
在ChatGPT风靡全球数月后,OpenAI终于发布了它的大型多模态模型(large multimodal model)GPT-4,它不仅能与用户一起生成、编辑,完成创意的迭代和技术写作任务,更重要的是,它还能读懂图片。
OpenAI称,GPT-4“比以往任何时候都更有创造性”,可以“更准确地解决问题”。官方在这次的发布过程中也提到一些合作方,包括Duolingo、Stripe、Khan Academy等。其中,引入GPT-4之后,改变最为明显的就是一款叫“Be My Eyes”的应用。
Be My Eyes在全世界拥有600多万名志愿者和视障与盲人用户,志愿者可以帮助用户介绍摄像头拍摄的画面。GPT-4成为这个平台上的第一个虚拟志愿者,用户可以向这个虚拟志愿者传送图像,提供即时识别、解释,并且以对话的形式提供协助。
以往的GPT-3.5无法将上述操作变成现实,因为它不具备识别图片的能力。这也是GPT-4作为一个大型多模态模型,与ChatGPT的GPT-3.5最大的不同之处。
简单来说,GPT-3.5能够在一定程度上理解并使用人类的语言,而GPT-4则是具备以人类的视角理解图像的能力。
官方给出的一些案例也令人惊艳,它可以帮你解释一些迷因梗图,或指出图片中不自然的地方,或是根据简单的几幅图片给出说明,甚至可以看图总结论文、回答试卷中的问题。
GPT-4清楚解释了上面这幅梗图的含义
GPT-4指出了图中不自然的地方
GPT-4分别解释了图中每一格的画面内容
GPT-4分别回答了图片中的问题
多模态对GPT-4这样的生成式AI来说意义重大,除了Be My Eyes的例子,未来还可望应用到一些设计工具和图像处理产品上,连OCR(光学字符识别)技术也要甘拜下风了。
视频翻译产品Targum Video的创办人Altryne也表示,GPT-4的图像理解能力已经甩开现有模型数里地。
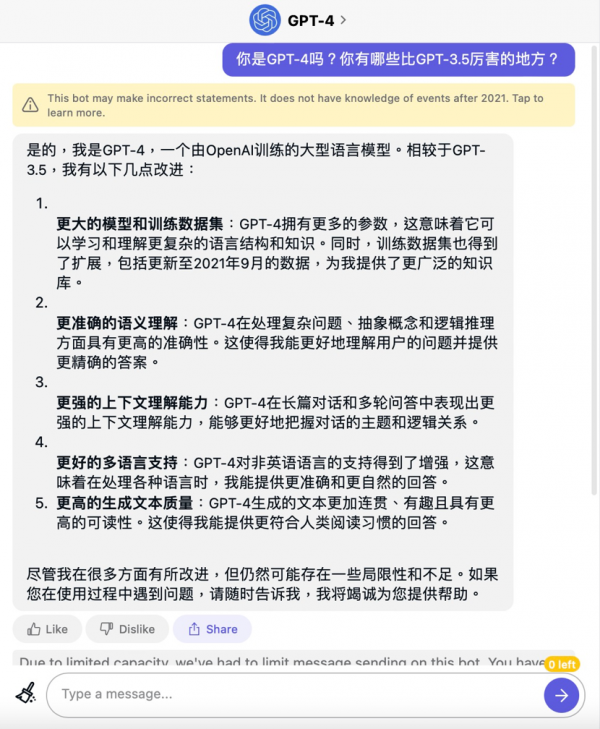
不过遗憾的是,OpenAI还没有把图像输入能力开放给公众体验,目前我们可以通过付费订阅ChatGPT Plus或Quora Poe来尝鲜。那么不会“看图说话”的GPT-4比GPT-3.5强在哪里呢?我们也通过Quora的Poe询问了一下GPT-4“本人”:
总的来说,相比GPT-3.5,GPT-4拥有更丰富的知识,对人类语言的理解能力也更准确,可以更好的理解整体对话的主题,不像以前那样一不小心就“歪楼”,非英语的语言理解能力也有所增强,生成的文本也会更连贯,可读性更高。
根据官方公布的数据,GPT-4不仅具备理解图片的能力,语言处理能力也有很大进步,GPT-4的中文能力已经超越GPT-3.5的英文能力了。
不过OpenAI CEO Sam Altman在Twitter上表示,GPT-4“仍然有局限性”,而且“第一次使用时似乎比你花更多时间使用它时更令人印象深刻”。
也就是说,仅从使用体验出发,GPT-4在语言能力上的改变更多体现在一些细微之处,不会像ChatGPT刚出现时那样惊为天人,不过对于多模态AI的实现来说,GPT-4的出现确也让人类再次迈出具有历史意义的一大步。





