
Pine 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
没想到,众人加班加点抢“中国版ChatGPT”热度时,首个国内类ChatGPT模型竟然已经发布了!
砸出这个重磅消息的,不是紧锣密鼓宣传的BAT大厂,也不是直接出手几亿的投资大V,而是这段时间来一直没吭气的复旦大学。
事情一出,直接引爆了一众社交媒体,不仅在微博刷出数个热搜话题,知乎更是冲上热榜第一。

各路“ChatGPT爱好者”连夜赶来围观,甚至由于官网访问人数太多,服务器一度被挤爆,又上了一次热搜。
这是怎么回事?
原来,复旦NLP团队这个类ChatGPT模型,发布即面向公众进行内测,甚至连预告都没有:
紧接着,团队又投下另一颗重磅炸弹:模型3月份就会开源代码。
最关键的是模型的名字。
复旦团队用了《流浪地球》里面拥有自我意识的AI——MOSS来命名这一模型,直接把消息热度推上顶峰。
有网友表示,MOSS率先开放至少有一大优势,那就是“获得更多数据”:
ChatGPT有一个巨大的先发优势,就是通过抢先开始公测收集大量用户数据,并且这部分数据现阶段只有人家有。
算法都是成熟且公开的算法,真正的核心其实是数据和硬件。
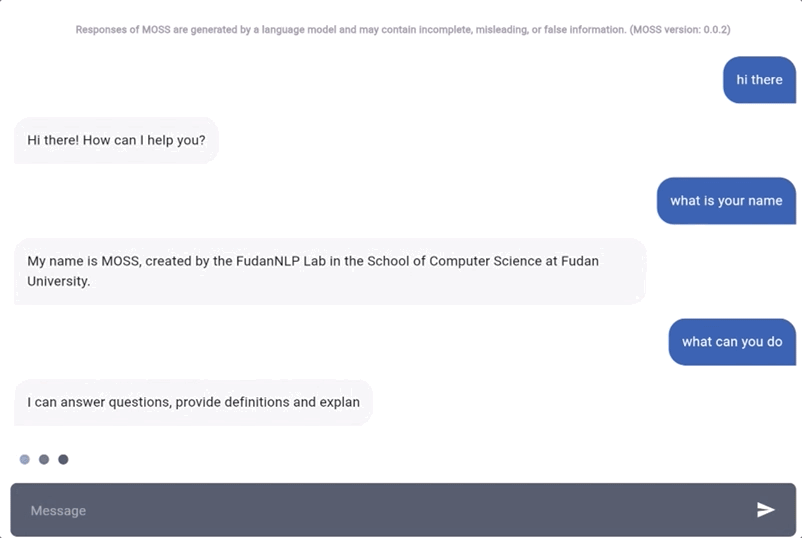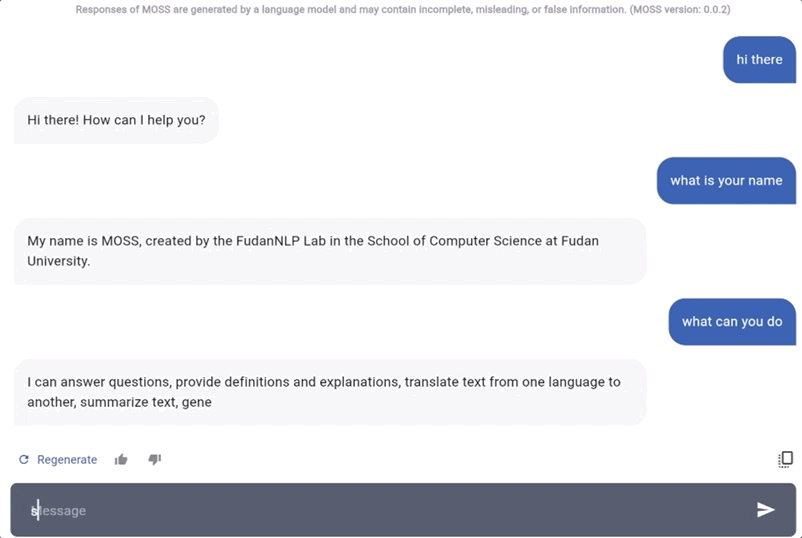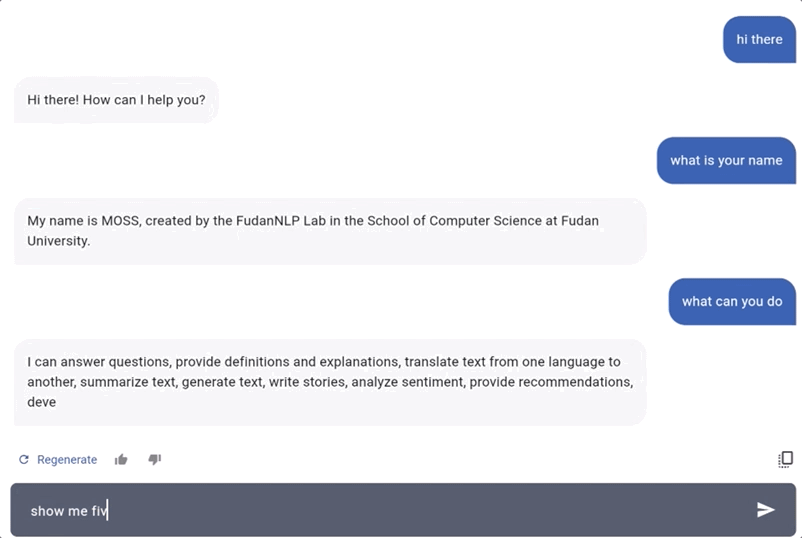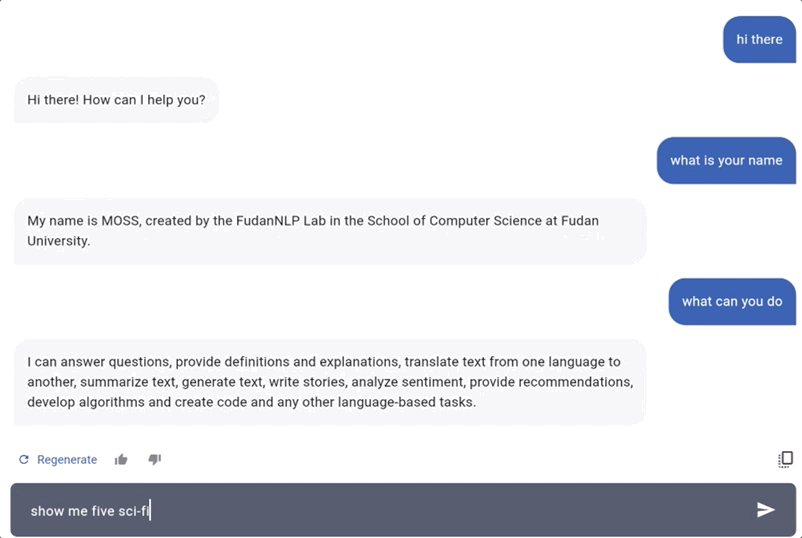
