

翻译:张睿毅
校对:吴金笛
本文4300字,建议阅读10+分钟。
本文作者通过实战介绍了Deep Q-Learning的概念。
导言
我一直对游戏着迷。在紧凑的时间线下执行一个动作似乎有无限的选择——这是一个令人兴奋的体验。没有什么比这更好的了。
所以当我读到DeepMind提出的不可思议的算法(如AlphaGo和AlphaStar)时,我被吸引了。我想学习如何在我自己的机器上制造这些系统。这让我进入了深度强化学习(Deep RL)的世界。
即使你不喜欢玩游戏,深度强化学习也很重要。只用看当前使用深度强化学习进行研究的各种功能就知道了:
那工业级应用程序呢?这里有两个最常见的深度强化学习用例:
谷歌云自动机器学习(Google’s Cloud AutoML)
脸书Horizon平台(Facebook's Horizon Platform)
深度强化学习的范围是巨大的。现在是一个进入这个领域并并以此作为职业的好时机。
在这篇文章中,我的目标是帮助您迈出第一步,进入深度强化学习的世界。我们将使用强化学习中最流行的算法之一,Deep Q-Learning,来了解强化学习是怎样工作的。锦上添花的是什么呢?我们将使用python在一个很棒的案例研究中实现我们的所有学习。
目录
一、Q-Learning之路
二、为什么要做“深度”Q-Learning?
三、Deep Q-Learning的简介
四、与深度学习相比,深度强化学习面临的挑战
4.1 目标网络
4.2 经验回放
五、使用Keras & Gym 在Python中实现Deep Q-Learning
一、Q-Learning之路
在正式深度强化学习之前,您应该了解一些概念。别担心,我已经为你安排好了。
我以前写过很多关于强化学习的文章,介绍了多臂抽奖问题、动态编程、蒙特卡罗学习和时间差分等概念。我建议按以下顺序浏览这些指南:
强化学习的基础学习:使用动态编程的基于模型的规划
https://www.analyticsvidhya.com/blog/2018/09/reinforcement-learning-model-based-planning-dynamic-programming/
强化学习指南:从零开始用Python解决多臂抽奖问题
https://www.analyticsvidhya.com/blog/2018/09/reinforcement-multi-armed-bandit-scratch-python/?utm_source=blog&utm_medium=introduction-deep-q-learning-python
强化学习:通过OpenAI GymToolkit介绍蒙特卡洛学习
https://www.analyticsvidhya.com/blog/2018/11/reinforcement-learning-introduction-monte-carlo-learning-openai-gym/?utm_source=blog&utm_medium=introduction-deep-q-learning-python
蒙特卡罗树搜索简介:DeepMind的AlphaGo背后的游戏改变算法
https://www.analyticsvidhya.com/blog/2019/01/monte-carlo-tree-search-introduction-algorithm-deepmind-alphago/
强化学习的基础:时间差(TD)学习介绍
https://www.analyticsvidhya.com/blog/2019/03/reinforcement-learning-temporal-difference-learning/?utm_source=blog&utm_medium=introduction-deep-q-learning-python
这些文章足以从一开始就获得基本强化学习的详细概述。
