

作者提供的图片
机器学习无疑是新时代的闪亮之星。它构成了各种主要技术的支柱,这些技术已成为我们日常生活不可或缺的一部分,例如面部识别(由卷积神经网络或 CNN 支持)、语音识别(利用 CNN 和循环神经网络或 RNN)以及日益流行的聊天机器人,例如ChatGPT(由人类反馈强化学习,RLHF 提供支持)。
如今有许多方法可以提高机器学习模型的性能。这些方法可以通过提供卓越的性能为您的项目带来竞争优势。
在本次讨论中,我们将深入研究特征选择技术领域。但在我们继续之前,让我们澄清一下:特征选择到底是什么?
什么是特征选择?
特征选择是为模型选择最佳特征的过程。此过程可能因一种技术而异,但主要目标是找出哪些功能对您的模型影响更大。
为什么我们要进行特征选择?
因为有时,拥有太多特征可能会损害您的机器学习模型。如何?
可能有太多不同的原因。例如,这些特征可能彼此相关,这可能会导致多重共线性,从而破坏模型的性能。
另一个潜在问题与计算能力有关。太多功能的存在需要更多的计算能力来同时执行任务,这可能需要更多的资源,从而增加成本。
当然,也可能还有其他原因。但这些示例应该可以让您大致了解潜在问题。然而,在我们进一步深入研究这个主题之前,还有一个更重要的方面需要了解。
哪种特征选择方法更适合我的模型?
是的,这是一个很好的问题,应该在项目开始之前得到回答。但给出一个通用的答案并不容易。
特征选择模型的选择取决于您拥有的数据类型和项目的目标。
例如,基于过滤器的方法(例如卡方检验或互信息增益)通常用于分类数据中的特征选择。基于包装的方法(例如前向或后向选择)适用于数值数据。
然而,很高兴知道许多特征选择方法可以处理分类数据和数值数据。
例如,套索回归、决策树和随机森林可以很好地处理这两种类型的数据。
就监督和无监督特征选择而言,递归特征消除或决策树等监督方法适用于标记数据。主成分分析 (PCA) 或独立成分分析 (ICA) 等无监督方法用于未标记数据。
最终,特征选择方法的选择应基于数据的具体特征和项目的目标。
查看我们将在本文中讨论的主题的概述。让自己熟悉一下,让我们从监督特征选择技术开始。
作者提供的图片
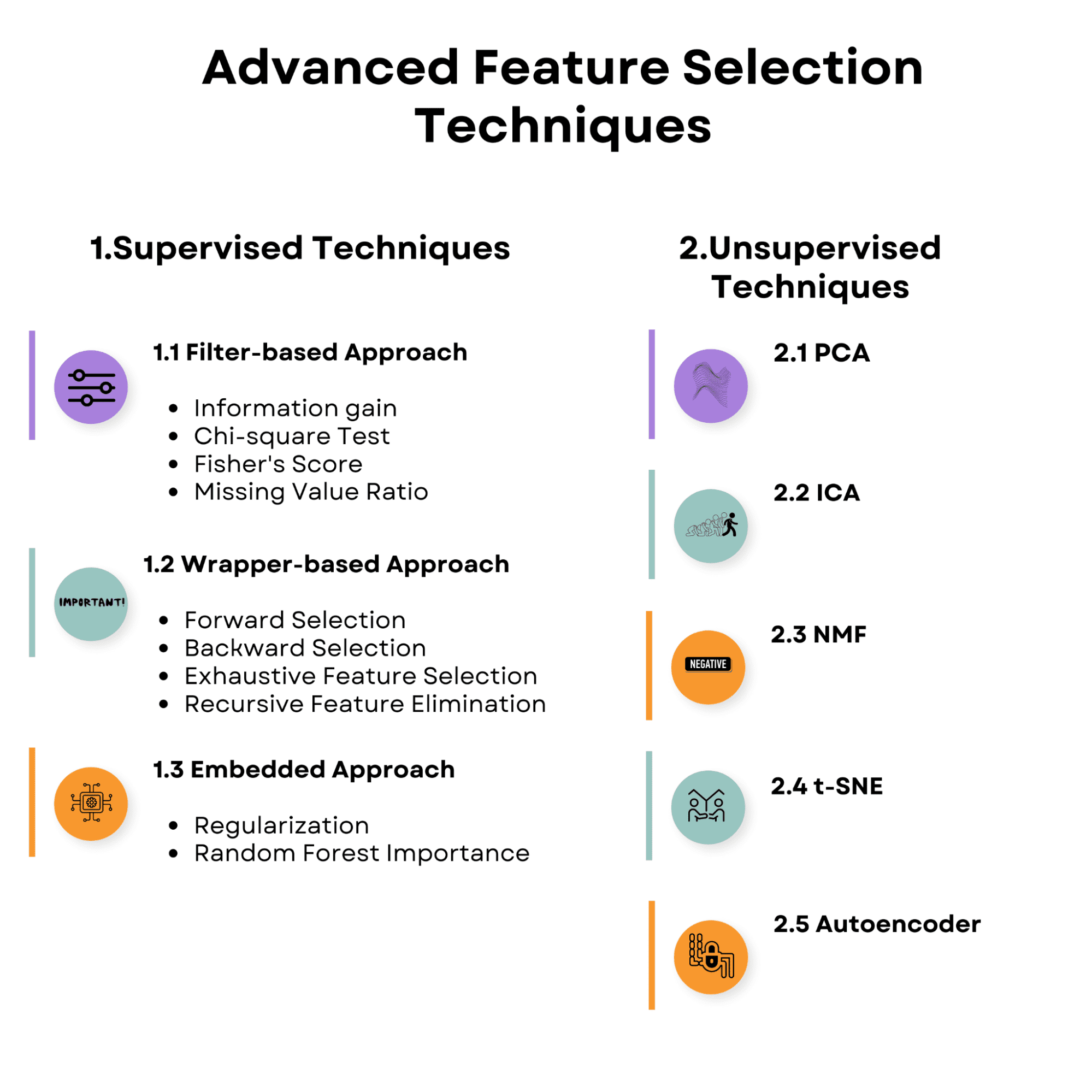
1.有监督的特征选择技术
