
华尔街见闻·见智研究特邀到了方正证券AI互联网首席分析师【杨晓峰】详细拆解了AI大模型对游戏行业能够带来哪些降本增效的影响,并且初步预判该影响至少要二个季度才能反应在财务上。
核心观点:
1、AI现在有两个大模型能够极大程度提高游戏在美术制作流程上的效率,节省制作成本以及缩短时间。这两个大模型分别是Stable Diffusion和NeRF模型,能够分别在游戏美术制作过程中,对2D和3D场景和人物生成进行优化。
2、Stable Diffusion又称文生图模型,能够生成多视角的2D图,进一步为生成3D图奠定基础,但是条件受限于需要性能等级高的显卡,因此在普通消费者群体中很难大范围渗透。
3、NeRF模型主要是对2D-3D过程进行了降本增效,当前制作一个3D游戏角色的周期在30-45天左右,且需要的步骤较多,参与的人员众多;使用NeRF可以快速建模,从而提高效率,节省成本。之前要10个工作日的工作现在只需要半天到一天就能完成,这相当于节省了90%的时间。
4、但是NeRF模型尚未达到引爆点,主要原因是该技术有一定壁垒,不过龙头公司Luma AI,开发了NeRF相关的APP,目前已上线APP Store,极大的降低了NeRF的使用门槛,预计在未来的半年到一年内会取得突破性进展。
5、总得来看,AI模型能够对游戏研发设计过程中成本和时间进行极大的优化,据不完全统计,在游戏的研发成本中美术成本一般占50%到80%。如果一个游戏公司的研发成本占70%,那么其中的40%基本上都可以大幅降低。
6、大公司和小公司的区别就是否只能降 2D 的钱,还是也能降 3D 的钱,如果 2D 和 3D 都能降低了,那么整个降本增效的幅度其实是60%-70%都不一定打得住,所以说下降的幅度其实非常大的。
正文:
见智研究:为什么AI在游戏的应用受到关注?
杨晓峰:
核心原因是游戏公司的商业模式相对比较优秀,他们有一定的资源可以运用AI模型。另一个原因是现在有很多 AI 模型已经比较成熟,例如 AI 作画,这直接颠覆或者改变了游戏行业,所以目前来看游戏行业是最快应用 AI 的行业。当然,动画行业也是类似的,因为现在国内和国外的技术水平基本持平,尤其在 AI 作画方面。
最近我们注意到海外有一款游戏,其中有好几个角色都是通过人工智能控制的。可以想象,这款游戏就像《西部世界》一样,游戏中的许多角色都有自己的成长轨迹和个性。在这个世界里,除了玩家自己以外,每个人都是真实的。这种体验的沉浸感非常高,这种应用将会越来越普及。这种体验其实就是 NPC 的一个改进。
我们还注意到另一个案例,当我们用游戏制作美术的时候,花同样的钱,我们可以把整个美术场景做得越来越漂亮。过去,我们只能把在前面的视角做得比较漂亮,但现在花同样的钱能把整个视觉都做得非常漂亮。我们已经看到很多这样的案例。
此外,我们最近还发现了一个名为 Inword 的平台。这个产品事先已经训练好了各种非常有性格的人物角色,可以直接将这个代码集成到游戏中。这样游戏中可能会出现像马斯克这样有性格的角色。其他人已经把这些集成好了,只需要接入使用就可以了,游戏体验将会得到非常快速的改善。
见智研究:哪些AI模型可以应用于游戏领域?各自的特点是什么?