说回模型本身。据MOSS自己介绍,它同样具备ChatGPT能实现的这些功能:
问答、文本翻译、摘要总结、故事撰写、情绪分析、建议提供、代码和算法编写等。
但实际测试效果又是如何,具体训练方法和效果会不会有什么差异?
我们一步步来看。
MOSS与ChatGPT相比效果如何?
据团队介绍,MOSS与ChatGPT主要有三大差异。

最主要的就是参数量的不同。MOSS模型的参数量比ChatGPT小了一个数量级。
然后是训练方式的不同。虽然MOSS也是自然语言模型基座训练+理解人类意图对话能力训练,但后者的训练方式与ChatGPT采用的RLHF不同。
复旦团队没有采取人工标注(指令微调)的方式来进行理解对话能力训练,而是基于与其他AI对话模型的交互来训练自己。
没错,相比人类调教,MOSS直接选择和其他AI模型进行对话……
最后是开放程度不同。ChatGPT背后模型目前还没有开源,但MOSS承诺会将代码开源。
说了这么多,MOSS的效果具体如何?
从官方给出示例来看,它问答和生成代码的能力似乎还不错。
在问答环节中,让MOSS列五部科幻片,分分钟就能给出(不过,《黑镜》好像是电视剧?):
做表格的速度也非常快:
在代码生成中,写个快速排序算法也没问题:
但与ChatGPT相比,MOSS的实测效果究竟如何呢?
