
强化学习:简介
从“强化”这个词我们得到了建立具有正反馈的模式或信念系统的想法。通过强化学习,我们的目标是创建算法,帮助代理在特定环境中获得最佳性能,并获得适当的奖励。让我们考虑两种情况,为RL提供抽象的洞察力。
积极和消极的奖励会增加或减少该行为的倾向。最终在一段时间内在该环境中取得更好的结果。
让我们首先定义agent 和environment 的概念,以了解有关RL的技术细节。environment 是agent 的世界,它通过对其执行的给定action来改变agent的状态。agent是通过传感器感知环境并使用执行器执行zctions的系统。在上述情况下,荷马(左)和巴特(右)是我们的agents,世界是他们的环境。他们通过获得快乐作为奖励来对其采取actions并改善他们的存在状态。在本文中,我们将设计我们自己的agent,该代理执行actions以通过OpenAI gym实现目标。
最新进展和范围
从IBM的Deep Blue v / s Kasparov到AlpaGo v / s Lee Sedol,深度强化学习已经深入人心。最近在OpenAI创建Dota机器人方面取得的突破和胜利也是值得称道的,机器人经过训练可以处理复杂和动态的环境。掌握这些游戏是为了测试可以创建的AI代理的限制,以处理非常复杂的情况。已经有很复杂的应用,如无人驾驶汽车,智能无人机在现实世界中运行。让我们了解强化学习的基础知识,并从OpenAI Gym开始制作我们自己的Agent。在此之后转向Deep RL并解决更复杂的情况。其应用范围超乎想象,可以应用于许多领域。
在同一状态上反复运行算法的独特能力,帮助它学习该状态下的最佳动作,本质上相当于打破时间的构造,让人类几乎不需要时间就能获得无限的学习体验。
Policy Gradients with Monte Carlo Look Search Tree
这有什么不同?
主要有三种学习方式:监督学习,无监督学习和强化学习。让我们看看他们的基本差异。在监督学习中,我们尝试预测目标值或类,其中训练的输入数据已经分配了标签。无监督学习使用未标记数据来查看模式以进行聚类,PCA或异常检测。RL算法是优化程序,以找到获得最大奖励的最佳方法,即给予获胜策略以达到目标。
考虑不同学习类型的用例
概念性理解
使用强化学习(RL)作为框架代理,通过某些动作来转换代理的状态,每个动作都与奖励值相关联。它还使用策略来确定将状态映射到操作的下一个操作。策略可以是确定性的和随机的,找到最优政策是关键。不同状态下的不同动作将具有不同的奖励值,例如在Pocket Tanks游戏中的“Fire”命令,因为有时候保留一个战略上良好的位置会更好。为了解决这个问题,我们需要将 state-action pair映射到奖励的 Q-value(action-value)。现在定义环境在RL的上下文中作为函数,它在给定状态下将动作作为输入并返回与动作状态对相关联的新状态和奖励值。当环境变得复杂时,神经网络能够轻松地学习 state-action pairs奖励,这被称为Deep RL。
对于像Mario Q-learning这样的游戏,可以使用卷积神经网络(CNN)损失近似值。
在这里,我们将仅限于Q-Learning,其中Q将 state-action pairs 映射到最大值,并结合即时奖励和未来奖励,即对于新状态,学习价值是奖励加上未来的奖励估计。将其量化为具有不同参数的等式,例如学习率和折扣因子,以减慢Agent的行动选择。我们得出以下等式。
Q函数方程,说明给定对的最大预期累积奖励
使用OpenAI Gym
为何选择OpenAI gym?这个python库为我们提供了大量的测试环境来处理RL代理的算法,这些算法具有用于编写通用算法和测试它们的共享接口。让我们开始只需键入pip install gym终端以便于安装,您将获得一些经典的环境来开始处理您的Agent。复制下面的Python代码并运行它,您的环境将只加载经典控件作为默认值。
# 1. It renders instance for 500 timesteps, perform random actions
import gym
env = gym.make('Acrobot-v1')
env.reset()
for _ in range(500):
env.render()
env.step(env.action_space.sample())
# 2. To check all env available, uninstalled ones are also shown
from gym import envs
print(envs.registry.all())
当对象通过动作与环境交互时,则step(...)函数返回observation(表示环境状态),reward(前一个动作中的奖励浮动),done(到达重置环境时间或目标实现),info:a dict for debugging,如果它包含环境最后状态的原始概率,则可用于学习。看看它怎么运作。另外,观察Space类型的observation在不同环境下是如何不同的。
Python代码如下:
import gym
env = gym.make('MountainCarContinuous-v0') # try for different environements
observation = env.reset()
for t in range(100):
env.render()
print observation
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
print observation, reward, done, info
if done:
print("Finished after {} timesteps".format(t+1))
break
[Output For Mountain Car Env:]
[-0.56252328 0.00184034]
[-0.56081509 0.00170819] -0.00796802138459 False {}
[Output For CartPole Env:]
[ 0.1895078 0.55386028 -0.19064739 -1.03988221]
[ 0.20058501 0.36171167 -0.21144503 -0.81259279] 1.0 True {}
Finished after 52 timesteps
上面代码中的action_space是什么?action-space&observation-space描述了要处理的特定环境的有效格式。只需看看返回的值。
import gym
env = gym.make('CartPole-v0')
print(env.action_space) #[Output: ] Discrete(2)