监督学习中的特征选择策略旨在利用输入特征与目标变量之间的关系来发现预测目标变量最相关的特征。这些策略可能有助于提高模型性能、减少过度拟合并降低训练模型的计算成本。
这是我们将要讨论的监督特征选择技术的概述。
作者提供的图片
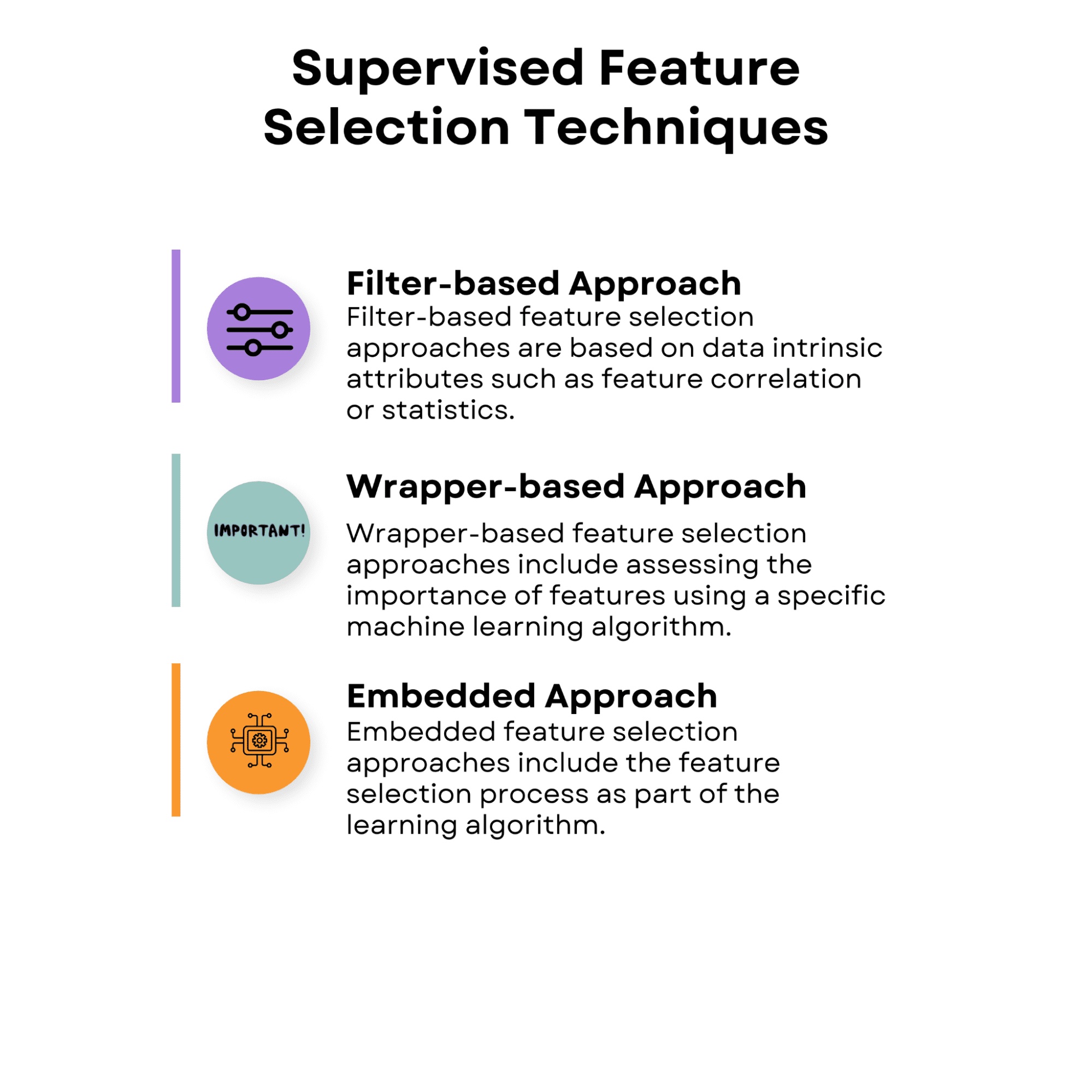
1.1 基于过滤器的方法
基于过滤器的特征选择方法基于数据内在属性,例如特征相关性或统计数据。这些方法单独或成对评估每个特征的值,而不考虑特定学习算法的性能。
基于过滤器的方法计算效率高,并且可以与各种学习算法一起使用。然而,由于它们没有考虑特征和学习方法之间的相互作用,因此它们可能并不总是捕获特定算法的理想特征子集。
看一下基于过滤器的方法的概述,然后我们将分别讨论。

作者提供的图片
信息增益
信息增益是一种统计量,通过根据特定特征划分数据来衡量该特征的熵(不确定性)的减少。它经常用于决策树算法,并且也具有有用的功能。特征的信息增益越高,对于决策就越有用。
现在,让我们通过使用预先构建的糖尿病数据集来应用信息增益。
糖尿病数据集包含与预测糖尿病进展相关的生理特征。
- 年龄:年龄
- 性别:性别(1 = 男,0 = 女)
- BMI:身体质量指数,计算方法为体重(公斤)除以身高(米)的平方
- bp:平均血压(毫米汞柱)
- s1、s2、s3、s4、s5、s6:六种不同血液化学物质(包括葡萄糖)的血清测量,
以下代码演示了如何应用信息增益方法。此代码使用 sklearn 库中的糖尿病数据集作为示例。
该代码的主要目标是根据信息增益计算特征重要性得分,这有助于识别预测模型最相关的特征。通过确定这些分数,您可以就在分析中包含或排除哪些特征做出明智的决定,最终提高模型性能、减少过度拟合并缩短训练时间。
为了实现这一目标,此代码计算数据集中每个特征的信息增益分数并将其存储在字典中。
然后根据分数对特征进行降序排序。
我们将把排序后的特征重要性分数可视化为水平条形图,使您可以轻松比较给定任务的不同特征的相关性。
在构建机器学习模型时决定保留或丢弃哪些特征时,这种可视化特别有用。
让我们看看完整的代码。
这是输出。
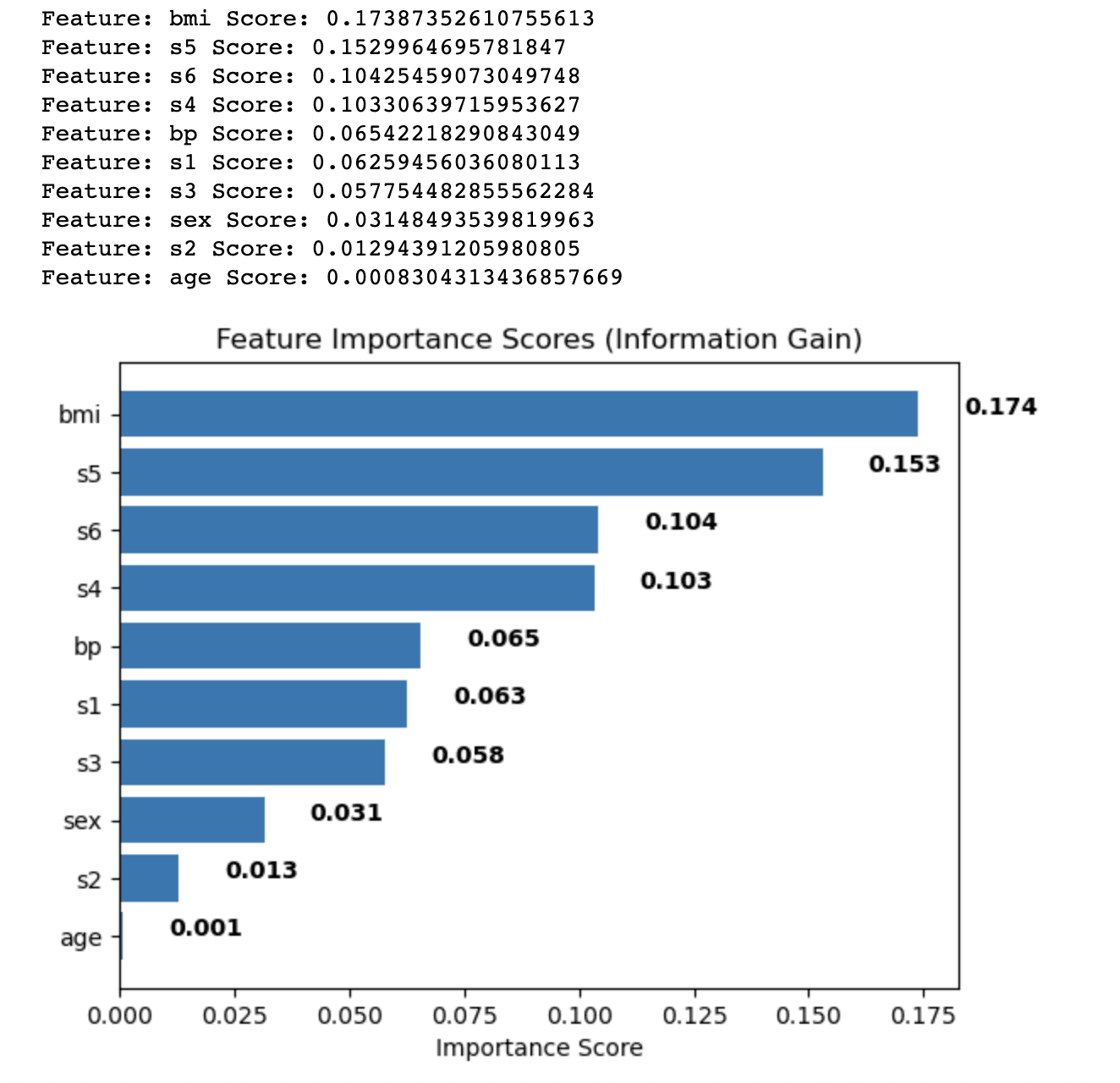
输出显示使用信息增益方法计算出的糖尿病数据集中每个特征的特征重要性得分。这些特征根据其得分按降序排列,这表明它们在预测目标变量中的相对重要性。
