
本指南将帮助您了解如何成为一名机器学习工程师。请注意,机器学习工程师的职位往往会因公司而异,这尤其取决于该公司的规模。在我们开始之前,请注意该路线图是有观点的,您可能与作者有不同的观点。话虽如此,我很想听听您的意见,并在合适的情况下将其纳入路线图中。我
该路线图主要针对机器学习工程而不是数据科学,但最好如果您了解端到端模型生命周期以及获得这份工作所需的工具/框架/库,其中也包括数据科学框架。该路线图也是根据模型生命周期来定向的,但流程是您应该学习这些技能的方式。该路线图还重点关注表格数据监督学习的机器学习工程,因为它是就业市场上最受欢迎的技能。稍后我将开始自然语言处理、强化学习和不同领域的机器学习。我还将添加我最喜欢的学习资源的链接。
完整的路线图
您将在下面的单个图像中找到完整版本的路线图,然后您将找到带有资源链接的部分路线图。

破解版本
您将在下面找到路线图的细分版本以及学习和掌握框架/库的资源链接。
选择语言
您可以用多种语言应用机器学习,但最流行的语言是 Python、R、Julia 和 MATLAB。本指南是为 Python 准备的,但您在整个生命周期中要做的事情是相同的。大多数机器学习库都是为 Python 构建的,因为没有编码背景的机器学习研究人员很容易学习它,并且人们可以将其用作用其他语言编写的代码的扩展。稍后我将添加另一个 R 路线图,其中包括您可以使用的包。我个人不推荐 MATLAB,因为它没有可供调试的广泛社区,它不是开源的,也不能为您提供其他人所提供的灵活性。
探索性数据分析
探索性数据分析是每个模型生命周期的基础。您必须发现数据中发生了什么。如果一个特征中有很多稀疏性,如果你的类不平衡,如果有很多缺失值,如果存在多重共线性,你必须在特征工程部分中摆脱这些,但首先你必须学习不同类型的可视化和分析。不要让这些吓倒您,它们很容易学习。你可以同时使用 matplotlib 和seaborn,我经常这样做,但如果你是初学者,我建议你先学习 matplotlib。您必须学习 pandas 和 numpy 并熟练掌握它们,以便轻松进行数据操作。
