
很多人在刚接触 stable-diffusion-webui 时,看着的英文tag 无从下手,看不懂,更不会写,于是就被劝退了。其实AI绘图也有捷径的,不会写tag ,但我们会抄啊,多看看别人怎么写的,抄多了自然就会写了。
强烈推荐:Civitai: AI艺术图片生成模型资源共享平台
想要 AI 绘图,不会写 tag ,就全靠它了。在C站里,提供了很多模型资源和 tag 可供免费下载,对初学者来说简直是天堂。你要做的是,找到一张你喜欢的图片,然后复现(抄)它。
区分模型类别:
注意图片左上角的文字,如果是 CHECKPOINT 说明这张图片用到的是大模型(或者是底模),可以理解为生成图片需要用到的基础模型。大模型一般为2-7G左右。
如果是 LORA 说明这张图片用到的是 lora 模型,lora 模型可以理解为滤镜,是对大模型的进一步修饰,以达到更加精细化的效果。lora 模型一般几十到一百兆左右。
下载模型
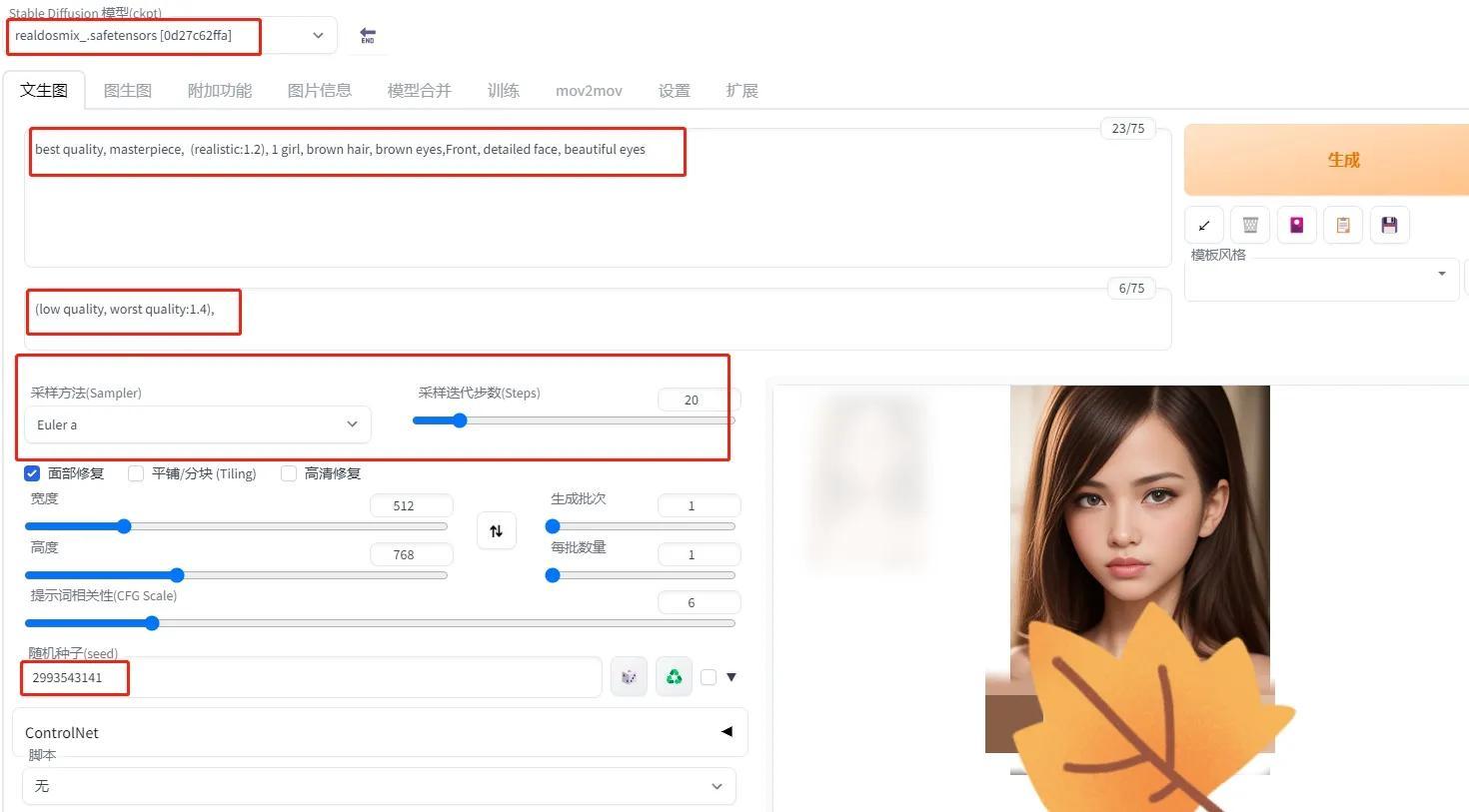
这次我们以CHECKPOINT模型为例,这个模型名字叫 RealDosMix,点击图片进入后,右边会一个模型下载按钮,这个模型1.99G,下载好后的模型,将其复制到 stable-diffusion-webui\models\Stable-diffusion 文件夹内即可。
这里顺便说一下,LORA 模型放置的路径为 stable-diffusion-webui\models\Lora
复制 TAG
再次点击图片,会发现这个图片所需要的正面 tag、负面 tag ,以及其他参数,有了它我们也可以生成这张图片了。
在 SD 工作台的左上角,选择 RealDosMix 模型,然后将对应的正、负面 tag 填好,再调整好对应的参数,特别注意种子数一定要一致,点击生成,便得到了和原图一致的图片了,是不是特别简单。
简单修改
如果还想自己发挥一下,可以手动对 tag 进行添加或修改,我在正向 tag 里添加了 “taut clothes,medium breasts, shirt, full body”,具体含义你们自己百度翻译吧,然后把种子数调为“-1”,意思为随机生成图片,于是得到了下面几张图片。

如果有不明白或者其他想知道的内容,欢迎在评论区留言。