结果如下:
- 体重指数 (bmi) 的重要性得分最高 (0.174),表明它对糖尿病数据集中的目标变量影响最显着。
- 血清测量 5 (s5) 的得分为 0.153,使其成为第二重要的特征。
- 血清测量 6 (s6)、血清测量 4 (s4) 和血压 (bp) 具有中等重要性评分,范围为 0.104 至 0.065。
- 其余特征,例如血清测量值 1、2 和 3(s1、s2、s3)、性别和年龄,重要性得分相对较低,表明它们对模型的预测能力贡献较小。
通过分析这些特征重要性分数,您可以决定在分析中包含或排除哪些特征,以提高机器学习模型的性能。在这种情况下,您可能会考虑保留具有较高重要性分数的特征(例如 bmi 和 s5),同时可能删除或进一步研究具有较低重要性分数的特征(例如年龄和 s2)。
卡方检验
卡方检验是一种统计检验,用于评估两个分类变量之间的关系。它用于特征选择,分析分类特征与目标变量之间的关系。卡方得分越大,表明特征与目标之间的联系越强,表明该特征对于分类工作更重要。
虽然卡方检验是一种常用的特征选择方法,但它通常用于特征和目标变量是离散的分类数据。
费舍尔评分
Fisher 判别比,通常称为 Fisher 分数,是一种特征选择方法,根据特征区分数据集中不同类别的能力对特征进行排名。它可用于分类问题中的连续特征。
Fisher 得分计算为类间方差和类内方差之比。费舍尔得分越高,意味着该特征更具辨别力并且对于分类更有价值。
要使用 Fisher 分数进行特征选择,请计算每个连续特征的分数,并根据分数对它们进行排名。该模型认为费舍尔得分较高的特征更重要。
缺失值比率
缺失值比率是一种简单的特征选择方法,它根据特征中缺失值的数量做出决策。
具有大量缺失值的特征可能无法提供信息,并且可能会损害模型的性能。您可以通过指定可接受的缺失值比率的阈值来过滤掉缺失值过多的要素。
要使用缺失值比率进行特征选择,请执行以下步骤:
- 通过将缺失值的数量除以数据集中实例的总数来计算每个特征的缺失值比率。
- 设置可接受的缺失值比率的阈值(例如,0.8,这意味着某个特征最多应有 80% 的缺失值被考虑)。
- 过滤掉缺失值比率高于阈值的特征。
1.2 基于包装的方法
