * 300
word_embeddings[START_TOKEN] = [-1.0] * 300
word_embeddings[UNKNOWN_TOKEN] = [1.0] * 300
index = VOCAB_START_INDEX
with open("drive/MyDrive/vectors.txt") as vector_file:
for line in vector_file:
word, embedding = line.split(maxsplit=1)
embedding = np.fromstring(embedding, sep=" ")
word_embeddings[word] = embedding
word_index[word] = index
index += 1
if index == VOCAB_SIZE:
brea
由于不希望加载整个文件,因此当词汇表中的单词数达到定义的数量时,加载将停止。由于单词是按出现频率排序的,因此只能加载一定数量的单词。例如前20,000个字。因此,对于本文所述的情况,德语维基百科中最常见的20,000个单词被定义为我们的词汇。
从文件中加载单词嵌入后,需要将它们嵌入Keras的嵌入层。您可以在以下代码片段中看到此部分:
embedding_matrix = np.zeros((VOCAB_SIZE, embedding_dim))
for word, index in word_index.items():
word_embedding = word_embeddings[word]
embedding_matrix[index] = word_embedding
embedding_layer = Embedding(VOCAB_SIZE,
embedding_dim,
embeddings_initializer=Constant(embedding_matrix),
trainable=False,
mask_zero=True,
name="embedding")
将trainable设置为False很重要。否则,词嵌入将在训练期间更改,这是我们不希望的,因为它们已经被训练过了。另一个重要参数是mask_zero = True。此参数屏蔽索引为零的单词,因此在训练中使用。索引为零的单词是特殊单词“<PAD>”,用于填充。下一部分将说明如何完成此操作。
一旦定义了词汇表,就可以处理训练数据了。为此,两个数组(xtestraw和ytestraw)中的每个单词都被其词汇表中的相应索引替换。由于编码器和解码器输入都需要固定长度,因此单词数大于输入大小的句子将被截断,而单词数较少的句子将被填充。为此,使用索引为零的特殊词“<PAD>”。在训练期间,预期输出也必须输入到解码器中,因此必须对其进行修改。为此,采用数组ytest,将其中的每个句子顺移一位,然后将“<START>”的索引插入到每个句子的第一个元素中。如果我们在词汇表中找不到单词,我们使用索引“<UNKNOWN>”。由于解码器网络的响应不是索引数组,而是包含词汇表中每个单词下一个单词的概率的向量,因此需要进一步转换训练数据。为此,可以使用Keras API函数tocategorical()。此函数从带有索引的数组中生成独热编码的向量。
def sentences_to_index(sentences, sentenc_length):
sentences_as_index = np.zeros((len(sentences), sentenc_length), dtype=int)
tmp_sentences_index = 0
tmp_word_index = 0
unknown_count = 0
for sentence in sentences:
words = sentence.split(" ")
for word in words:
current_word_index = word_index.get(word)
if tmp_word_index == sentenc_length - 1:
break
if current_word_index != None:
sentences_as_index[tmp_sentences_index, tmp_word_index] = current_word_index
else:
sentences_as_index[tmp_sentences_index, tmp_word_index] = UNKNOWN_INDEX #Word is not in vocabulary, use the index of the unkown toke
unknown_count += 1
tmp_word_index += 1
tmp_sentences_index += 1
tmp_word_index = 0
print("Unknown count: " + str(unknown_count))
return sentences_as_index
x_train_encoder = sentences_to_index(x_train_raw, MAX_INPUT_SENTENC_LENGTH)
y_train = sentences_to_index(y_train_raw, MAX_OUTPUT_SENTENC_LENGTH)
x_train_decoder = np.roll(y_train, 1)
x_train_decoder[:,0] = START_INDEX
y_train = to_categorical(y_train, num_classes=VOCAB_SIZE)
创建嵌入层,并将词嵌入加载到其中之后,模型就确定了。在这种方法中,需要三个模型。一种模型是训练模型,该模型将用于训练聊天机器人。训练完成后,将使用其他两个模型来获取聊天机器人的响应。它们被称为推理模型。所有模型共享相同的层。因此,在训练过程中训练层的权重被推理模型使用。先了解所需层是如何创建的会对您有所帮助:
#Define the layers of the encoder
encoder_input = Input(shape=(MAX_INPUT_SENTENC_LENGTH), name="encoder_input")