杨晓峰:
现在有两种成熟的模型,一种是大文本模型,另一种是 2D 作图模型,还有一种处于爆发期的2D转3D NeRF模型。
第一类模型是文本生成模型,例如 ChatGPT 和国内的各种大模型,它们可以接受文本输入并输出对应的文本,这种模型被广泛使用。但在游戏中,通常直接使用其中的角色。
第二类模型类似于文生图,它可以根据输入的文本生成各种各样的图片。这种模型已经非常成熟,大多数互联网公司都在使用它来生成图片。比较著名的有Stable Diffusion和 Midjourney,其中Stable Diffusion的使用较为广泛,因为它所需的费用较少;Midjourney面向消费者,使用体验较好,且对电脑的要求较低。因此,后续制作 2D 图像时可以使用它。
现在还有一个模型即将爆发,可能会在未来半年到一年内实现,它是将 2D 转化为 3D 的模型,名为神经辐射场(NeRF)。只需拍几张照片,就可以立即生成一个包括场景和人物的 3D 模型。想象一下以前制作游戏时需要的场景图,如刺客信条中的巴黎场景。现在只需花费一些资金用无人机拍摄一些视频,就能立即将 3D 模型建立起来,成本降低非常快。这是目前可能已经使用的模型。
见智研究:生成3D模型的方式有哪些?分别有何优劣?
杨晓峰:
过去生成 3D 的方法一般是通过画平面图进行建模,例如对于一个角色,可能需要从不同视角画多张图来进行建模。然后建模师会使用建模软件一个个搭建,例如将立体的头发贴到人脸上。这种方法需要花费大量的时间,可能需要 2 到 3 周才能完成一个人物的建模。优势是每个物体都是比较精巧的立体结构,但劣势在于时间成本很高,因此一般会交给外包公司去完成。
还有一种叫照相技术的方法,即通过拍摄物体的照片来建立模型,但是每张照片必须要重合50%才能建立一个模型,但这种技术对光影等细节处理比较困难,因此很少被使用。最近开始使用的 NeRF 模型已经有了一篇公开的论文,目前可供使用的软件只有两个:Instant NGP和Luma。目前这两个产品已经能够做到只需拍摄一个物体,即可立即生成3D模型。但它也有缺点,即在制作产品时未考虑兼容性。
比如在英伟达的生态系统内制作了一个非常漂亮的3D模型,但我们并不会考虑将其优化并放到Unity或虚幻引擎中运行,因为3D建模完成后必须将其放入游戏引擎中才能产生最佳效果。目前看来,这个领域仍在发展中,但是Luma已将其插件放入虚幻引擎和游戏引擎中,它的进展可能会更快。我们可以这样理解:目前这个模型并不十分开源,因此需要一些人工智能工程师才能更好地使用它。优点就是确实可以降低很大的成本,但是需要掌握一些相对高水平的技能。
见智研究:NeRF是否会替代原来的 3D 模型成为未来主流选择?
杨晓峰:
我认为大概率会实现,因为行业目前的最新进展是,就像我们刚才介绍的,2D照片可以生成3D模型。现在,行业最新的动态是可以直接进行修改,比如说我有一个自己的人物3D模型,我可以通过输入文本,将我的人物头像替换成马斯克的头像。这个技术已经相当成熟了。
最近,有一个海外的大一新生,对NeRF技术贡献了非常迅速的进展。将来,你可以通过文本修改3D模型,例如,你可以让它为你的模型加胡子或眼镜。这个功能看起来非常酷炫,也相当强大,但如果你了解其原理,你就会发现其实并不是那么难,只是以前没有人去优化。
现在大多数人使用模型进行嫁接,每个模型都有自己擅长的领域。例如,文本模型擅长处理文本输入和输出,Stable Diffusion擅长生成 2D 图像,而 NeRF 模型则擅长将 2D 图像转换为 3D 图像。
未来的发展趋势是将所有模型连接在一起,用户只需简单地表达意图,模型就能帮助实现任务。目前,NeRF 模型是最具潜力的模型之一,但其尚未达到引爆点。预计在未来的半年到一年内,NeRF 模型会大放异彩。
见智研究:Stable Diffusion模型的特点是?
杨晓峰:
我们刚才提到了 NERF 可以将 2D 照片转换成 3D 图片,而Stable Diffusion 本质上是一个文生图的工具。这个工具为什么会这么受欢迎?它目前的功能有多强大?