print(env.observation_space) # [Output: ] Box(4,)
env = gym.make('MountainCarContinuous-v0')
print(env.action_space) #[Output: ] Box(1,)
print(env.observation_space) #[Output: ] Box(2,)
离散值是非负的可能值,大于0或1相当于左右移动以达到笛卡儿平衡。Box表示n-dim数组。这些有助于编写针对不同环境的通用代码。我们可以简单地检查bounds .observation_space。将它们编码到我们的通用算法中。
说明
我建议在了解OpenAI Gym的基础知识后,您可以安装Gym的所有依赖项,然后使用以下命令完全安装gym。在这里,我们使用python2.x你也可以使用python3.x只需更改下面的命令。
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
sudo pip install 'gym[all]'
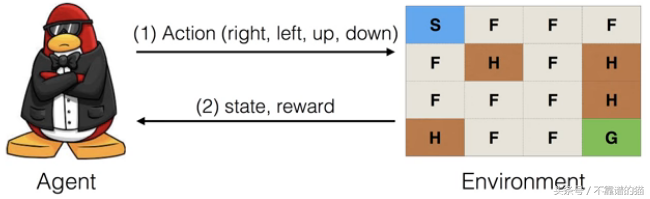
让我们开始构建我们的Q-table算法,它将尝试解决FrozenLake 环境。在这种环境中,目标是在一个可能有一些洞的冰冻湖面上达到目标。以下是该算法描述表面的方式。
SFFF (S: starting point, safe)
FHFH (F: frozen surface, safe)
FFFH (H: hole, fall to your doom)
HFFG (G: goal, where the frisbee is located)
Q表包含映射到奖励的state-action pairs。因此,我们将构建一个数组,该数组在算法运行期间映射不同的状态和动作以奖励值。它的维度将明确| state | x | actions |。让我们把它写在Q-learning算法的Python代码中。
import gym
import numpy as np
# 1. Load Environment and Q-table structure
env = gym.make('FrozenLake8x8-v0')
Q = np.zeros([env.observation_space.n,env.action_space.n])
# env.obeservation.n, env.action_space.n gives number of states and action in env loaded
# 2. Parameters of Q-leanring
eta = .628
gma = .9
epis = 5000
rev_list = [] # rewards per episode calculate
# 3. Q-learning Algorithm
for i in range(epis):
# Reset environment
s = env.reset()
rAll = 0
d = False
j = 0
#The Q-Table learning algorithm
while j < 99:
env.render()
j+=1
# Choose action from Q table
a = np.argmax(Q[s,:] + np.random.randn(1,env.action_space.n)*(1./(i+1)))
#Get new state & reward from environment
s1,r,d,_ = env.step(a)
#Update Q-Table with new knowledge
Q[s,a] = Q[s,a] + eta*(r + gma*np.max(Q[s1,:]) - Q[s,a])
rAll += r
s = s1
if d == True:
break
rev_list.append(rAll)
env.render()
print "Reward Sum on all episodes " + str(sum(rev_list)/epis)
print "Final Values Q-Table"
print Q
如果您对通过环境找到解决方案的Agent模拟感兴趣,请编写此Python代码段而不是Q-learning算法。
Frozen Lake Environment的可视化及以下Python代码用于模拟
# Reset environment s = env.reset() d = False # The Q-Table learning algorithm while d != True: env.render() # Choose action from Q table a = np.argmax(Q[s,:] + np.random.randn(1,env.action_space.n)*(1./(i+1))) #Get new state & reward from environment s1,r,d,_ = env.step(a) #Update Q-Table with new knowledge Q[s,a] = Q[s,a] + eta*(r + gma*np.max(Q[s1,:]) - Q[s,a]) s = s1 # Code will stop at d == True, and render one state before it
但是请记住,即使使用通用接口,不同环境的代码复杂度也会不同。在上面的环境中,我们只有一个简单的64状态环境,只有很少的操作需要处理。我们可以很容易地将它们存储在二维数组中进行奖励映射。现在,让我们考虑更复杂的环境案例,比如Atari envs,并考虑所需的方法。
env = gym.make("Breakout-v0")
env.action_space.n
Out[...]: 4
env.env.get_action_meanings()
Out[...]: ['NOOP', 'FIRE', 'RIGHT', 'LEFT']
env.observation_space
Out[...]: Box(210, 160, 3)
observation_space需要用210x160x3张量来表示,这使得我们的Q表变得更加复杂。此外,每个动作在k帧的持续时间内重复执行,其中k从{2,3,4}均匀地采样。RGB通道中有33,600像素,值范围为0-255,环境显然已经变得过于复杂,简单的QL方法在这里无法使用。可以通过卷积神经网络(CNN)进行深度学习来解决此问题的方法。
结论
现在,通过上面的教程,您可以获得有关gym的基本知识以及开始使用它所需的一切。它也兼容TensorFlow。