基于包装器的特征选择方法包括使用特定的机器学习算法评估特征的重要性。他们通过试验各种特征组合并使用所选方法评估其性能来寻求最佳的特征子集。
由于可用特征子集数量巨大,基于包装器的方法的计算成本可能很高,尤其是在处理高维数据集时。
然而,它们通常优于基于过滤器的方法,因为它们考虑了特征和学习算法之间的关系。
作者提供的图片
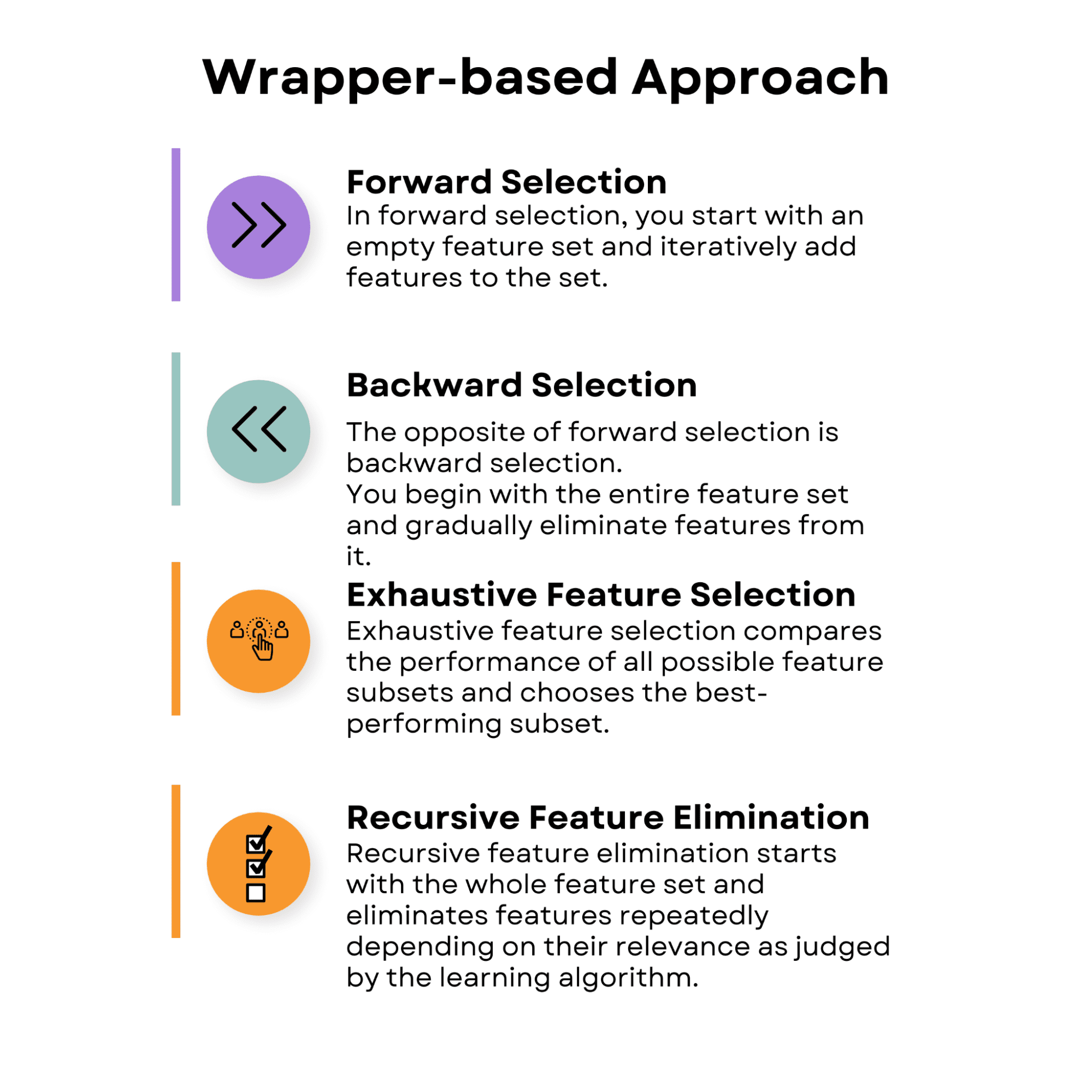
向前选择
在正向选择中,您从一个空的特征集开始,然后迭代地将特征添加到该集中。在每个步骤中,您都可以使用当前特征集和附加特征来评估模型的性能。带来最佳性能改进的功能将添加到集合中。
该过程将持续进行,直到观察到性能没有显着改善,或者达到预定义的功能数量。
以下代码演示了前向选择的应用,这是一种基于包装器的监督特征选择技术。
该示例使用 sklearn 库中的乳腺癌数据集。乳腺癌数据集,也称为威斯康星州诊断乳腺癌 (WDBC) 数据集,是常用的预构建分类数据集。在这里,主要目标是建立预测模型来诊断乳腺癌为恶性(癌性)或良性(非癌性)。
为了我们的模型,我们将选择不同数量的特征来查看性能如何相应变化,但首先,让我们加载库、数据集和变量。
该代码的目标是使用前向选择来识别逻辑回归模型的最佳特征子集。该技术从一组空特征开始,并根据指定的评估指标迭代添加可提高模型性能的特征。在这种情况下,使用的指标是准确性。
代码的下一部分使用 mlxtend 库中的 SequentialFeatureSelector 来执行前向选择。它配置有逻辑回归模型、所需的特征数量和 5 折交叉验证。将前向选择对象拟合到训练数据,并打印所选特征。
此外,我们需要评估所选特征在测试集上的性能,并在折线图中可视化具有不同特征子集的模型性能。
该图表将显示交叉验证的准确性作为特征数量的函数,提供对模型复杂性和预测性能之间权衡的见解。
通过分析输出和图表,您可以确定模型中包含的最佳特征数量,最终提高其性能并减少过度拟合。
这是完整的代码。
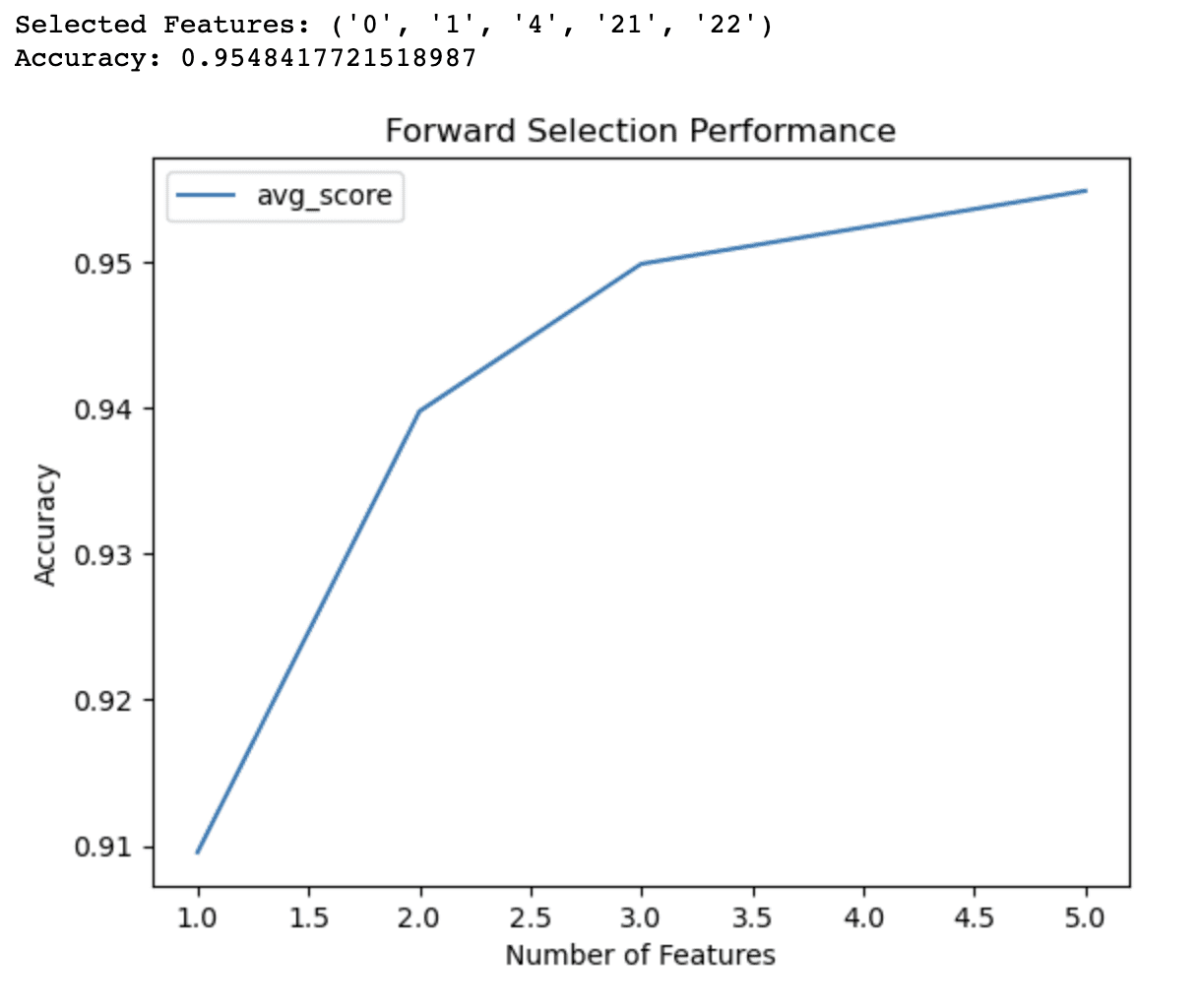
前向选择代码的输出表明,该算法已识别出 5 个特征的子集,这些特征为乳腺癌数据集上的逻辑回归模型提供了最佳准确度 (0.9548)。这些选定的特征通过它们的索引来标识:0、1、4、21 和 22。
折线图提供了对具有不同特征数量的模型性能的额外见解。它表明:
- 仅使用 1 个特征,该模型的准确率就达到 91% 左右。
- 添加第二个特征可将准确率提高到 94%。
- 有了3个特征,准确率进一步提高到95%。
- 包含 4 个特征使准确率略高于 95%。
超过 4 个特征后,准确性的提升就变得不那么显着了。此信息可以帮助您就模型复杂性和预测性能之间的权衡做出明智的决策。根据这些结果,您可能决定在模型中仅使用 3 或 4 个特征来平衡准确性和简单性。
向后选择
与前向选择相反的是后向选择。您从整个功能集开始,并逐渐从中消除功能。
在每个阶段,您都使用当前特征集减去要删除的特征来衡量模型的性能。
导致性能下降最少的功能将从集合中消除。
重复该过程,直到性能没有显着提高或达到预设数量的功能。
向后和向前选择被归类为顺序特征选择;您可以在这里了解更多信息。
详尽的特征选择
详尽的特征选择会比较所有可能的特征子集的性能并选择性能最佳的子集。这种方法的计算要求很高,尤其是对于大型数据集,但它确保了最佳的特征子集。
递归特征消除
递归特征消除从整个特征集开始,根据学习算法判断的相关性来重复消除特征。每一步都会删除最不重要的特征,并重新训练模型。重复该方法直到获得预定数量的特征。
1.3 嵌入式方法
嵌入式特征选择方法包括作为学习算法一部分的特征选择过程。
这意味着在整个训练阶段,学习算法不仅优化模型参数,而且选择最重要的特征。嵌入式方法比包装方法更有效,因为它们不需要外部特征选择过程。
作者提供的图片
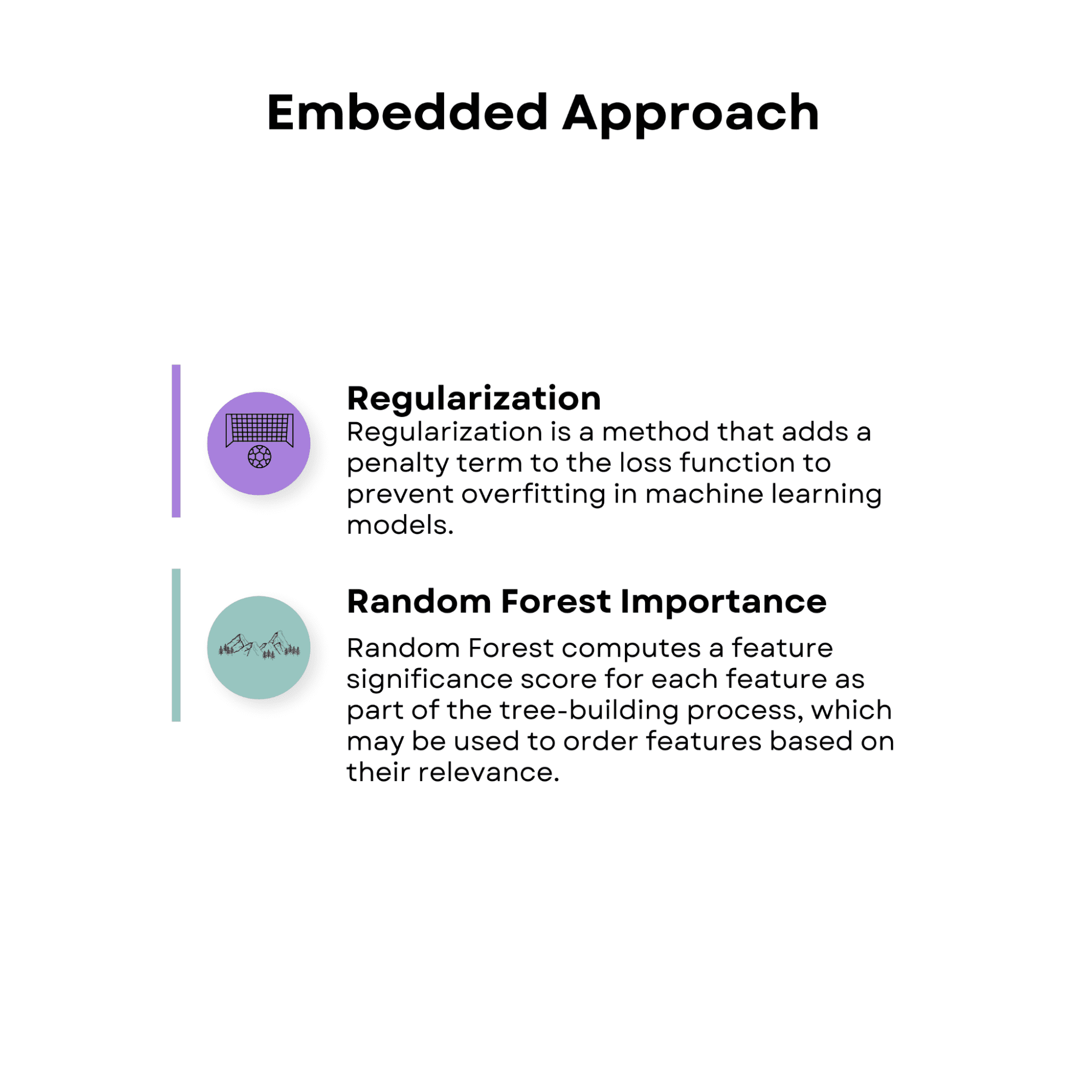
正则化
正则化是一种在损失函数中添加惩罚项以防止机器学习模型中过度拟合的方法。
正则化方法,例如 lasso(L1 正则化)和 ridge(L2 正则化),可以与特征选择结合使用,将不太重要的特征的系数降低到零,从而选择最相关特征的子集。
随机森林重要性
随机森林是一种集成学习方法,结合了多个决策树的预测。作为树构建过程的一部分,随机森林计算每个特征的特征重要性得分,这可用于根据特征的相关性对特征进行排序。该模型认为具有较高重要性评级的特征更重要。
如果你想了解更多关于随机森林的知识,这里有一篇文章《决策树和随机森林算法》,它也解释了决策树算法。
以下示例使用 Covertype 数据集,其中包含有关不同类型森林覆盖的信息。