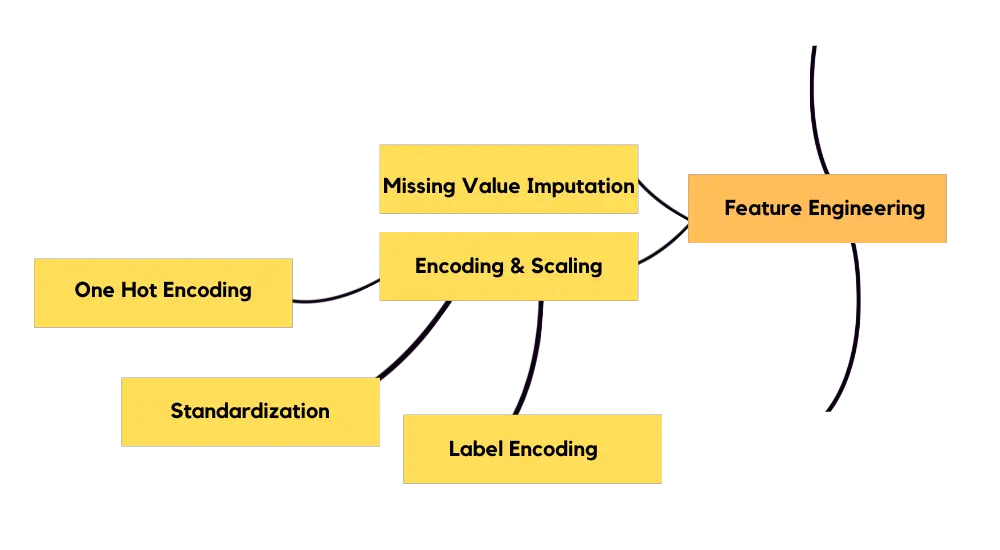
特征工程
您需要应用缺失值插补。您需要根据行或列的空白百分比来确定是否删除该行或列。缺失值插补的方法很少,例如,您可以插补列的平均值。如果您有数字列,则必须应用缩放。对于您的分类值,您需要应用编码。
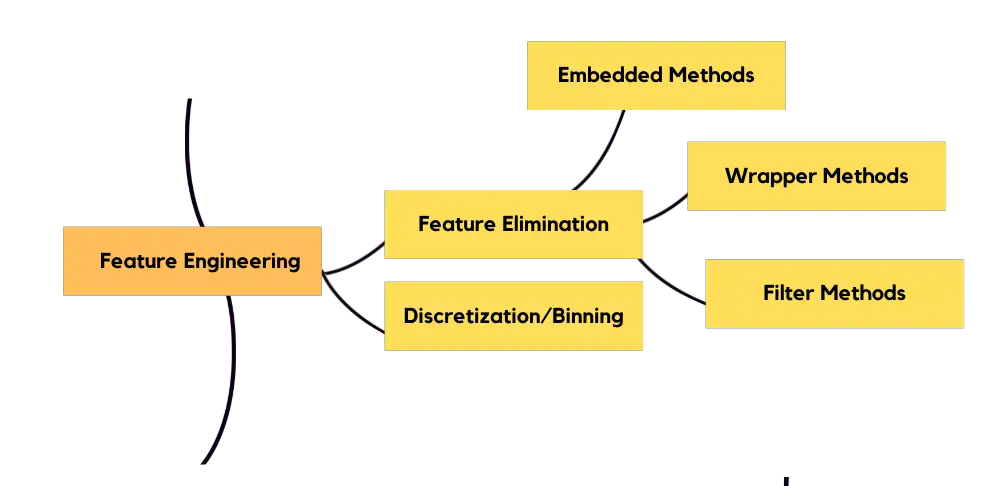
如果需要,您需要离散化数据。有一个称为维度灾难的问题,您需要为此删除一些特征,否则您的模型可能会感到困惑。有多种技术:
- 嵌入式方法:Lasso 正则化、岭正则化和 ElasticNet。
- 包装方法:递归特征消除(RFE)。
- 过滤方法:信息增益、卡方检验、相关性检验、Fisher 评分、LDA – 方差分析。你不需要学习所有这些,事实上 RFE 和卡方检验对于初学者来说就足够了。您可以使用 scikit-learn 实施特征工程
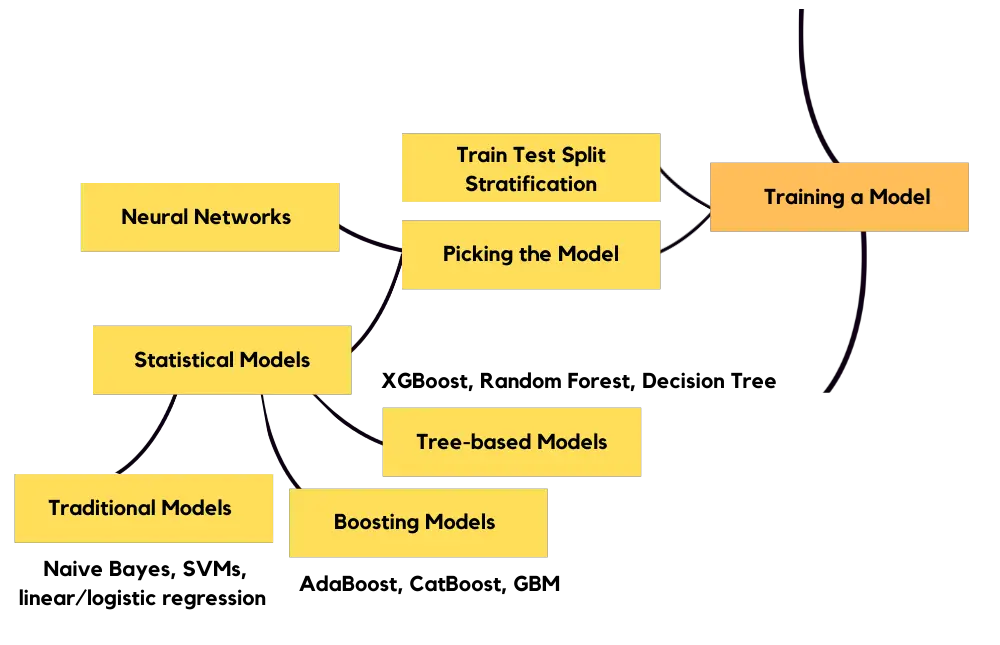
模型训练
完成必要的特征工程后,您就可以进行模型训练了。最好先学习统计方法,以掌握机器学习背后的逻辑。首先学习线性和逻辑回归是最好的入门方法,然后我建议您学习基于树的方法,因为它们是表格数据的最先进的方法。对于表格数据的初学者来说,神经网络是多余的。统计模型可以在 sci-kitlearn 中找到。 Tensorflow 和 PyTorch 包括神经网络应用程序。 Tensorflow 还包括基于树的算法。最好的入门方法是 scikit-learn、tensorflow,然后是 pytorch。
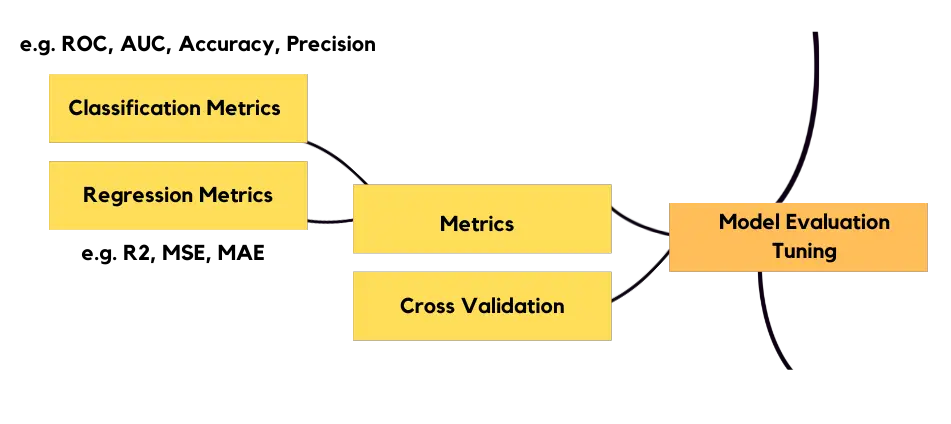