但是,请注意,以上链接的文章绝不是读者理解Deep Q-Learning的先决条件。在探究什么是Deep Q-Learning及其实现细节之前,我们将快速回顾一下基本的强化学习概念。
强化学习代理环境
强化学习任务是训练与环境交互的代理。代理通过执行操作到达不同的场景,称为状态。行动会带来正面和负面的回报。
代理只有一个目的,那就是最大限度地提高一段经历的总回报。这个经历是环境中第一个状态和最后一个或最终状态之间发生的任何事情。我们加强了代理的学习,以经验来执行最佳的行动。这是战略或原则。
让我们举一个非常流行的PubG游戏的例子:
士兵是这里与环境互动的代理;
状态就是我们在屏幕上看到的内容;
一段经历是一个完整的游戏;
动作包括向前、向后、向左、向右、跳跃、躲避、射击等;
奖励是根据这些行动的结果确定的。如果士兵能够杀死敌人,那就获得一个正面的回报,而被敌人射杀是一个负面的回报。
现在,为了杀死敌人或得到正面的回报,需要一系列的行动。这就是延迟或延迟奖励的概念开始发挥作用的地方。强化学习的关键是学习执行这些序列并最大化回报。
马尔科夫决策过程(MDP)
需要注意的一点是,环境中的每个状态都是其先前状态的结果,而先前状态又是其先前状态的结果。然而,存储所有这些信息,即使是在短时间的经历中,也变得不可行。
为了解决这一问题,我们假设每个状态都遵循马尔可夫属性,即每个状态仅依赖于先前的状态以及从该状态到当前状态的转换。看看下面的迷宫,以更好地了解这项工作背后的思想:
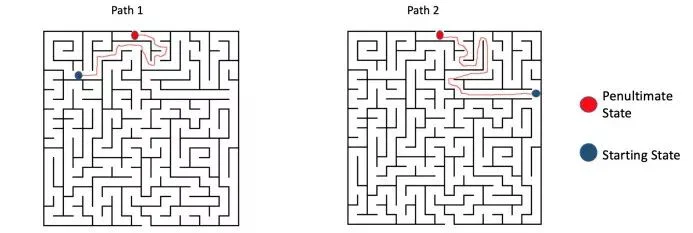
现在,有两个场景具有两个不同的起点,代理通过不同的路径到达相同的倒数第二状态。现在,不管代理通过什么路径到达红色状态。走出迷宫并到达最后一个状态的下一步是向右走。显然,我们只需要红色/倒数第二状态的信息就可以找到下一个最佳的行为,这正是马尔可夫属性所暗示的。
Q 学习
假设我们知道每一步行动的预期回报。这基本上就像是给代理的一张备忘单!我们的代理会确切知道该采取什么行动。
它将执行最终产生最大总奖励的动作序列。总回报也称为Q值,我们将把我们的策略公式化为:
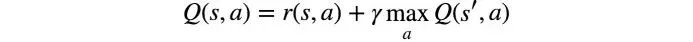
上述方程表明,在状态s和执行动作a产生的Q值是立即奖励r(s, a)加上下一状态s’ 可能的最高Q值。这里的gamma是折现系数,它控制着未来奖励的贡献。
q(s’, a)又取决于q(s”, a),该q(s”, a)将具有伽马平方系数。因此,Q值取决于未来状态的Q值,如下所示:
调整gamma的值将减少或增加未来奖励的贡献。
由于这是一个递归方程,我们可以从对所有Q值进行任意假设开始。根据经验,它将收敛到最优策略。在实际情况下,这是作为更新实现的:
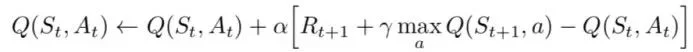
其中alpha是学习速率或步长。这就决定了新获取的信息在多大程度上会覆盖旧信息。
二、为什么选择“深度”Q-Learning
Q-Learning是一个简单但功能强大的算法,可以为我们的代理提供一个备忘单,有助于代理准确地确定要执行的操作。
但如果这张备忘单太长怎么办?设想一个有10000个状态的环境,每个状态有1000个行动。这将创建一个包含1000万个单元格的表。事情很快就会失控!
很明显,我们不能从已经探索过的状态中推断出新状态的Q值。这有两个问题:
首先,保存和更新该表所需的内存量将随着状态数的增加而增加。
第二,探索每个状态创建所需Q表所需的时间量是不现实的。
这里有一个想法——如果我们用机器学习模型(比如神经网络)来估计这些Q值会怎么样?好吧,这就是DeepMind算法背后的想法,它使得谷歌以5亿美元收购DeepMind!
三、Deep Q-Learning的简介
在深度Q学习中,我们使用神经网络来近似Q值函数。状态作为输入,所有可能动作的Q值作为输出生成。Q-Learning和深度Q-Learning之间的比较如下:
那么,使用深度Q学习网络(DQNs)强化学习的步骤是什么?
