
出品|开源中国
开源并行训练系统 ColossalAI 表示,已低成本复现了一个 ChatGPT 训练的基本流程,包括 stage 1 预训练、stage 2 的奖励模型的训练,以及最为复杂的 stage 3 强化学习训练。具体亮点包括:
一个开源完整的基于 PyTorch 的 ChatGPT 等效实现流程,涵盖所有 3 个阶段,可以帮助你构建基于预训练模型的 ChatGPT 式服务。
提供了一个迷你演示训练过程供用户试玩,它只需要 1.62GB 的 GPU 显存,并且可能在单个消费级 GPU 上实现,单 GPU 模型容量最多提升 10.3 倍。
与原始 PyTorch 相比,单机训练过程最高可提升 7.73 倍,单 GPU 推理速度提升 1.42 倍,仅需一行代码即可调用。
在微调任务上,同样仅需一行代码,就可以在保持足够高的运行速度的情况下,最多提升单 GPU 的微调模型容量 3.7 倍。
提供多个版本的单 GPU 规模、单节点多 GPU 规模和原始 1750 亿参数规模。还支持从 Hugging Face 导入 OPT、GPT-3、BLOOM 和许多其他预训练的大型模型到你的训练过程中。
ColossalAI 是一个具有高效并行化技术的综合大规模模型训练系统;旨在无缝整合不同的并行化技术范式,包括数据并行、管道并行、多张量并行和序列并行。其声称已通过 ZeRO、Gemini、Chunk-based 内存管理等技术,极大地降低 ChatGPT 训练的显存开销;仅需一半硬件资源即可启动 1750 亿参数模型训练(从 64 卡到 32 卡),显著降低应用成本。
若使用上述相同硬件资源,Colossal-AI 则能以更短时间进行训练,节省训练成本,加速产品迭代。为了让更多开发者体验复现 ChatGPT 模型,除 1750 亿参数版本外,Colossal-AI 还提供高效的单 GPU、单机 4/8 GPU 的类 ChatGPT 版本,以降低硬件限制。
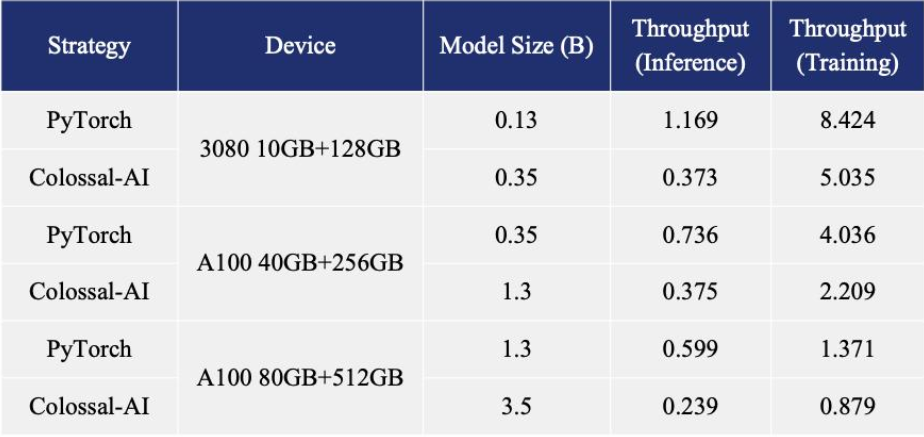
博客内容还指出,在单机多 GPU 服务器上,即便使用最高端的 A100 80GB 显卡,由于 ChatGPT 的复杂性和内存碎片,PyTorch 最大仅能启动基于 GPT-L(774M)这样的小模型的 ChatGPT。用 PyTorch 原生的 DistributedDataParallel (DDP) 进行多卡并行扩展至 4 卡或 8 卡,性能提升有限。
Colossal-AI 不仅在单 GPU 速度上训练和推理优势明显,随着并行规模扩大还可进一步提升,最高可提升单机训练速度 7.73 倍,单 GPU 推理速度 1.42 倍;并且能够继续扩展至大规模并行,显著降低 ChatGPT 复现成本。
为了最大限度地降低培训成本和易用性,Colossal-AI 提供了可以在单个 GPU 上试用的 ChatGPT 培训流程。与在 14999 美元的 A100 80GB 上最多只能启动 7.8 亿个参数模型的 PyTorch 相比,Colossal-AI 将单个 GPU 的容量提升了 10.3 倍,达到 80 亿个参数。对于基于 1.2 亿参数的小模型的 ChatGPT 训练,至少需要 1.62GB 的 GPU 内存,任意单个消费级 GPU 都可以满足。
此外,Colossal-AI 还在致力于降低基于预训练大型模型的微调任务的成本。以 ChatGPT 可选的开源基础模型 OPT 为例,Colossal-AI 能够在单 GPU 上将微调模型的容量提高到 PyTorch 的 3.7 倍,同时保持高速运行。
Colossal-AI 为 Hugging Face 社区的 GPT、OPT 和 BLOOM 等主流预训练模型,提供了开箱即用的 ChatGPT 复现代码。以 GPT 为例,仅需一行代码,指定使用 Colossal-AI 作为系统策略即可快速使用。
from chatgpt.nn import GPTActor, GPTCritic, RewardModelfrom chatgpt.trainer import PPOTrainerfrom chatgpt.trainer.strategies import ColossalAIStrategystrategy = ColossalAIStrategy(stage=3, placement_policy='cuda')with strategy.model_init_context(): actor = GPTActor().cuda() critic = GPTCritic().cuda() initial_model = deepcopy(actor).cuda() reward_model = RewardModel(deepcopy(critic.model)).cuda()trainer = PPOTrainer(strategy, actor, critic, reward_model, initial_model, ...)trainer.fit(prompts)