Covertype 数据集的目的是预测北科罗拉多州罗斯福国家森林内的森林覆盖类型(主要树种)。
以下代码的主要目标是使用随机森林分类器确定特征的重要性。通过评估每个特征对整体分类性能的贡献,该方法有助于识别构建预测模型最相关的特征。
然后,我们创建一个 RandomForestClassifier 对象并将其拟合到训练数据中。然后,它从训练模型中提取特征重要性并按降序对它们进行排序。根据重要性分数选择前 10 个特征并按排名显示。
此外,该代码还使用水平条形图可视化前 10 个特征重要性。
这种可视化可以轻松比较重要性分数,并有助于就在分析中包含或排除哪些功能做出明智的决定。
通过检查输出和图表,您可以为预测模型选择最相关的特征,这有助于提高其性能、减少过度拟合并加快训练时间。
这是完整的代码。
这是输出。
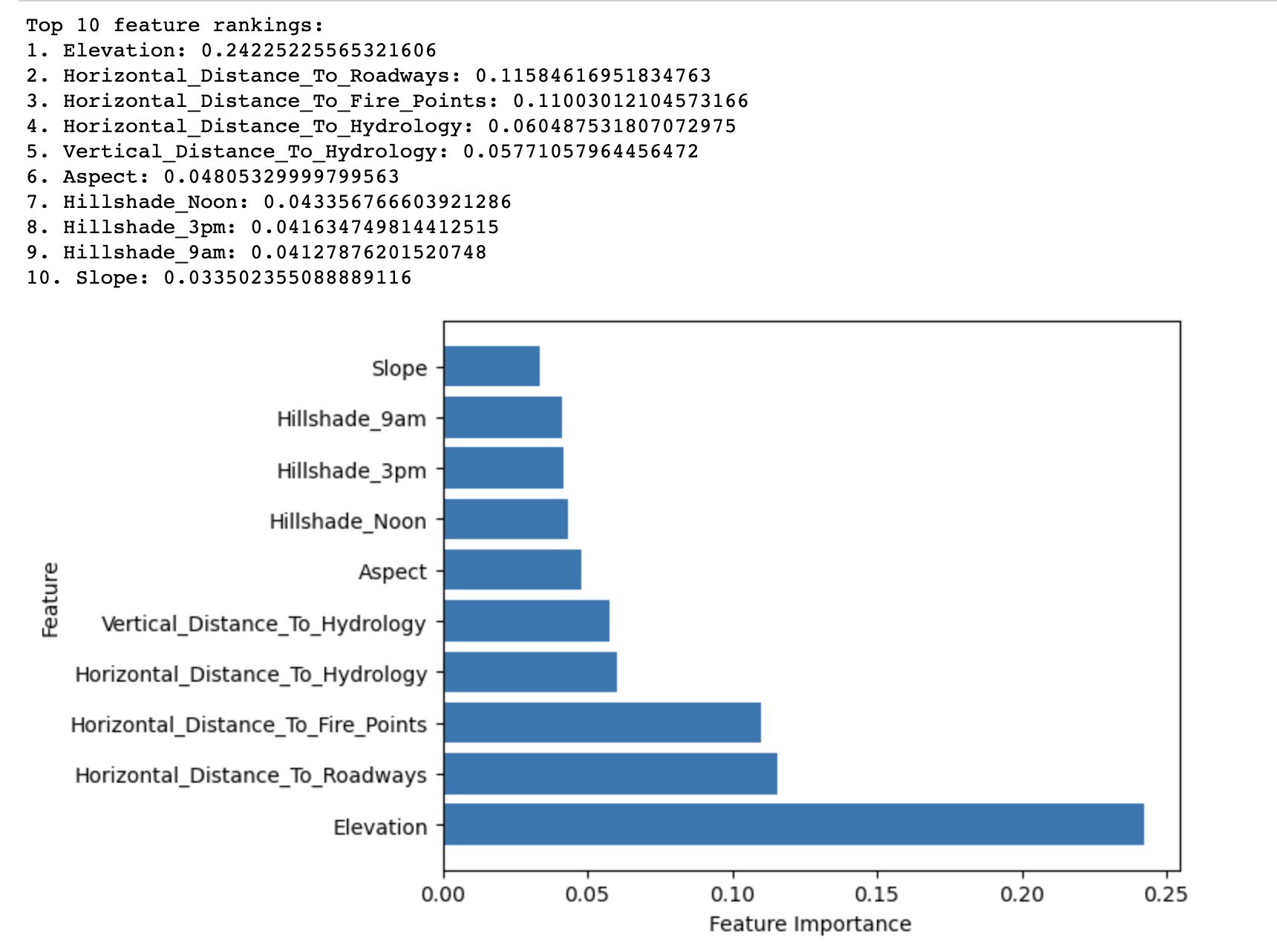
随机森林重要性方法的输出显示按在 Covertype 数据集中预测森林覆盖类型的重要性排列的前 10 个特征。
结果表明,在预测森林覆盖类型的所有特征中,海拔的重要性得分最高(0.2423)。这表明海拔在确定罗斯福国家森林的优势树种方面起着至关重要的作用。
其他具有相对较高重要性分数的要素包括 Horizontal_Distance_To_Roadways (0.1158) 和 Horizontal_Distance_To_Fire_Points (0.1100)。这些表明,靠近道路和着火点也会显着影响森林覆盖类型。
前 10 个列表中的其余特征的重要性分数相对较低,但它们仍然对模型的整体预测性能有贡献。这些特征主要与水文因素、坡度、坡向和山体阴影指数有关。
综上所述,结果突出了影响罗斯福国家森林森林覆盖类型分布的最重要因素,可用于建立更有效和高效的森林覆盖类型分类预测模型。
2.无监督特征选择技术
当没有可用的目标变量时,可以使用无监督特征选择方法来降低数据集的维度,同时保持其底层结构。这些方法通常包括将初始特征空间更改为新的低维空间,其中更改的特征捕获数据中的大部分变化。

作者提供的图片
2.1 主成分分析(PCA)
PCA是一种线性降维方法,将原始特征空间转换为由主成分定义的新的正交空间。这些分量是为捕获数据中最高水平的方差而选择的原始特征的线性组合。
