
编者按:1956年,人工智能(AI,Artificial Intelligence)的概念首次提出,迄今已逾六十载。60年来,AI历经了从爆发到寒冬、再到野蛮生长的历程,伴随着人机交互、机器学习等技术的提升,AI成为了技术时代的新趋势。
2022年,AI行业再度迎来新的节点,人工智能生成内容(AIGC,AI Generated Content)后来居上,以超出人们预期的速度成为科技革命历史上的重大事件。无论是“AI画师”DALL-E2,还是“万能陪聊”对话机器人ChatGPT,生成式AI正在迅速催生全新的科技革命系统、格局与生态。
时针转至2023年,由AIGC引发的热度不减反增,而全新的智能创作时代在带来深刻生产力变革的同时,也将进而改变人类的思想演进模式。就此,21世纪经济报道数字经济课题组策划了“逐浪AIGC”系列报道,多维解读AIGC带来的技术可能和商业图景。
21世纪经济报道记者骆轶琪 广州报道
“我们正处于AI的‘iPhone时刻’。”78分钟的GTC演讲过程中,NVIDIA(英伟达)创始人兼首席执行官黄仁勋提了三次这一观点。
正当一些行业人士感慨跑一次GPT4训练需要庞大的资金成本支持时,英伟达自己来炸场了。面向迄今历史上用户数量增长最快的应用ChatGPT,英伟达发布了包括硬件迭代和云服务一系列组合,核心目的之一,就是加速运算速度、极大降低成本。
(ChatGPT是迄今历史上用户数量增长最快的应用,图源:英伟达发布会现场展示)
黄仁勋表示,类似ChatGPT大型语言模型(LLM)的部署是一个重要的全新推理工作负载,为了支持这类模型推理,英伟达发布一款新GPU,是带有双GPU NVLink的H100 NVL。同时基于NVIDIA Hopper架构的H100配有一个Transformer引擎,是为处理驱动ChatGPT的类似模型,相比用于GPT3处理的HGX A100来看,配备四对H100和双GPU NVLink的标准服务器速度最高可达10倍。“H100可以将大型语言模型的处理成本降低一个数量级。”他续称。
为什么在AI变革进程中GPU尤为重要?这是源于AI大模型在训练时,对基础设施的要求是大规模并行计算,这也是GPU相比于其他类型计算芯片如CPU(串行运算为主)等的显著优势。当然计算的同时也需相应配套高速数据存储、光模块、通信等一系列能力。
其中对英伟达的诉求最为旺盛。今年2月份发布最新业绩时,黄仁勋就曾表示:“AI正处于一个拐点,从初创企业到大型企业,我们看到生成式AI的多功能性和能力让全球企业感受到开发和部署AI战略的急迫性。”这也成为彼时业绩交流中的核心关键词。
在3月21日深夜的演讲中,他再次提到这一点,并且指出,“生成式AI是一种新型计算机,一种我们可以用人类语言进行编程的计算机,与PC、互联网、移动设备和云类似,每个人都可以命令计算机来解决问题,现在每个人都可以是程序员。”
(黄仁勋认为生成式AI是一种新型计算机,图源:英伟达发布现场)
在英伟达和一众合作伙伴的推动下,关于前两天还在火热探讨的“GPT会取代哪些职业”这个话题,似乎也并不那么让人困扰了。
算力账单
先看看这次炸场之前,用英伟达GPU产品部署一次GPT训练需要的实力。
CINNO Research半导体事业部总经理Elvis Hsu对21世纪经济报道记者分析,2023年是ChatGPT元年,构成人工智能的三大要素包括:数据、算法、算力,其中尤以芯片的算力是最重要一环。由于模型训练参数量的使用与算力成正相关,ChatGPT持续升级进程中,其参数使用量增长幅度不可谓不大,投入资金自然水涨船高。每一次模型训练所需的资金从数百万到千万美金不等,随着硬件和云计算服务的价格不断变化。
(GPT3论文概要,其参数使用量为1750亿,图源:Open AI官网公布)