模型评估
您需要根据您要解决的问题,通过指标评估模型的表现。分类和回归指标是不同的。您需要对模型进行交叉验证,以便了解模型是否在数据中表现最佳。
您的模型将采用不同的超参数,您需要使用不同的搜索技术(例如网格搜索和随机搜索)来优化超参数。在模型评估期间,您需要跟踪您的实验并使它们井井有条。这些有不同的框架,您可以选择其中之一,完全取决于您。
将模型运送到生产和监控
小公司中的大多数机器学习工程师也负责将他们的模型运送到生产环境,为此,您可以使用 Flask 或 Django。两者之间的区别在于,Django 是一个一体化框架,而 Flask 为您提供了灵活性,就像玩乐高积木一样,这就是为什么 Flask 更适合初学者。您还需要了解模型监控,因为模型生命周期并不在将模型交付到生产时结束,您必须观察模型是否存在潜在的数据漂移。 Comet 的好处是您可以将其用于实验跟踪和模型监控。但是,您可以稍后再学习这些内容,因为这些是高级部分而不是入门部分。
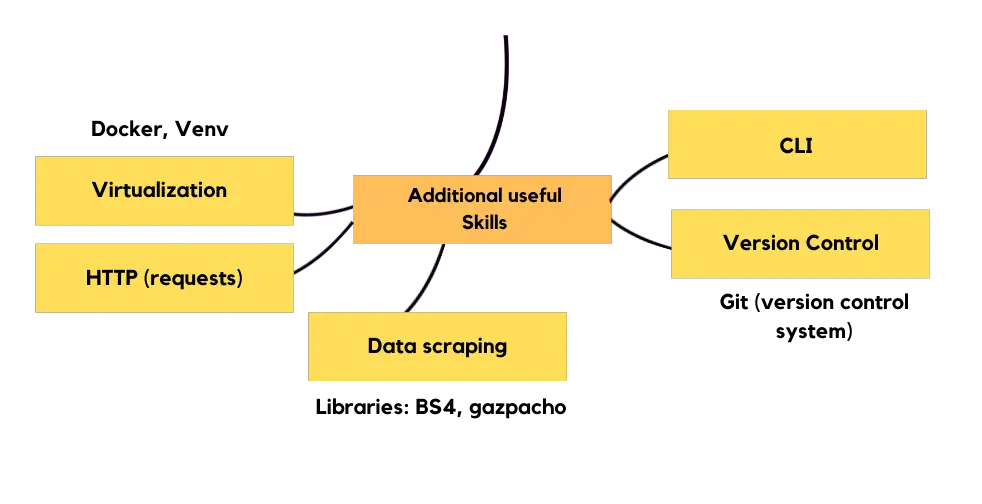
其他有用的技能
机器学习工程(模型生命周期除外)中最重要的两项技能是用于生产和版本控制的模型虚拟化。如果您是初学者,可以使用虚拟环境(conda、pyenv、python 环境或 pipelinev),我个人最喜欢的是 pyenv。为了更好地掌握你正在做的事情,我建议你学习命令行界面。我个人发现 HTTP 请求(从模型中获取预测)是工具包中一项很好的技能,如果您有学习空间,也可以学习异步,因为您会将预测请求放入队列中。当您需要更多数据或想要为自己的作品集创建个人项目时,使用 BeautifulSoup 和 gazpacho 等库进行数据抓取非常有用。
平我
如需任何建议、改进和反馈,请随时提交问题或通过 Twitter @mervenoyann 与我联系。