知乎已经有匿名用户称已经拿到了内测资格,并实时更新了一波测试结果,我们将MOSS的回答与ChatGPT简单对比一下。
第一轮,先来看看写文章的能力。
例如“帮忙写一下国家自然科学基金申请,杰青那种”,MOSS回答如下:
我们把问题拿给ChatGPT后,得到了这样的回答:
第二轮,来看看写代码的能力。
这是MOSS给出的代码实现:
完整代码:for(i=1:length(mat文件中的名字)){name = mat文件中的名字[i];data = {name};fprintf(‘%s,’,name);}end for
这是ChatGPT给出的代码与回答:
第三轮,测试一下算法题的效果。
MOSS给出了一个实现思路:
ChatGPT则包办了代码和具体算法实现的流程:
最后一轮,再来看看做数学题的能力。
不过从功能介绍来看,MOSS应该还不具备解数学题的能力,这个问题确实不一定能回答出来。
ChatGPT则列了个方程解决这个问题:
整体来看,MOSS虽然在算法题上表现出了一定的逻辑,但在包括写文章、做数学题等具体解决方案的提供上,还有待继续训练提升。
“只是想验证ChatGPT技术路线”
针对种种疑问,团队也在官网上做出了回应。
首先,是MOSS与ChatGPT的差距上。团队表示,目前它还是一个非常不成熟的模型,距离ChatGPT还有很长的路需要走:
我们一个实验室无法做出和ChatGPT能力相近的模型,只是想在百亿规模参数上探索和验证ChatGPT的技术路线。
接下来,是针对服务器被挤爆的回应:
我们没想到会引起这么大关注,计算资源不足以支持如此大访问量,向大家致以真诚的歉意。
最后还有关于命名MOSS的回应:
就像过去NLP领域的其他优秀模型一样,作者们都希望使用自己喜欢的影视角色名称命名自己的模型。
此外,研究团队还在介绍网站中详细列出了MOSS的限制因素:
- 训练数据中的多语言语料库有限;
- 模型容量相对较小,不包含足够的世界知识;
- 执行方式比较迂回,甚至不按照指示执行;
- 可能会生产不道德或有害的内容;
……
总结下来,就是MOSS的回答不及ChatGPT就是因为它缺乏高质量的数据、计算资源以及模型容量。
不过,有意思的是,团队表示,在这些问题里面MOSS的最大短板是中文水平不够高。
具体来说,相较于英文问答能力,MOSS的中文问答水平要低很多,这也与前面提到的预训练模型学习数据量有关:
它的模型基座学习了3000多亿个英文单词,而互联网上的中文网页干扰信息如广告很多,清洗难度很大,导致中文词语只学了约300亿个。
目前,复旦大学NLP实验室正在加紧推进中文语料的清洗工作,清洗后的高质量中文语料也将用于下一阶段模型训练。
当然,和ChatGPT相比,MOSS也不是“一无是处”(手动狗头),起码它会在3月份开源代码。
而这一把也将会直接有效降低预训练语言模型的研发和应用门槛,属实是利好中小企业了,邱锡鹏教授也表示:
MOSS的计算量相对不那么大,中小企业都能用起来。
此外,研究团队对MOSS的“野心”似乎还不止于对话问答、写代码等这些ChatGPT拥有的功能。
在这次面向公众内测的同时,团队还透露出了MOSS的下一步计划:
结合复旦在人工智能和相关交叉学科的研究成果,赋予MOSS更多的能力,如绘图、语音、谱曲和教学,并加强它辅助科学家进行高效科研的能力等。
研究团队
MOSS是复旦大学自然语言处理实验室的成果,并且该项目还得到了上海人工智能实验室的支持。
研究团队由邱锡鹏带队,其余几位均为复旦大学NLP实验室的成员。
复旦大学自然语言处理实验室,是由复旦大学首席教授吴立德先生创建,是我国最早开展自然语言处理和信息检索研究的实验室之一。
目前实验室已经发表了大量高水平国际期刊和会议论文,其中包括中国计算机学会推荐的A/B类国际会议和期刊论文(ACL,SIGIR,IJCAI,AAAI,NIPS,ICML等)论文150余篇。
此外,复旦NLP实验室还发布了国内首家中文自然语言开源系统FudanNLP,被包括联合国教科文组织在内的国内外多家研发机构采用。
邱锡鹏,复旦大学计算机科学技术学院教授,博士生导师,研究方向为自然语言处理、深度学习,发表CCF-A/B类论文70余篇。
他还主持开发了开源自然语言处理工具:FudanNLP 、FastNLP,获得了学术界和产业界的广泛使用。
对于复旦MOSS模型的发布,你的看法是?
参考链接:
[1] https://txsun1997.github.io/blogs/moss.html
[2] https://www.shobserver.com/staticsg/res/html/web/newsDetail.html?id=584634
[3] https://www.zhihu.com/question/585248111/answer/2903204899
[4] https://xpqiu.github.io/index.html
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态