“英伟达GPU A100每片约1万美金,除了投入的人力成本、网络宽带成本和数据储存之外,最重要的就负责算力的芯片成本支出,如何降低成本与功耗便成为未来发展AI芯片的重要课题。”他总结道。
之所以现阶段较难以准确预估训练背后的整体成本,是因为OpenAI在最新关于GPT4的论文中,明确提到出于竞争和安全等因素考虑,相关模型具体信息选择并不公开。由此业内目前对于GPT4背后的具体训练参数量并没有十分统一的测算结果,有认为是万亿级别,也有认为是百万亿级别。
(GPT4论文中并未公布训练量和模型架构等信息,图源:Open AI官网公布)
当然其中核心的成本考虑避不开GPU。IDC亚太区研究总监郭俊丽也对记者指出,算力是AI模型的能源,将最直接受益于人工智能的普及,也成为GPT4最重头的成本投入。同时,想要训练类似ChatGPT的大模型,除了芯片投入,还包括服务器、通信等基础设施。
考虑到不同时期英伟达GPU相关芯片产品的价格有所波动,背后所需的软件能力配置也有不同,造成其具体算力账本一般是一个大概的构想。
郭俊丽进一步指出,基于参数数量和token数量估算,GPT-3训练一次的成本约为140万美元;对于一些更大的LLM模型,比如拥有2800亿参数的Gopher和拥有5400亿参数的PaLM,采用同样的公式可得出,训练成本介于200万-1200万美元之间。
“以GPT-3.5为模型的ChatGPT模型,都要460万-500万美元。据OpenAI测算,自2012年以来,全球头部AI模型训练算力需求每3-4个月翻一番,每年头部训练模型所需算力增长幅度高达10倍。以此来推测,GPT4的运行成本将大幅高于GPT3.5。对于想要切入该赛道的企业来说,资金成本将会是一个门槛。”她得出结论。
TrendForce集邦咨询分析师曾伯楷综合对记者分析,从GhatGPT开发历程看,其在发展初期约采用1万颗NVIDIA A100 GPU(以下简称“A100”),经扩充升级后,运算资源估计已等同2万颗A100 GPU。目前ChatGPT并未实时更新文本数据,所有信息只涵盖至2021年,GPT4也是如此,一旦ChatGPT开始更新数据、为用户提供更长篇幅的生成内容,且用户数持续成长至1.5亿户以上,则运算资源可能得再扩充1倍,届时或许要增加1.5-2万颗A100 GPU才能满足算力需求。
“在此基础上推估,大约到2025年,每一款类似ChatGPT的超大型AI聊天机器人算力需求,约等同2.5-4万颗A100 GPU;若以每张A100 GPU显卡价值2万美元估算,总体GPU建置成本将落在5-8亿美元。”他补充道,叠加考虑到GPT4相比前代升级为多模态(multimodal)模型,能分析文字输入、也能进行图片解读,估计超大型AI聊天机器人的整体运算资源可能须再扩张5%左右。
从这个角度看,若是从无到有打造、训练类似GPT4的超大型AI聊天机器人,并且能够向全球用户提供流畅的生成内容服务,其构建成本必然比ChatGPT 3.5高出一倍。“至于日后成本是否呈现倍数成长,仍取决于三方面:一是大型语言模型的发展趋势,二是全球AI聊天机器人应用的使用情况,三是硬件资源分配优化方案的进展。”曾伯楷续称。
在当前半导体行业仍没有完全走出周期低点的过程中,AIGC对算力的需求无疑对英伟达的业绩带来较大支撑,但是对于其他芯片类型来说可能影响不会那么显著。
Elvis对记者指出,由于在执行计算期间需要大容量、高速的存储支持,预计高阶的内存芯片需求将会扩大,短期对于低迷的市场助长有限,是因为普及度不够,但有利于长期高性能高带宽内存HBM及高容量服务器DRAM存储器市场的增长,这对于训练成本的下降稍有助益。
计算生态
基于前面的计算和判断,行业一种观点认为,当前要部署相关AI大模型需要较大的资金实力和能力魄力。由此引发进一步思考:难道AI大模型就只能以如此高成本运行,一般企业根本无力应对吗?