PCA 可用于挑选代表大部分变化的前 k 个主成分,从而降低数据集的维数。
为了向您展示其在实践中的工作原理,我们将使用 Wine 数据集。这是一个广泛用于机器学习中分类和特征选择任务的数据集,由 178 个样本组成,每个样本代表来自意大利同一地区三个不同品种的不同葡萄酒。
使用葡萄酒数据集的目标通常是构建一个预测模型,该模型可以根据葡萄酒样本的化学特性将其准确分类为三个品种之一。
以下代码演示了主成分分析(PCA)(一种无监督特征选择技术)在 Wine 数据集上的应用。
这些组件(主要组件)捕获数据中的最大方差,同时最大限度地减少信息损失。
该代码首先加载 Wine 数据集,该数据集包含 13 个描述不同葡萄酒样品化学性质的特征。
然后使用 StandardScaler 对这些特征进行标准化,以确保 PCA 不会受到输入特征不同尺度的影响。
接下来,使用 sklearn.decomposition 模块中的 PCA 类对标准化数据执行 PCA。
计算每个主成分的解释方差比,表示每个成分解释的数据占总方差的比例。
最后,生成两个图来可视化主成分的解释方差比和累积解释方差。
第一个图显示了每个单独主成分的解释方差比,而第二个图说明了累积解释方差如何随着包含更多主成分而增加。
这些图有助于确定模型中使用的主成分的最佳数量,平衡降维和信息保留之间的权衡。
让我们看看完整的代码。
这是输出。
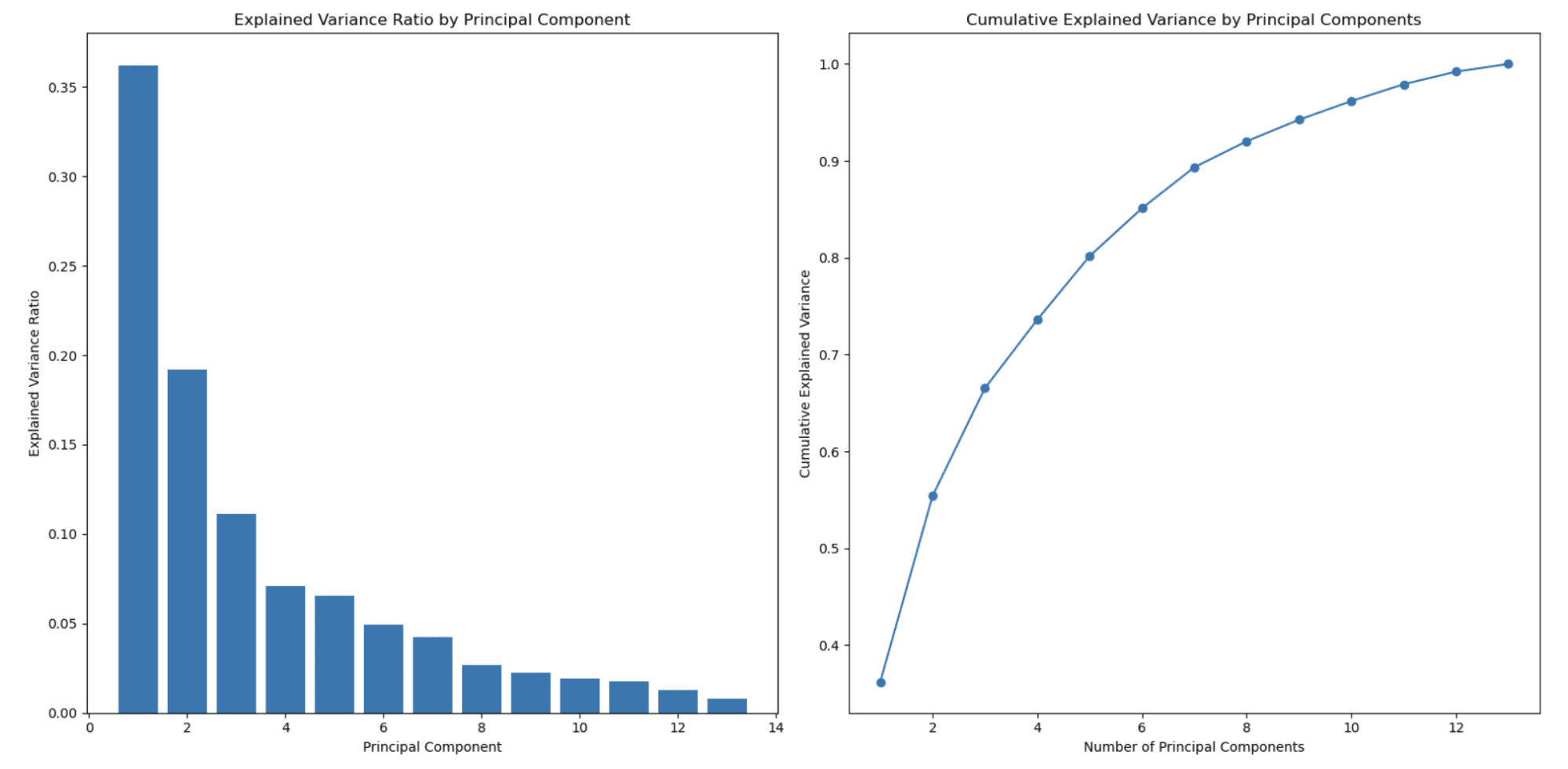
左图显示,解释的方差比随着主成分数量的增加而减小。这是在 PCA 中观察到的典型行为,因为主成分是按它们解释的方差量排序的。
第一个主成分(特征)捕获最高方差,第二个主成分捕获第二高量,依此类推。因此,解释的方差比随着每个后续主成分而减小。
这是PCA用于降维的主要原因之一。
右侧第二个图显示累积解释方差,并帮助您确定选择多少个主成分(特征)来表示数据的百分比。 x 轴表示主成分的数量,y 轴表示累积解释方差。当您沿着 x 轴移动时,您可以看到当您包含那么多主成分时保留了多少总方差。
在此示例中,您可以看到,选择大约 3 或 4 个主成分已经捕获了超过 80% 的总方差,而选择大约 8 个主成分则捕获了超过 90% 的总方差。
您可以根据降维和要保留的方差之间所需的权衡来选择主成分的数量。