所有过去的经验都由用户存储在内存中。
下一步动作由Q网络的最大输出决定。
这里的损失函数是预测的Q值和目标Q值–Q*的均方误差。
这基本上是一个回归问题。然而,我们不知道这里的目标或实际价值,因为我们正在处理一个强化学习问题。回到由贝尔曼方程导出的Q值更新方程。我们有:
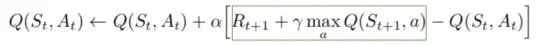
绿色部分表示目标。我们可以说,它是在预测自己的价值,但由于R是无偏的真实回报,网络将使用反向传播更新其梯度,最终收敛。
四、与深度学习相比,深度强化学习面临的挑战
到目前为止,这一切看起来都很棒。我们了解了神经网络如何帮助代理学习最佳行动。然而,当我们将深度强化学习与深度学习(DL)进行比较时,存在一个挑战:
非固定或不稳定目标
让我们回到深度Q学习的伪代码:
正如您在上面的代码中看到的,目标在每次迭代中都在不断地变化。在深度学习中,目标变量不变,因此训练是稳定的,这对强化学习来说则不然。
综上所述,我们经常依赖于政策或价值函数来加强学习,以获取行动样本。然而,随着我们不断学习要探索什么,这种情况经常发生变化。当我们玩游戏时,我们会更多地了解状态和行为的基本真值,因此输出也在变化。
因此,我们尝试学习映射不断变化的输入和输出。但是解决办法是什么呢?
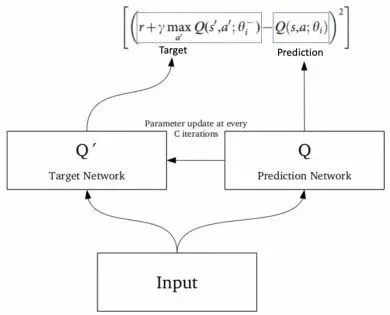
4.1 目标网络
由于同一个网络正在计算预测值和目标值,这两者之间可能存在很大的差异。因此,我们可以使用两个神经网络来代替使用1个神经网络来学习。
我们可以使用单独的网络来估计目标。该目标网络与函数逼近器具有相同的结构,但参数是固定的。对于每个C迭代(超参数),预测网络中的参数都会复制到目标网络中。这将导致更稳定的训练,因为它保持目标功能不变(在一段时间之内):
4.2 经验回放
要执行经验回放,我们存储代理的经验 – et=(st,at,rt,st+1)
上面的陈述是什么意思?在模拟或实际经验中,系统不会在状态/动作对上运行Q-Learning,而是将为[状态、动作、奖励、下一个状态]发现的数据存储在一个大表中。
让我们用一个例子来理解这一点。
假设我们试图构建一个视频游戏机器人,其中游戏的每一帧表示不同的状态。在训练过程中,我们可以从最后100000帧中随机抽取64帧来训练我们的网络。这将使我们得到一个子集,其中样本之间的相关性较低,也将提供更好的采样效率。
结合到一起
到目前为止我们学到的概念是什么?它们结合在一起,形成了用于在Atari游戏中实现人类级性能的深度Q学习算法(仅使用游戏的视频帧)。
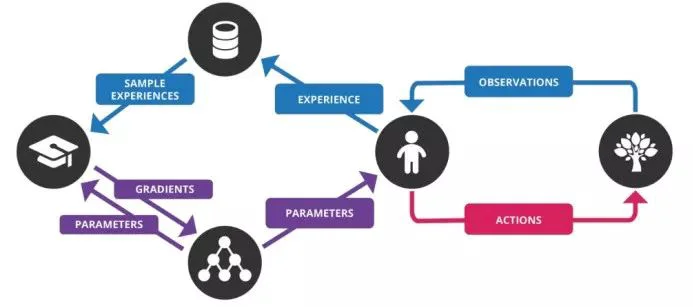
我在下面列出了Deep Q-Network(DQN)中涉及的步骤:
对游戏画面(状态S)进行预处理并反馈给DQN,DQN将返回状态下所有可能动作的Q值
使用epsilon贪婪策略选择操作。用概率epsilon,我们选择一个随机动作a并且概率为1-epsilon,我们选择一个最大Q值的动作,例如a=argmax(Q(s, a, w))
在s状态下执行此操作并移动到新的s状态以获得奖励。此状态s'是下一个游戏屏幕的预处理图像。我们将此转换存储在重播缓冲区中,如<s, a, r, s'>
接下来,从重放缓冲区中随机抽取若干批转换并计算损失。
已知:
,即目标Q与预测Q的平方差。根据我们的实际网络参数进行梯度下降,以尽量减少损失。
每次C迭代后,将我们的实际网络权重复制到目标网络权重
对m个经历重复这些步骤
五、使用Keras & OpenAI Gym 通过Python实现Deep Q-Learning
好吧,这样我们对深度Q学习的理论方面有了很好的了解。现在就开始行动怎么样?没错——让我们启动我们的python notebook吧!