这在3月21日的发布中黄仁勋已经给出了答案:GPU本身已经在快速通过硬件产品和软件生态服务等综合方式,帮助更多AI大模型成长。
GTC期间,英伟达在硬件方面针对大型语言模型发布了新款GPU——带有双GPU NVLink的H100 NVL,配套Transformer引擎,相比前代用于处理GPT3的HGX A100相比,配置四对H100和双GPU NVLink标准服务器的速度最高可达10倍,由此将大型语言模型的处理成本降低一个数量级。
(新版本GPU产品将令AI大模型处理成本降低一个数量级,图源:英伟达发布现场)
同步发布的还有Grace Hopper超级芯片,黄仁勋指出这是处理超大型数据集的理想选择,比如可以用于推荐系统的AI数据库和大型语言模型。据介绍,通过900GB/s高速芯片对芯片的接口,英伟达Grace Hopper超级芯片可以连接Grace CPU和Hopper GPU。
为了加速生成式AI的工作,在软件方面英伟达还发布了AI Foundations云服务系列,为需要构建、完善、运行自定义大型语言模型和生成式AI的客户提供服务。
倘若换个角度,在目前全球GPU霸主英伟达之外,是否还能找到其他选择,用以探索更低成本,或者其他计算能力构成的基础设施模型?比如CPU+FPGA/ASIC,亦或是正在冉冉升起的技术路线Chiplet芯粒?
对此Elvis对记者分析,从技术架构来看,AI芯片一般可以分为GPU、FPGA、ASIC和类脑芯片四大类。GPU的关键性能是矩形并行计算,无论性能还是内存带宽均远大于同代的CPU,因此很适合人工智能发展。CPU因算力有限,但若能搭配开发周期短且灵活运用度高的FPGA,或是小型化、低功耗及高性能的ASIC,甚至是芯粒Chiplet的低成本优势,也不失为良策。
曾伯楷则指出,AI模型训练当前仍多以GPU为主,是因AI芯片功能各异、取向不同。比如GPU专为同时处理多重任务而设计,诸如处理图形、图像相关运算工作。由于该芯片采用统一渲染架构,能在算法尚未定型的领域中使用,故通用性程度较高、商业化较成熟。
相比之下,FPGA、ASIC虽然各有优缺点,但其历史积累不够。“即便CPU加FPGA或ASIC的单颗成本存在低于GPU的可能,但考虑芯片开发时间、通用性程度、算法成熟度等因素,仍以GPU为主流采用芯片。”他分析道。
这里需要补充的是,英伟达之所以能够制霸GPU领域多年,除了其很早就选择了这一路线外,也由此搭建了十分丰富的CUDA生态,这是GPU领域后来者尤为缺失的一项竞争力。