encoder_lstm = LSTM(LSTM_UNITS_NUMBER, return_state=True, name="encoder_lstm")
#Connect the layers of the encoder
encoder_input_embedded = embedding_layer(encoder_input)
_, state_h, state_c = encoder_lstm(encoder_input_embedded)
encoder_state = [state_h, state_c]
#Define the layers of the decoder
decoder_input = Input(shape=(MAX_OUTPUT_SENTENC_LENGTH), name="decoder_input")
decoder_state_input_h = Input(shape=(LSTM_UNITS_NUMBER,),
name="decoder_state_h_input")
decoder_state_input_c = Input(shape=(LSTM_UNITS_NUMBER,),
name="decoder_state_c_input")
decoder_state_input = [decoder_state_input_h, decoder_state_input_c]
decoder_lstm = LSTM(LSTM_UNITS_NUMBER,
return_sequences=True,
return_state=True,
name="decoder_lstm")
decoder_dense = Dense(VOCAB_SIZE, activation='softmax', name="decoder_dense")
#Connect the layers of the decoder
decoder_input_embedded = embedding_layer(decoder_input)
decoder_output, _, _ = decoder_lstm(decoder_input_embedded,
initial_state=encoder_state)
decoder_output = decoder_dense(decoder_output)
为了更好地理解不同的层含义,请参考下图了解起体系结构:
图1:RNN编码器-解码器网络的体系结构。图片由作者创建。
如图1所示,嵌入层是编码器模型和解码器网络的第一层。相同的嵌入层可用于编码器和解码器网络,因为两者都使用相同的词汇表。嵌入层的输出被馈送到编码器网络,该编码器网络由具有1024个单位的LSTM层组成。将return_state设置为True是很重要的,因为此状态是解码器网络的输入所必需的。因此,编码器网络的状态作为初始状态被传递到解码器网络。此外,解码器网络接收预期的输出序列作为输入。解码器网络的最后一层是具有softmax激活功能的密集层。此密集层提供了词汇表中每个单词接下来会出现哪个单词的概率。因此,密集层输出的大小和输出语句的最大长度相同,相应地句子中的每个元素分别和词汇表的大小相同。
创建并连接所有层之后,我们可以定义训练模型,如以下代码片段所示:
#Define the training model
training_model = Model([encoder_input, decoder_input], decoder_output)
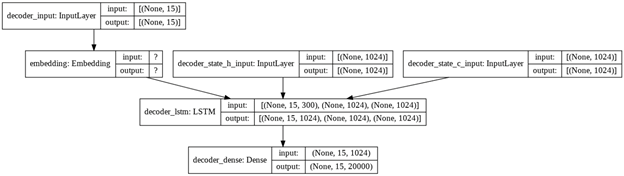
图2:训练模型的架构。图片由作者创建。
在图2中,显示了训练模型的结构图。该图是在Keras函数plot_model的帮助下创建的。
由于有必要在训练过程中将目标语句作为输入提供给解码器,因此变量coder_input是训练模型输入的一部分。
最后,创建两个推理模型(编码器模型和解码器模型),如以下代码片段所示:
#Define the encoder model
encoder_model = Model(encoder_input, encoder_state)
#Define the decoder model
decoder_output, state_h, state_c = decoder_lstm(decoder_input_embedded,
initial_state=decoder_state_input)
decoder_state = [state_h, state_c]
decoder_output = decoder_dense(decoder_output)
decoder_model = Model([decoder_input] + decoder_state_input,
[decoder_output] + decoder_state)
编码器模型和解码器模型的最终结构分别如图3和4所示。
图3:编码器模型的架构。图片由作者创建。
图4:解码器模型的架构。图片由作者创建。
定义好训练模型并且准备好我们的训练数据后,即可开始训练。以下代码片段显示了训练:
training_model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
training_model.fit(x=[x_train_encoder, x_train_decoder], y=y_train, epochs=40)
training_model.fit(x=[x_train_encoder, x_train_decoder], y=y_train, epochs=40
经过40个训练周期后,模型的输出与训练数据匹配的准确性约为95%,这已经相当不错了。
现在训练已经完成,推理模型最终可以用于与聊天机器人对话。为此,首先将请求传递到编码器模型以计算内部状态。由于没有预期的输出,如同在训练期间那样,用作编码器输入的目标序列仅由特殊字“<START>”组成。该目标序列与计算出的编码器状态一起被传递到解码器模型中,以便计算响应的第一个单词。当密集层为词汇表中的每个单词计算概率时,将选择概率最高的单词。在此之后,根据解码器输出的状态更新初始状态,并根据该输出提供的第一个单词更新目标序列。重复此操作,直到达到每个句子的最大单词数或所计算的单词为“<PAD>”。结果中将包含一个列表,其中包含每个单词的计算索引。最后,必须将索引转换回单词以获取聊天机器人的响应。