在这个例子中,我们确实使用了Sci-kit来学习应用PCA,在这里你可以找到官方文档。
2.2 独立成分分析(ICA)
ICA 是一种将多维信号分解为其分量的方法。
在特征选择的背景下,ICA 可用于将原始特征空间转换为由统计独立分量表征的新空间。您可以通过选择前 k 个独立分量来降低数据集的维数,同时保持底层结构。
2.3 非负矩阵分解(NMF)
非负矩阵因子 (NMF) 是一种降维方法,将非负数据矩阵近似为两个低维非负矩阵的乘积。
NMF 可用于特征选择的背景下,提取一组新的基本特征,以捕获原始数据的重要结构。您可以通过选择前 k 个基本特征来最小化数据集的维数,同时保持非负性限制。
2.4 t分布随机邻域嵌入(t-SNE)
t-SNE 是一种非线性降维方法,试图通过减少高维和低维位置中成对概率分布之间的差异来保留数据集的结构。
t-SNE 可应用于特征选择,将原始特征空间投影到保持数据结构的低维空间,从而增强可视化和评估。
您可以在“无监督学习算法”中找到有关无监督算法和 t-SNE 的更多信息。
2.5 自动编码器
自动编码器是一种人工神经网络,它学习将输入数据编码为低维表示,然后将其解码回原始版本。自动编码器的低维表示可用于生成另一组捕获原始数据底层结构的特征。
最后的话
总之,特征选择在机器学习中至关重要。它有助于降低数据的维度,最大限度地降低过度拟合的风险,并提高模型的整体性能。选择正确的特征选择方法取决于具体问题、数据集和建模要求。
本文涵盖了广泛的特征选择技术,包括监督和无监督方法。
监督技术,例如基于过滤器、基于包装器和嵌入式方法,使用特征和目标变量之间的关系来识别最重要的特征。
无监督技术,如 PCA、ICA、NMF、t-SNE 和自动编码器,专注于数据的内在结构以降低维度,而不考虑目标变量。
在为模型选择合适的特征选择方法时,考虑数据的特征、每种技术的基本假设以及所涉及的计算复杂性至关重要。
通过仔细选择和应用正确的特征选择技术,您可以显着提高性能,从而获得更好的见解和决策。
是一名数据科学家,负责产品策略。他还是教授分析学的兼职教授,并且是 StrataScratch 的创始人,该平台帮助数据科学家利用顶级公司的真实面试问题准备面试。在 Twitter 上与他联系:StrataScratch 或 LinkedIn。