在去年的 11 月到 12 月之前,这个软件其实并没有什么热度,但突然间变得火爆起来。原因是有人上传了一个数据包,用户只需要输入想要的卡通或真人形象,就能迅速生成一个非常漂亮的图像,吸引了大量用户涌入。同时无数人也开始为其提供各种训练数据包,进一步丰富了其功能,现在不仅能画出二次元卡通和真人形象,还能画出 GTA5 的图像。
这个软件之所以能如此强大,因为市场上的无数用户都在为其提供训练数据包,使得模型能够生成各种精美图像。但是需要注意的是,这个软件需要较好的显卡,最好是 3090 或者更高的4090,因此对于普通消费者的用户体验可能一般。为此,有人专门用Stable Diffusion的建模开发了网页版,让用户不需要拥有好的电脑,就能在网页上使用。不过,这个服务需要付费,普通用户每月需要支付几十美元,企业用户则需要支付更高的费用。
因为开源的原因,现在Stable Diffusion 不仅能够生成静态图像,甚至能够生成视频。这是因为在今年3月份,有人修改了底层代码,使得可以规定 AI 作图的一些参数,例如如果我画了一匹马,我可以再画一张马抬腿的图像,然后将每个马的腿都抬起来,合成为一个视频。这就是为什么现在国内外很多公司突然推出了 AI 视频的原因,因为它们都是基于 Stable Diffusion这个原理,只是可能在这个渠道上进行了一些优化。
此外,Stable Diffusion 现在更强大的一点是可以无中生有地建立 3D 模型,只要你能描述这个物体的各个角度,它就能够生成多个角度的2D图片,接着再利用多视角的2D图片生成3D图片。因此未来是可以无中生有的生成 3D 的。这意味着Stable Diffusion 已经成为了 AI 作图领域最强大的工具之一,其他的工具都是在其基础上进行迭代。
见智研究:开源的模型的优势和意义在哪?拓展插件对于模型起到什么作用?
杨晓峰:
模型一旦开源,全球顶尖的人才就可以使用它并做微调,他们可以贡献各种各样的素材包,使得模型使用效果更强大。因为Stable Diffusion开源,全球所有人都可以享受到这个 AI 作图的红利,大家都可以在上面进行修改或将其放到自己的服务器上。开源意味着这个软件的每一条代码都是公开的,可以下载到本地,而别人也无法对你进行操作。
当然,行业可能需要一些相对厉害的人才,才能将这个产品推向更高层次,修改底层代码,进一步提升产品水平。因此,开源对整个模型的进步速度非常快,可以想象,在 11 月和 12 月之前,大多数人的水平都比较低,但是因为开源,无数人在 1 月和 2 月份上传了数据包,3 月份修改了底层代码,这个产品的进展就非常快了。可以这样理解,开源把所有人的水平都提高了一个非常高的状态。
见智研究:模型开源很大程度加速了应用层面的落地?
杨晓峰:
Midjourney为什么会如此受欢迎呢?并不是因为它有技术上的优势,而是因为它更能够满足C端用户的需求。比如,我们都知道Stable Diffusion技术很好,产品性能也很好,但问题在于并非每个人的电脑都有如此高的显卡,同时,数据包越多并不一定意味着更好的体验,因为很多人更想要一些更加真实的、大气的效果,对吧?因此,很多产品都是在这个基础上针对C端用户的体验进行了优化。背后的技术可能需要使用Stable Diffusion等原创技术,或者出于成本考虑使用其他技术,但对于普通的C端用户,使用Midjourney基本上就足够了。
见智研究:AI是如何对游戏进行降本增效的?