以下代码片段显示了如何使用推理模型:
def talk_with_chat_bot(request):
x_test_raw = []
x_test_raw.append(request)
x_test = sentences_to_index(x_test_raw, MAX_INPUT_SENTENC_LENGTH)
state = encoder_model.predict(x_test)
target_seq = np.zeros((1, MAX_OUTPUT_SENTENC_LENGTH))
target_seq[0, 0] = START_INDEX
output_index = []
chat_bot_response = ""
for i in range(MAX_OUTPUT_SENTENC_LENGTH-1):
output_tokens, state_h, state_c = decoder_model.predict([target_seq] + state)
predicted_word_index = np.argmax(output_tokens[0, i, :])
output_index.append(predicted_word_index)
if predicted_word_index == PAD_INDEX:
break
target_seq[0,i+1] = predicted_word_index
state = [state_h, state_c]
for output_token in output_index:
for key, value in word_index.items():
if value == output_token \
and value != PAD_INDEX \
and value != UNKNOWN_INDEX:
chat_bot_response += " " + key
print("Request: " + request)
print("Response:" + chat_bot_response)
talk_with_chat_bot("wo sollen wir uns treffen")
talk_with_chat_bot("guten tag")
talk_with_chat_bot("wie viel uhr treffen wir uns")
聊天机器人以合理的句子和良好的语法回答了我们的请求,如聊天机器人的以下输出所示。对于不熟悉德语的人,在括号中提供翻译:
Request: wo sollen wir uns treffen (where should we meet)
要求:我们在哪里见面
Response: am haupteingang (at the main entrance)
响应:正门
Request: guten tag
请求:今天好
Response: hey du wie läuft es bei dir
回应:最近你好吗
Request: wie viel uhr treffen wir uns
请求:我们什么时候见面
回应:哦
经过一些的努力,上述方法可生成良好的结果。由于采用已训练的词嵌入,因此培训时间不会很长,并且您不需要那么多的培训数据。
这是一个非常基本的方法,进行一些改进甚至可以获得更好的结果。例如,循环网络不仅是一层,还可以具有两层或四层。它们也可以实现为双向循环网络。在这种情况下,循环神经网络不仅会查看当前单词后面的单词,还会查看它之前的单词。为了获得对同一请求的各种响应,可以改进用于选择下一个单词的算法(在上述情况下,选择具有最高概率的单词,这称为贪婪采样)。可以将某些随机性应用于下一个单词的选择,即通过从概率最高的单词中随机选择一个单词(这称为随机采样)。
总结
您从本文中学到的内容:
• 编解码器网络和词嵌入的基础;
• 迁移学习的概念。具体而言,如何将预训练过的词嵌入如何加载到Keras的嵌入层中;
• 如何获取培训数据并准备好使其成为像您这样说话的聊天机器人;
• 如何为编码器-解码器网络建立和训练模型;
• 推理模型如何用于从聊天机器人生成响应。
参考
下面参考文献为本文内容的提供了更多信息:
[1] Jeffrey Pennington and Richard Socher and Christopher D. Manning, GloVe: Global Vectors for Word Representation (2014), Empirical Methods in Natural Language Processing (EMNLP)
[2] Tomas Mikolov, Kai Chen, Greg Corrado and Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space (2013), arXiv
[3] Hochreiter, Sepp and Schmidhuber, Jürgen, Long Short-term Memory (1997), Neural computation
[4] Kyunghyun Cho and Bart van Merrienboer and Caglar Gulcehre and Dzmitry Bahdanau and Fethi Bougares and Holger Schwenk and Yoshua Bengio, Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation (2014), EMNLP 2014
[5] Ilya Sutskever and Oriol Vinyals and Quoc V. Le, Sequence to Sequence Learning with Neural Networks (2014), arXiv
原文链接:
https://towardsdatascience.com/creating-a-smart-chat-bot-that-talks-like-you-79bb700b288f
- End -