我们会创造一个可以玩CartPole的代理。我们也可以使用Atari游戏,但是训练一个代理来玩需要一段时间(从几个小时到一天)。我们的方法背后的思想将保持不变,所以你可以在你的机器上的Atari游戏上尝试这个。
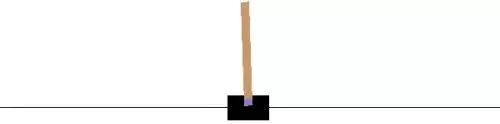
CartPole是OpenAI gym(游戏模拟器)中最简单的环境之一。正如你在上面的动画中看到的,CartPole的目标是平衡一个杆,这个杆与一个运动车顶部的接合处相连。
这里有四种由状态给出的信息(如杆的角度和推车的位置),而不是像素信息。代理可以通过执行一系列0或1操作来移动车,将车向左或向右推。
我们将在这里使用Keras-rl库,它允许我们实现深度Q学习。
第一步:安装keras-rl库
从终端运行以下代码块:
git clone https://github.com/matthiasplappert/keras-rl.gitcd keras-rlpython setup.py install
第二步: 安装Cartpole环境的依赖项
假设你已安装pip,你需要安装以下库:
pip install h5pypip install gym
第三步:开始吧!
首先,我们导入必需的模块:
import numpy as npimport gymfrom keras.models import Sequentialfrom keras.layers import Dense, Activation, Flattenfrom keras.optimizers import Adamfrom rl.agents.dqn import DQNAgentfrom rl.policy import EpsGreedyQPolicyfrom rl.memory import SequentialMemory
之后,设置相关参数:
ENV_NAME = 'CartPole-v0'# Get the environment and extract the number of actions available in the Cartpole problemenv = gym.make(ENV_NAME)np.random.seed(123)env.seed(123)nb_actions = env.action_space.n
下一步,我们构造一个非常简单的单一隐含层神经网络模型:
model = Sequential()model.add(Flatten(input_shape=(1,) + env.observation_space.shape))model.add(Dense(16))model.add(Activation('relu'))model.add(Dense(nb_actions))model.add(Activation('linear'))print(model.summary())
现在,配置和编译我们的代理。我们将把我们的策略设置为epsilon greedy,把我们的内存设置为顺序内存,因为我们希望存储我们所执行的操作的结果以及每个操作获得的奖励。
policy = EpsGreedyQPolicy()memory = SequentialMemory(limit=50000, window_length=1)dqn = DQNAgent(model=model, nb_actions=nb_actions, memory=memory, nb_steps_warmup=10,target_model_update=1e-2, policy=policy)dqn.compile(Adam(lr=1e-3), metrics=['mae'])#好吧,现在该学点东西了!我们把这里的训练具象化展示出来,但这会大大降低训练的速度。dqn.fit(env, nb_steps=5000, visualize=True, verbose=2)
测试我们的强化学习模型:
dqn.test(env, nb_episodes=5, visualize=True)这将是我们模型的输出:

不错!祝贺您建立了第一个深度Q学习模型。
最后几点
Openai Gym提供了几种将DQN融合到Atari游戏中的环境。那些处理过计算机视觉问题的人可能会直观地理解这一点,因为这些问题的输入在每个时间步骤都是游戏的直接帧,因此该模型由基于卷积神经网络的体系结构组成。
有一些更先进的深度强化学习技术,如双DQN网络,双DQN和优先经验回放,可以进一步改善学习过程。这些技巧让我们用更少的片段获得更好的分数。我将在以后的文章中介绍这些概念。
我建议您在Cartpole之外的至少一个环境中尝试DQN算法,以练习和理解如何调整模型以获得最佳结果。
原文标题:
A Hands-On Introduction to Deep Q-Learning using OpenAI Gym in Python
原文链接:https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
译者简介
张睿毅,北京邮电大学大二物联网在读。我是一个爱自由的人。在邮电大学读第一年书我就四处跑去蹭课,折腾整一年惊觉,与其在当下焦虑,不如在前辈中沉淀。于是在大二以来,坚持读书,不敢稍歇。资本主义国家的科学观不断刷新我的认知框架,同时因为出国考试很早出分,也更早地感受到自己才是那个一直被束缚着的人。太多真英雄在社会上各自闪耀着光芒。这才开始,立志终身向遇到的每一个人学习。做一个纯粹的计算机科学里面的小学生。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”拥抱组织