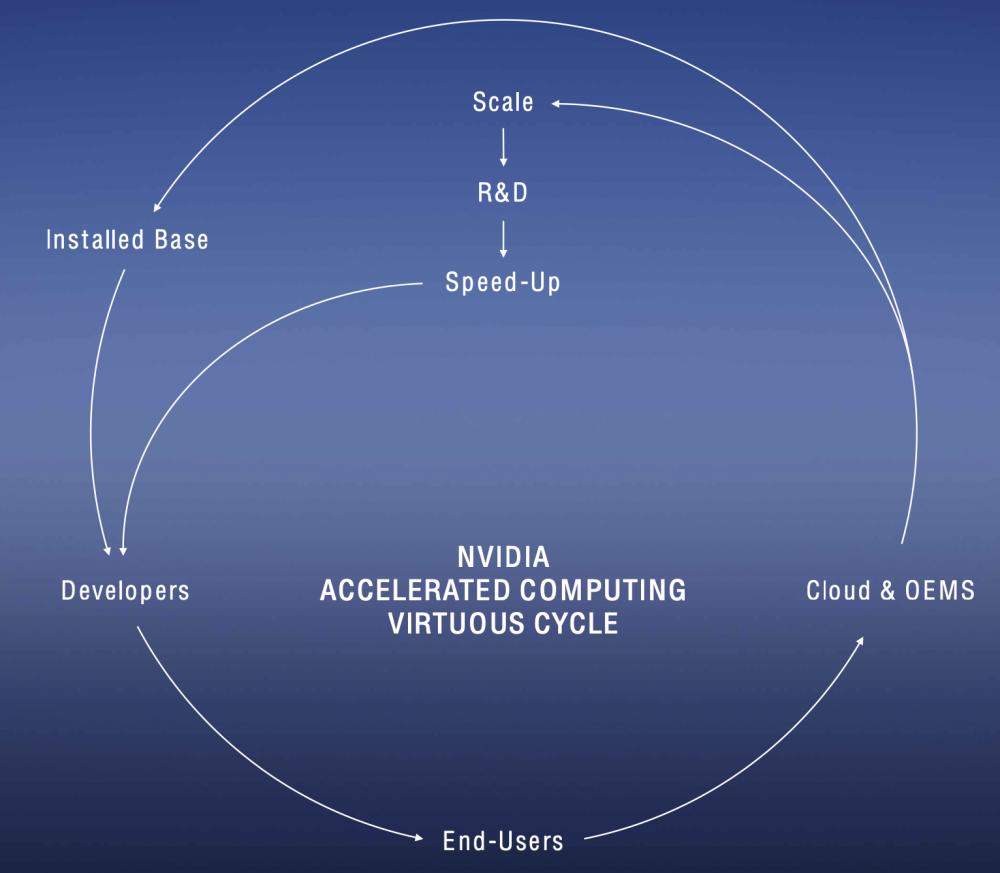
(黄仁勋称英伟达构建了加速计算的良性循环,图源:英伟达发布现场)
大模型未来
一方面底层基础设施随着软硬件持续迭代升级,匹配应用场景增加,成本已经快速下降;另一方面随着微软发布Microsoft 365 Copilot,应用到了GPT4的能力这一举动,则体现出应用端对于大模型的思考。
正式推出市场几个月至今,GPT本身就在演绎着关于商业化的探索以及实战训练的迭代。作为一项尤为强悍的智能工具,距离“我们都可以是程序员”这件事,还有多远?
郭俊丽对记者分析,相比ChatGPT之前版本,GPT4具备四大优点:更可靠、更有创造力,可以理解并处理指令的微妙之处;具备更高智能,在学术和专业考试中表现接近人类最好水平;接受图文类模特输入,可将应用范围拓展至机器人、智能驾驶等领域;利用模型调试、工程补丁、众包测评等方式减少谬误性显示,解决体验痛点。
综合这些都显示出AI大模型未来将对各种行业带来的模式重塑。本质上从训练成本到应用成本的双双下滑,将有望更快让我们真正拥抱AI大时代,包括其将进一步对工业、医疗等各行各业的提升。
GPT本身正在积极向外拥抱。2月,OpenAI 推出ChatGPT的付费订阅版ChatGPT Plus,提供比免费版更快速的服务以及新功能优先试用权,月费20美元。
3月初,官方再度宣布开放API应用程序接口,允许第三方开发者通过API将ChatGPT集成至他们的应用程序和服务中。按照每一千个Tokens/0.002美元收费,相比此前的GPT3,费用下降90%。
IDC中国研究总监卢言霞对21世纪经济报道记者分析,“个人认为,降低定价才能提高该产品的用量,如此也能让算法模型快速迭代。用量起来反哺模型,该产品的准确度会越来越高。”
她进一步指出,一般来说,AI大模型的变现有3种路线:卖算力,大模型用户自己训练自己部署;卖模型与算力高度结合,软硬一体优化方案;模型即服务,就是开放API。
“目前来看Open AI采用该两种模式面向的对象不同。Plus订阅可能倾向于面向个人,后续开放API则是面向企业级客户。由于面向的对象不一样,就谈不上对比哪种方式更容易变现。”她续称。
随着核心且高昂的算力基础设施已经在积极提速降本、拥抱各行各业伙伴,我们距离黄仁勋提出的畅想似乎又接近了一些。
更多内容请下载21财经APP