杨晓峰:
以一个游戏公司为例,该公司的研发成本中,美术成本一般占50%到80%。因为有些游戏的用户数量非常多,不能出现卡顿等问题,因此游戏的程序成本非常高,那么美术成本占据了研发成本的 50%。但是有些游戏只是卡牌游戏,只需要将卡片画好,它就能自己动了,这种游戏的美术成本占据了80%。可以想象一下这种情况下的成本。
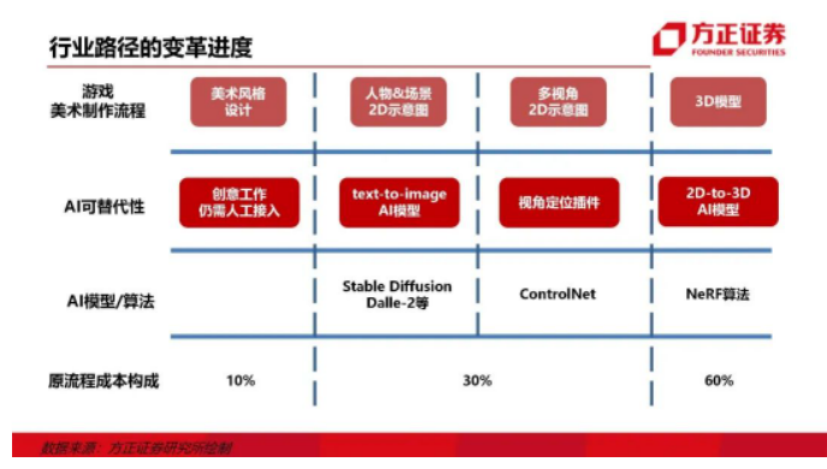
而作为游戏美术,首先,我需要设计游戏的UI界面,如果我手头有10个人,其中一个人会负责绘制游戏横屏的UI界面,比如登录界面。剩下的三个人会设计人物模型,做2D的人物设计,比如绘制多个视角下的角色,通常需要两周的时间才能完成一个角色的绘制。
这四个人以前需要两周才能完成的工作,现在只需要半天就能完成了。这意味着我们可以节省很多时间和成本。之前需要10个工作日的工作现在只需要半天到一天就能完成,这相当于节省了90%的时间。
如果我们只考虑2D方面,那就是2D的人物和平面界面。其余的六层都是外包给其他人做建模的。比如说,我拿到了一个2D的画面,我可以找一个建模师帮我把它建成一个3D的物体或人物,这个钱一般都是给外面的人。这一部分成本是可以砍掉的。
但NeRF不是开源的,很多公司没有这么优秀的AI人才去使用它,所以这方面的进展还不是很大。如果一个游戏公司的研发成本占70%,那么其中的40%基本上都可以大幅降低。
所以我觉得说,大公司和小公司的区别就是你是否只能降 2D 的钱,还是说你也能降 3D 的钱,如果你 2D 加 3D 都能降低了,那么我觉得整个降本增效的幅度其实是60%-70%都不一定打得住,所以说下降的幅度其实非常大的。
互动环节:
见智研究:游戏降本增效的成果多久能够反映在财务报表上?
杨晓峰:
这个主要看的是一个自上而下的逻辑,因为 2D 作画这个工具在今年一、二月份才开始反映,在公司内推行基本上要到4月以后,可能在二季度甚至三季度会逐步显现。
而从模型上来看,生成多个视角图的功能都是在 3 月份才开始的,二季度慢慢地就开始熟练起来,三季度可能慢慢就显现出来了成品效果。
见智研究:对拥有 IP 较多的公司会有什么影响?
杨晓峰:
IP的价值被认为很高,因为它可以持续产生产品。通过提高生产能力,像迪斯尼动画一样,供应量可以大幅增加,但需求可能无法跟上。人工智能可以将生产能力增加至5倍,但市场是否能够承受这么多还不确定,可能需要打折扣。拥有强大的IP可以增加产品的吸引力,因为随着产品数量的增加,创造新IP变得越来越困难。
见智研究:对于不同类型的游戏公司降本增效的方式会有哪些侧重?
杨晓峰:
我们首先看的就是对于头部的公司而言,它降本增效特别明显,就是2D、 3D 同时降,因为他们招的是一些顶级的 AI 工程师,所以2D、 3D 都能降。他们可能能够跟海外的 3A 大厂进行竞争了,因为 3A 大厂过去构筑的那种美术壁垒就相对于漏了非常多,那么这是头部的公司,那么对于中腰部的公司而言,就相对而言说,它可以通过使用一定的技术把自己的成本降下去。
见智研究:接下来您比较看好的是哪些的赛道?
杨晓峰:
AI作画是当前比较成熟的技术之一,其中动画和游戏是最有可能最快落地应用的领域。由于之前美术人才紧缺,这些行业在使用AI作画后将大幅提高产能。此外,随着时间的推移,使用AI作画的成本也会显著降低。因此,这两个领域是值得关注的赛道,不仅能降低成本,还能快速提高产能。





